你可以使用
dplyr::percent_rank() 实现基于百分位数的排名。然而,这与基于累积分布函数确定排名有所不同
dplyr::cume_dist() (小于或等于当前排名的所有值的比例)。
可重现的示例:
set.seed(1)
df <- data.frame(val = rnorm(n = 1000000, mean = 50, sd = 20))
展示percent_rank()与cume_dist()的不同之处,并且cume_dist()与ecdf(x)(x)相同:
library(tidyverse)
head(df) %>%
mutate(pr = percent_rank(val),
cd = ecdf(val)(val),
cd2 = cume_dist(val))
val pr cd cd2
1 37.47092 0.4 0.5000000 0.5000000
2 53.67287 0.6 0.6666667 0.6666667
3 33.28743 0.0 0.1666667 0.1666667
4 81.90562 1.0 1.0000000 1.0000000
5 56.59016 0.8 0.8333333 0.8333333
6 33.59063 0.2 0.3333333 0.3333333
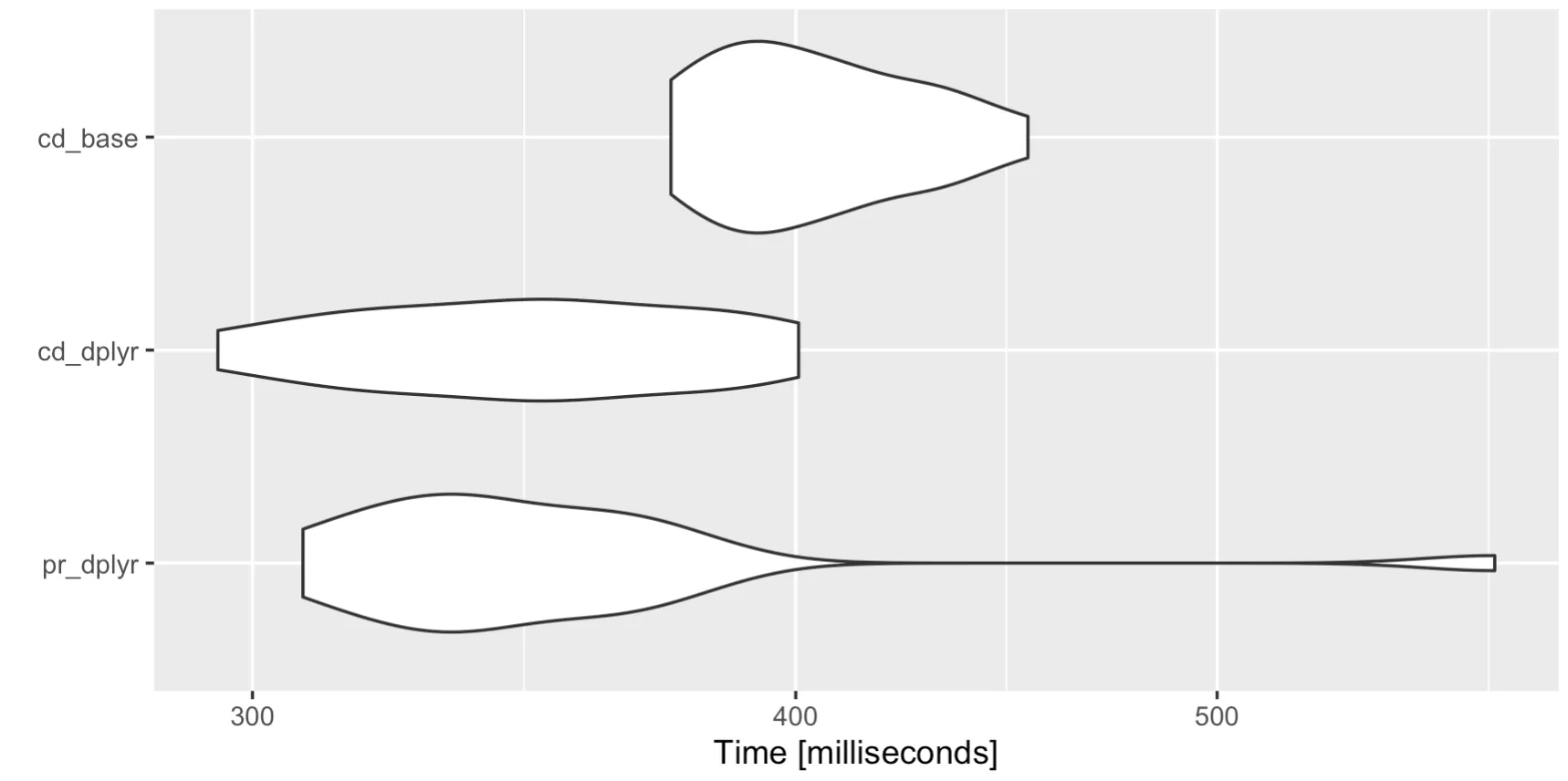
这个示例数据集的每种方法速度大致相似,没有超过2倍的因素:
library(microbenchmark)
mbm <- microbenchmark(
pr_dplyr = mutate(df, pr = percent_rank(val)),
cd_dplyr = mutate(df, pr = percent_rank(val)),
cd_base = mutate(df, pr = ecdf(val)(val)),
times = 20
)
autoplot(mbm)