我正在处理小样本数据:
>dput(dat.demand2050.unique)
c(79, 56, 69, 61, 53, 73, 72, 86, 75, 68, 74.2, 80, 65.6, 60, 54)
所对应的密度分布如下图所示:
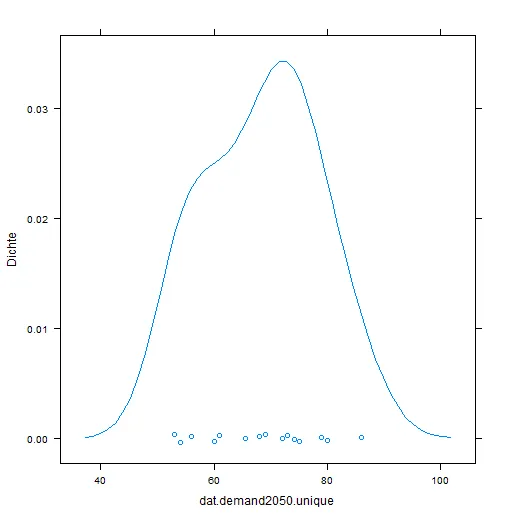
我知道这些值来自于两个不同的区间 - 低和高,并且假设底层过程服从正态分布,我使用了 mixtools 包来拟合一个双峰分布:
set.seed(99)
dat.demand2050.mixmdl <- normalmixEM(dat.demand2050.unique, lambda=c(0.3,0.7), mu=c(60,70), k=2)
这使我得到了以下结果:
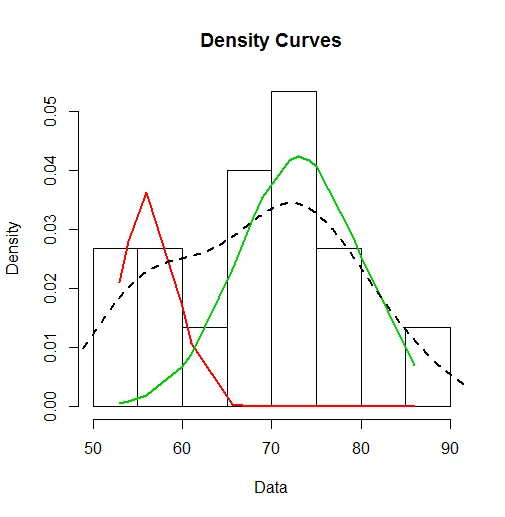
(实线为拟合曲线,虚线为原始密度)。
# get the parameters of the mixture
dat.demand2050.mixmdl.prop <- dat.demand2050.mixmdl$lambda #mix proportions
dat.demand2050.mixmdl.means <- dat.demand2050.mixmdl$mu #modal means
dat.demand2050.mixmdl.dev <- dat.demand2050.mixmdl$sigma #modal std dev
混合参数为:
>dat.demand2050.mixmdl.prop #mix proportions
[1] 0.2783939 0.7216061
>dat.demand2050.mixmdl.means #modal means
[1] 56.21150 73.08389
>dat.demand2050.mixmdl.dev #modal std dev
[1] 3.098292 6.413906
我有以下问题:
- 为了生成一个接近真实分布的新值集合,我的方法正确吗?还是有更好的流程?
- 如果我的方法正确,如何使用这个结果来生成一组符合该混合分布的随机值?
sample()进行自助取样,但必须回到我的笔记中,看看为什么我没有采取这种方法...也许这部分讨论应该转到 CrossValidated 上进行。 - avg