我认为更重要的是在寻找个人需求的解决方案时理解化妆品需求。 在我们处理的数据非常庞大时,我们必须选择方法,否则不会花费太多。对于小数据集,可以使用以下任一方法。
PEP 469,
PEP 3106和
Views And Iterators Instead Of Lists中有很好的解释。
在Python 3中,只有一个名为items()的方法。它使用迭代器,因此速度快,并允许在编辑时遍历字典。请注意,方法iteritems()已从Python 3中删除。
可以查看Python3 Wiki
Built-In_Changes以获取更多详细信息。
arr = pandas.Series([1, 1, 1, 2, 2, 2, 3, 3])
$ for index, value in arr.items():
print(f"Index : {index}, Value : {value}")
Index : 0, Value : 1
Index : 1, Value : 1
Index : 2, Value : 1
Index : 3, Value : 2
Index : 4, Value : 2
Index : 5, Value : 2
Index : 6, Value : 3
Index : 7, Value : 3
$ for index, value in arr.iteritems():
print(f"Index : {index}, Value : {value}")
Index : 0, Value : 1
Index : 1, Value : 1
Index : 2, Value : 1
Index : 3, Value : 2
Index : 4, Value : 2
Index : 5, Value : 2
Index : 6, Value : 3
Index : 7, Value : 3
$ for _, value in arr.iteritems():
print(f"Index : {index}, Value : {value}")
Index : 7, Value : 1
Index : 7, Value : 1
Index : 7, Value : 1
Index : 7, Value : 2
Index : 7, Value : 2
Index : 7, Value : 2
Index : 7, Value : 3
Index : 7, Value : 3
$ for i, v in enumerate(arr):
print(f"Index : {i}, Value : {v}")
Index : 0, Value : 1
Index : 1, Value : 1
Index : 2, Value : 1
Index : 3, Value : 2
Index : 4, Value : 2
Index : 5, Value : 2
Index : 6, Value : 3
Index : 7, Value : 3
$ for value in arr:
print(value)
1
1
1
2
2
2
3
3
$ for value in arr.tolist():
print(value)
1
1
1
2
2
2
3
3
有一篇关于如何在Pandas中迭代行的好文章(How to iterate over rows in a DataFrame in Pandas),尽管它说的是df,但它解释了所有关于item(),iteritems()等的内容。
另一个很好的讨论是SO items & iteritems。
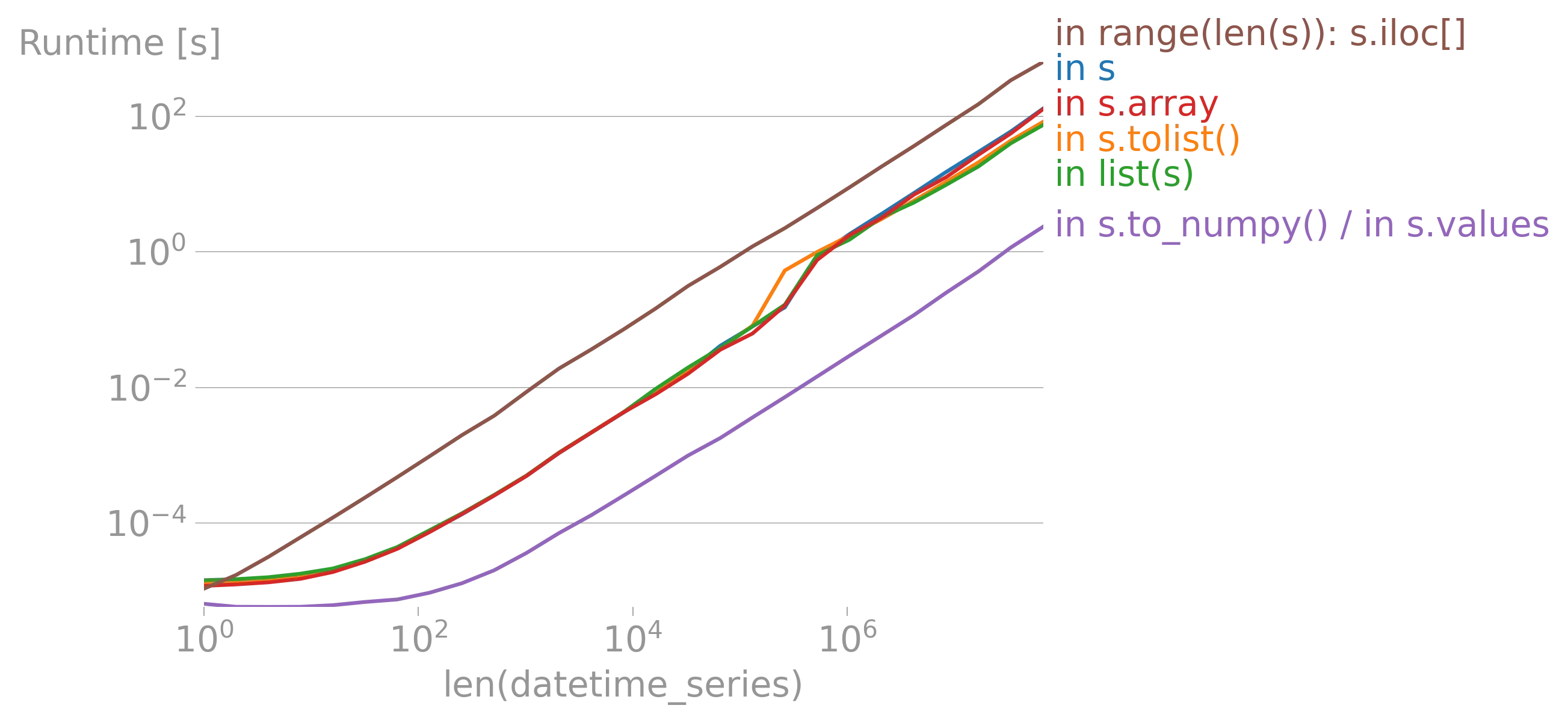
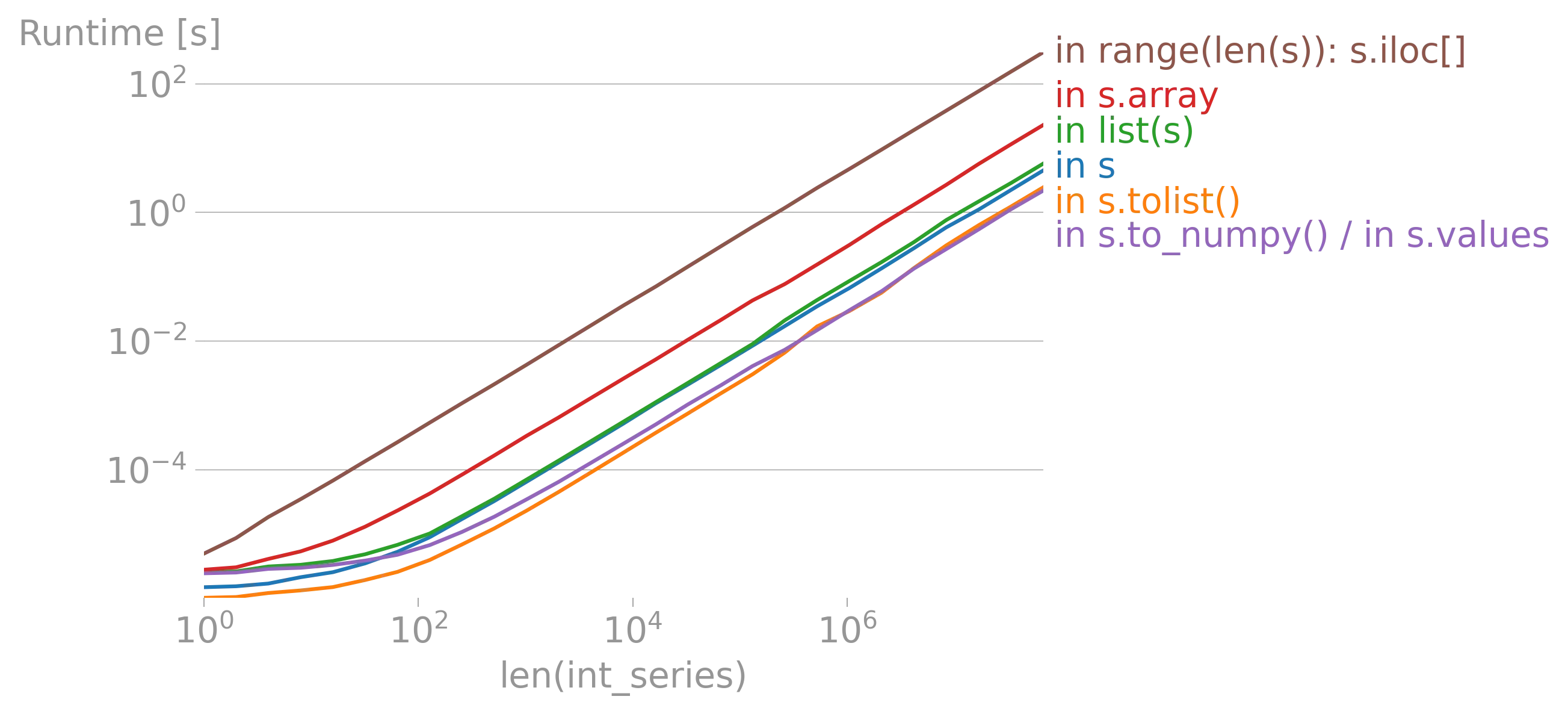
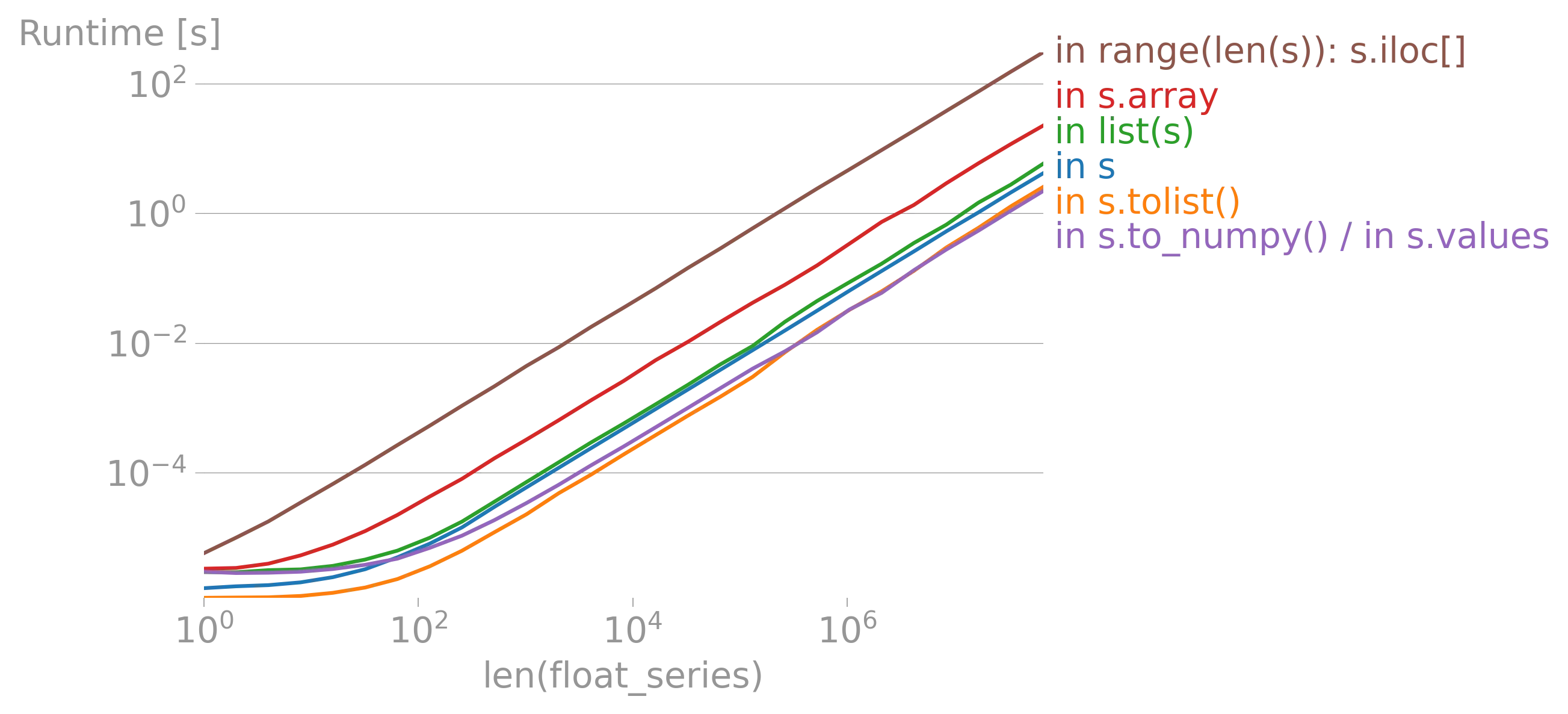
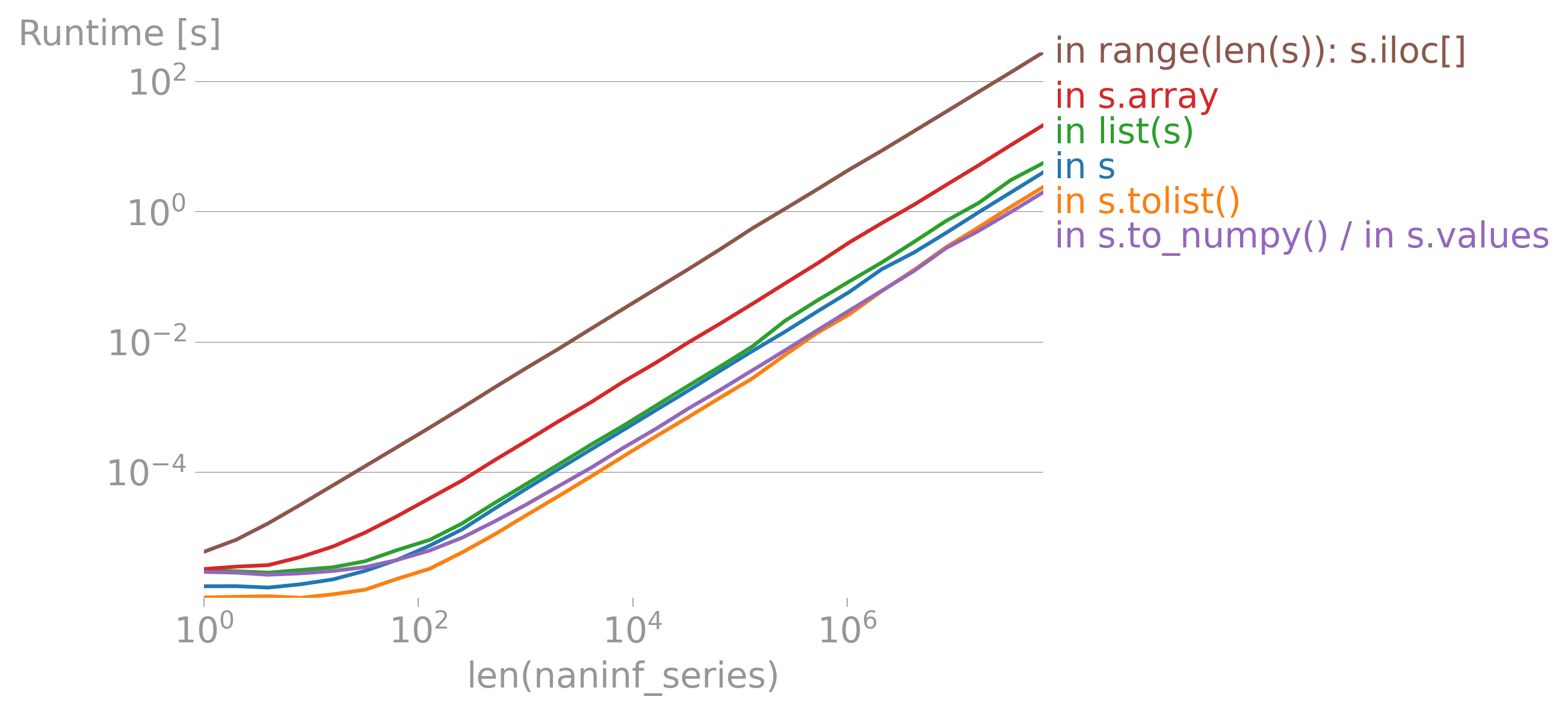
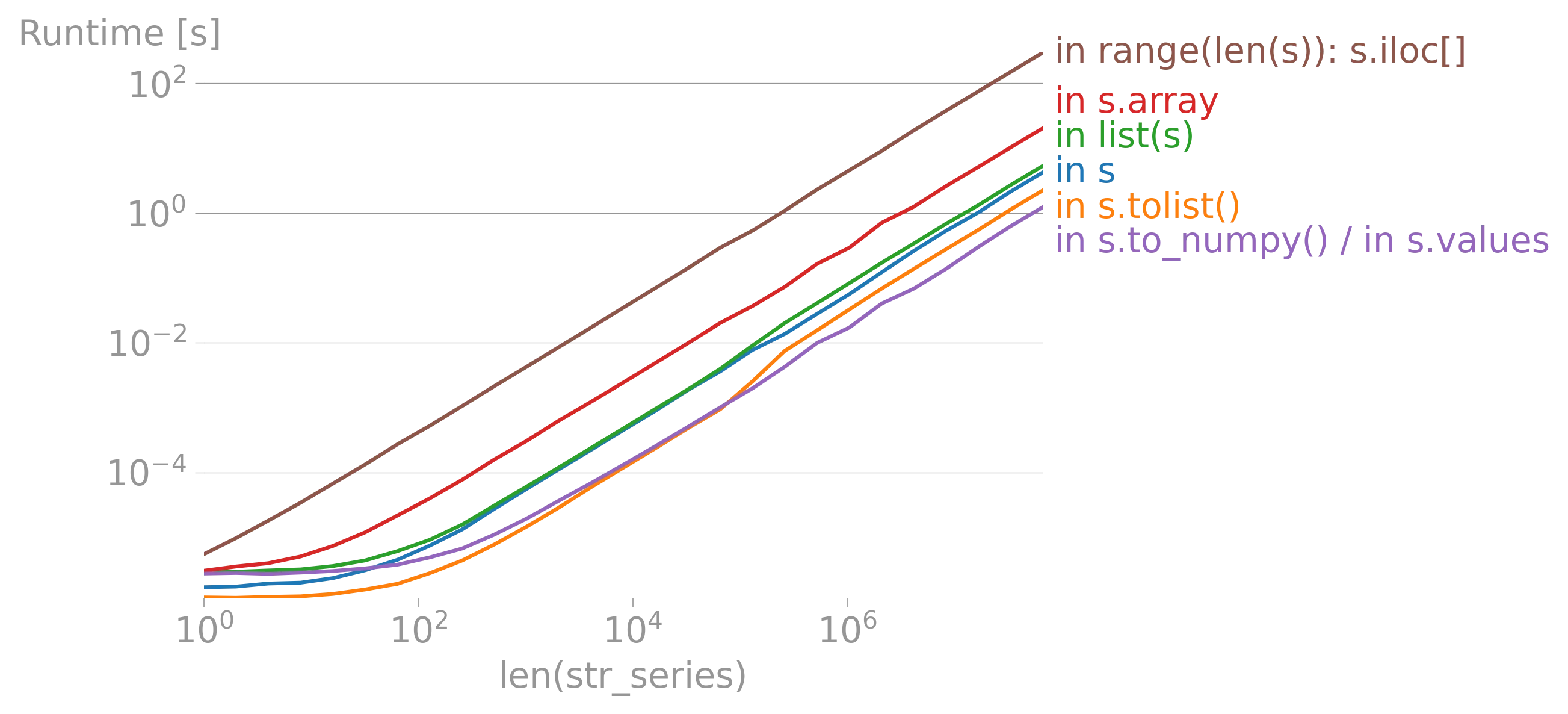
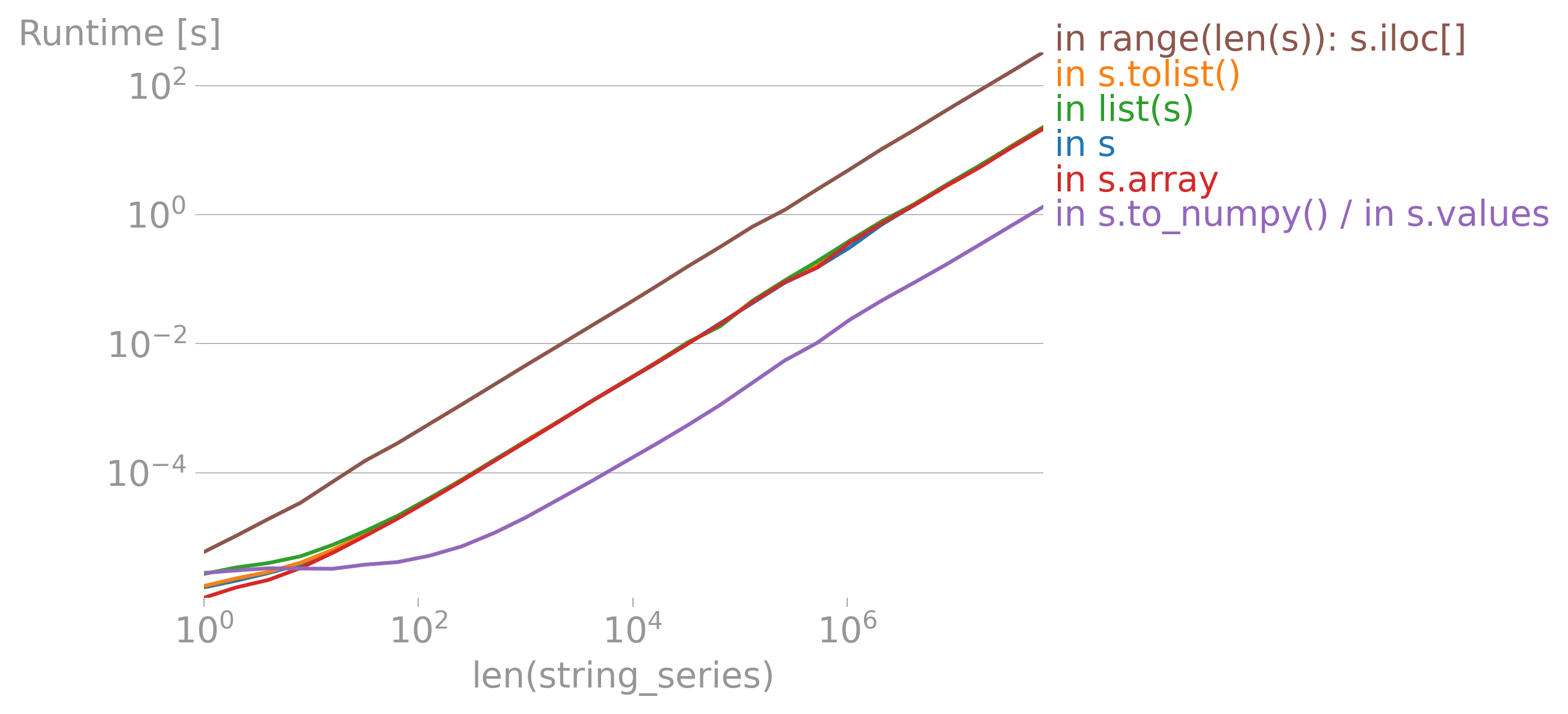
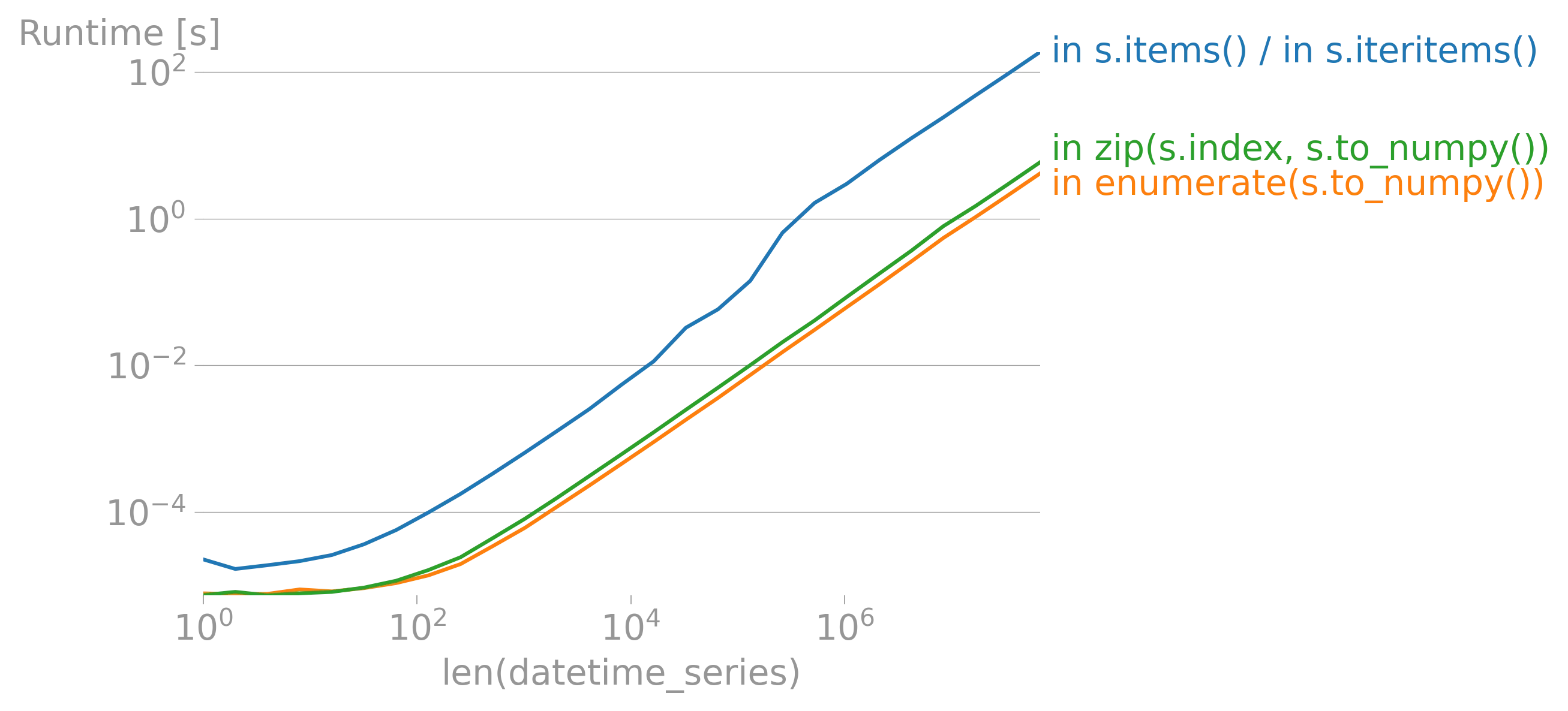
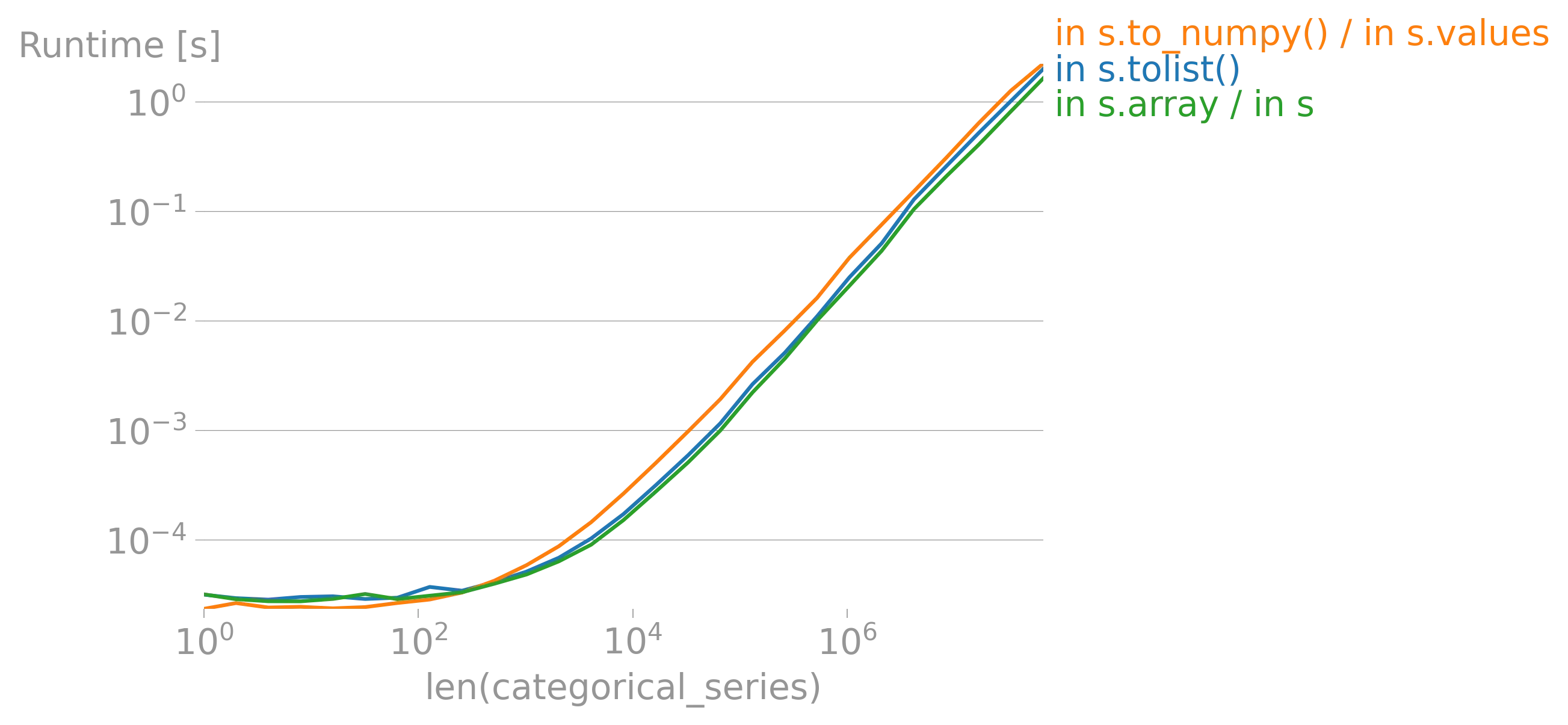
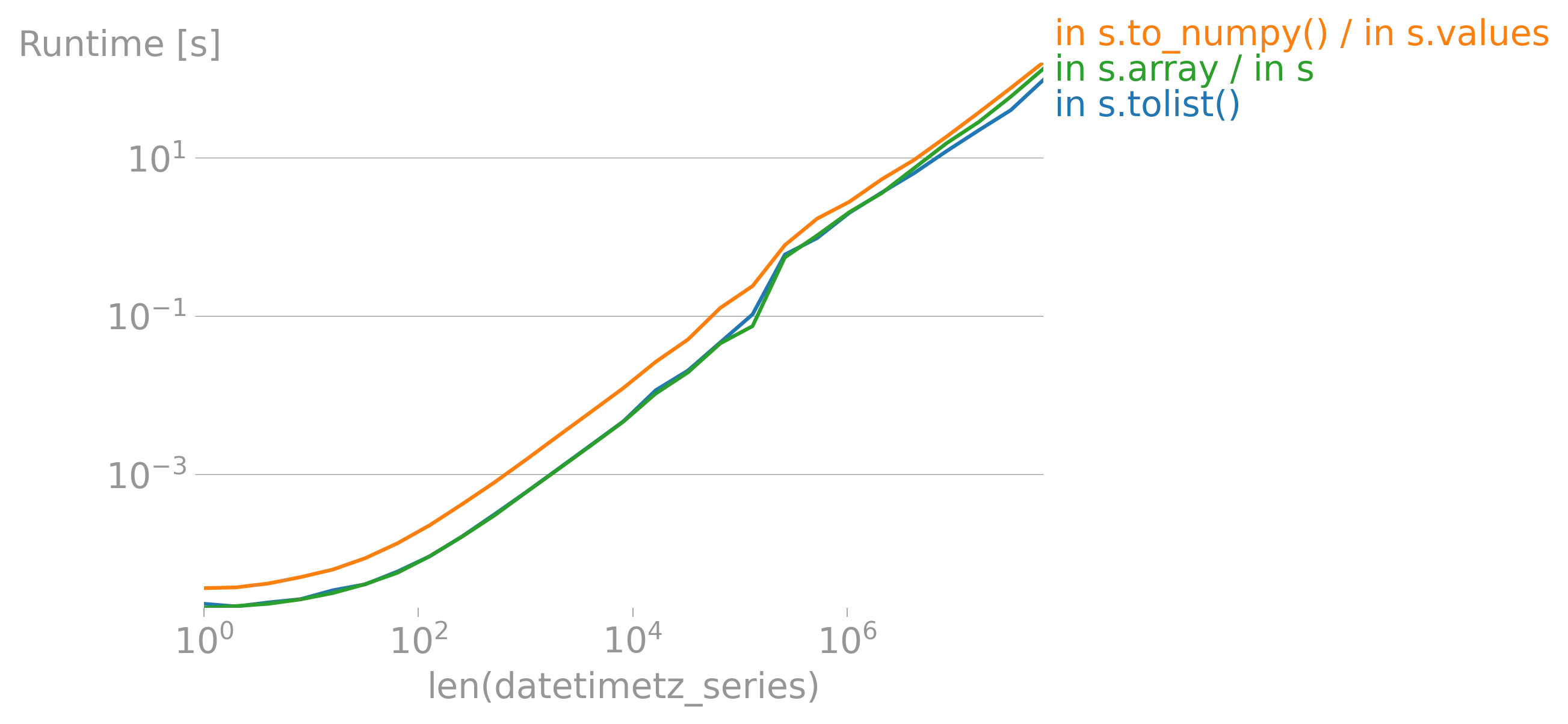
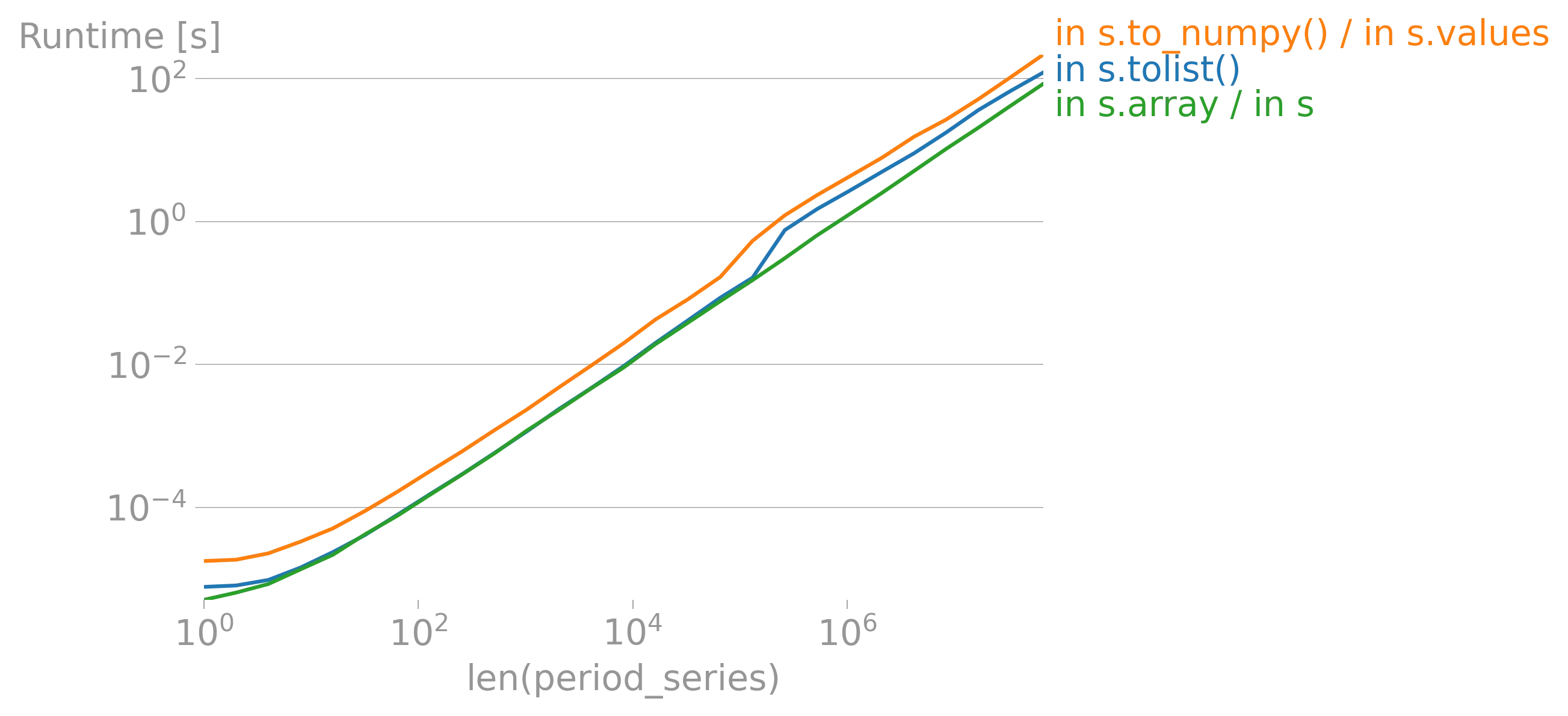
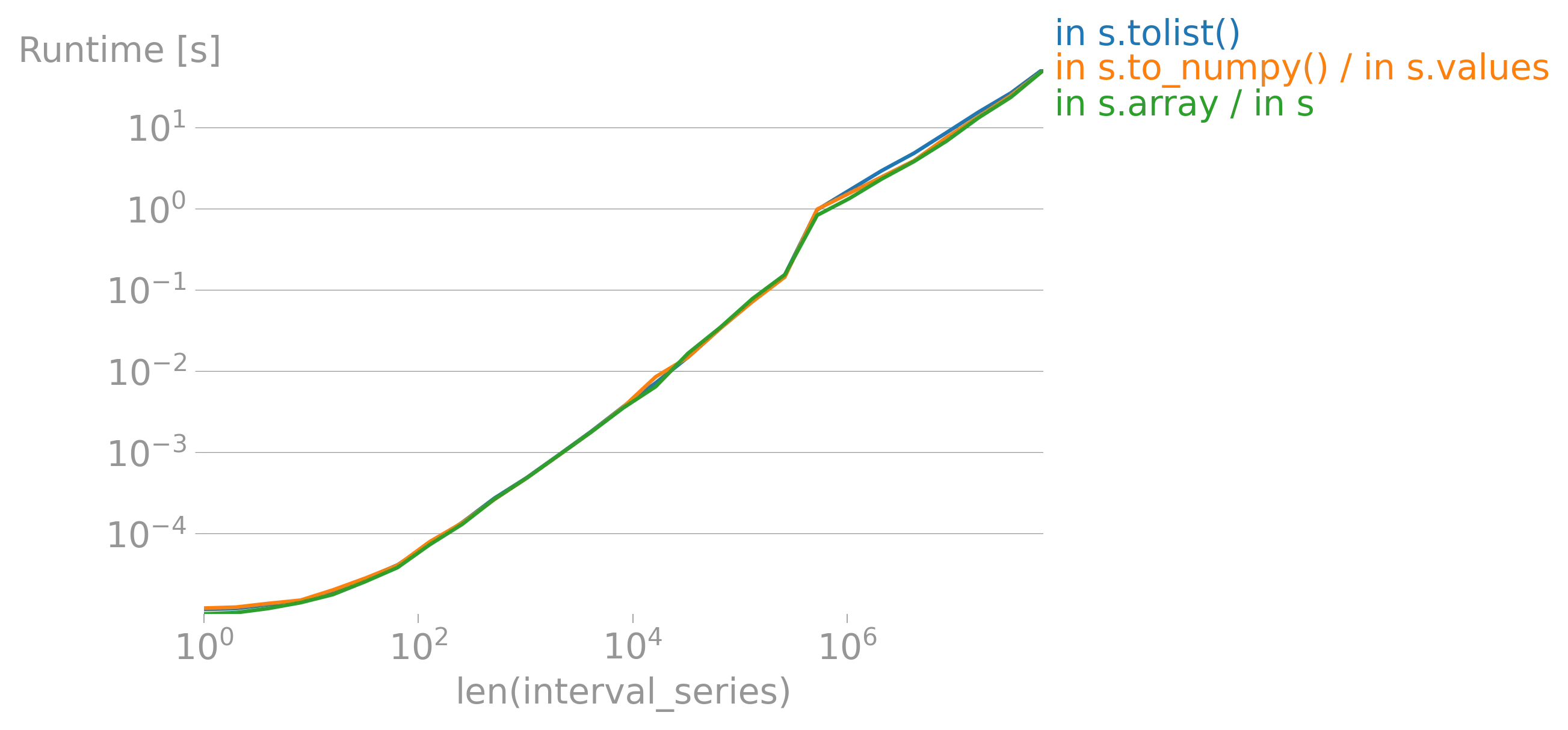
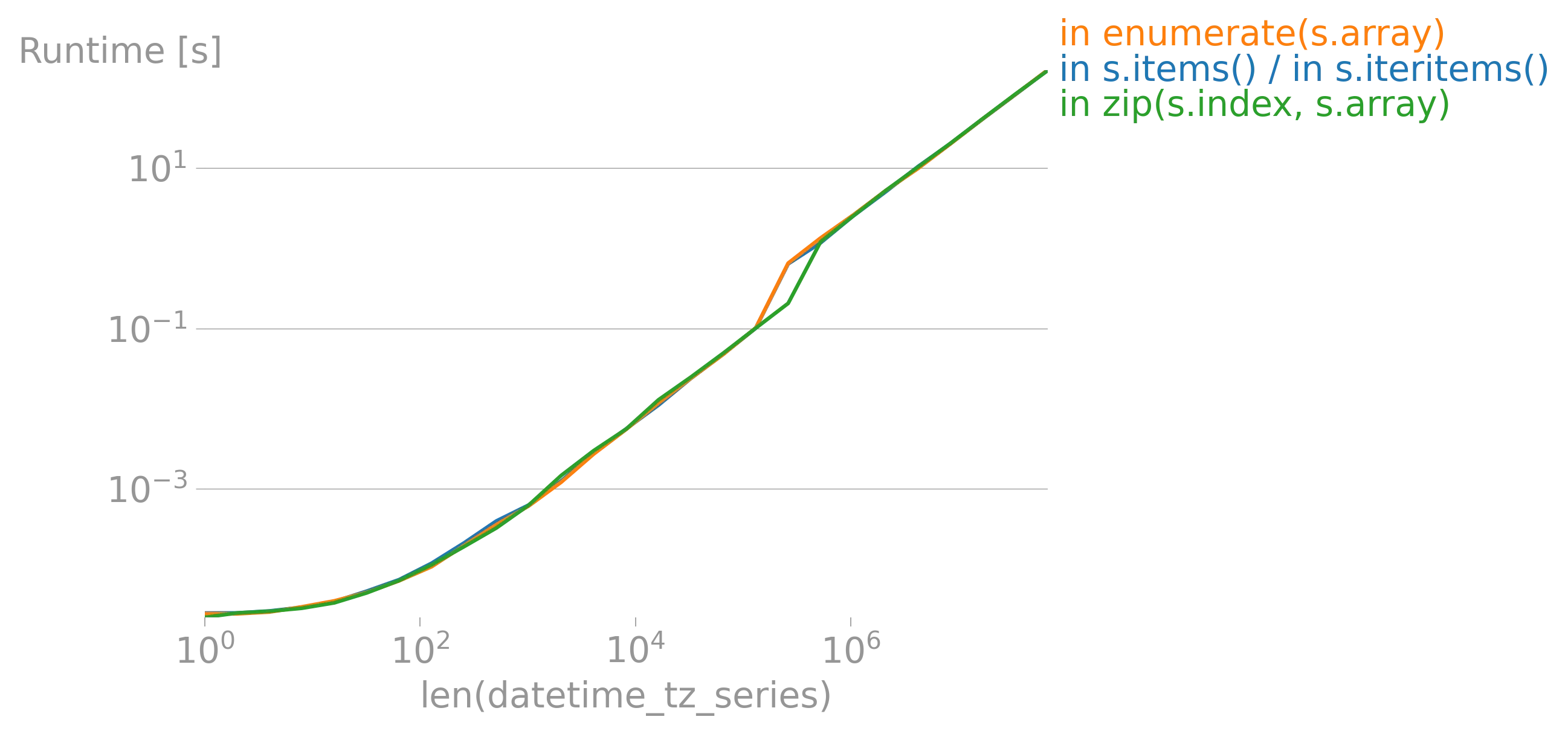
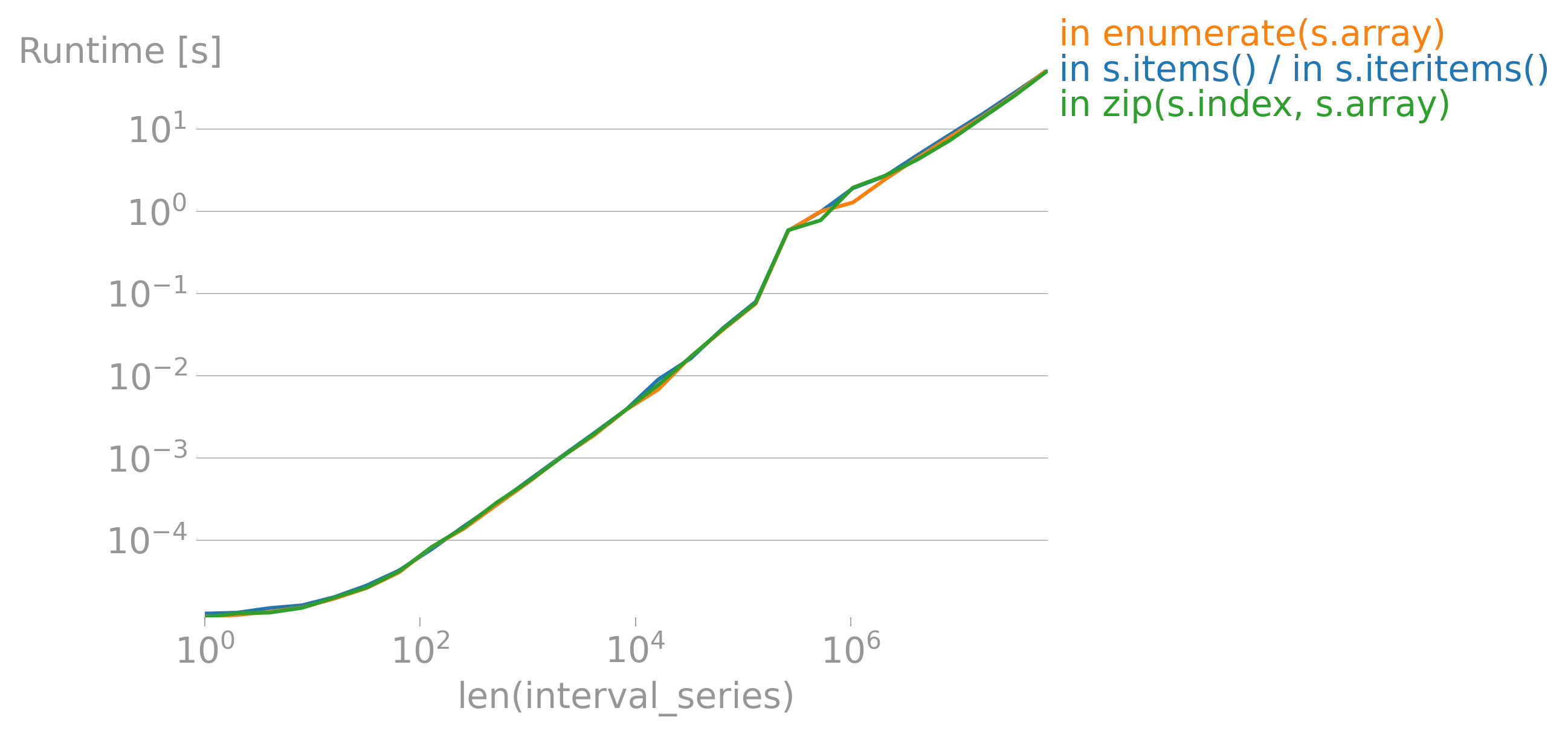
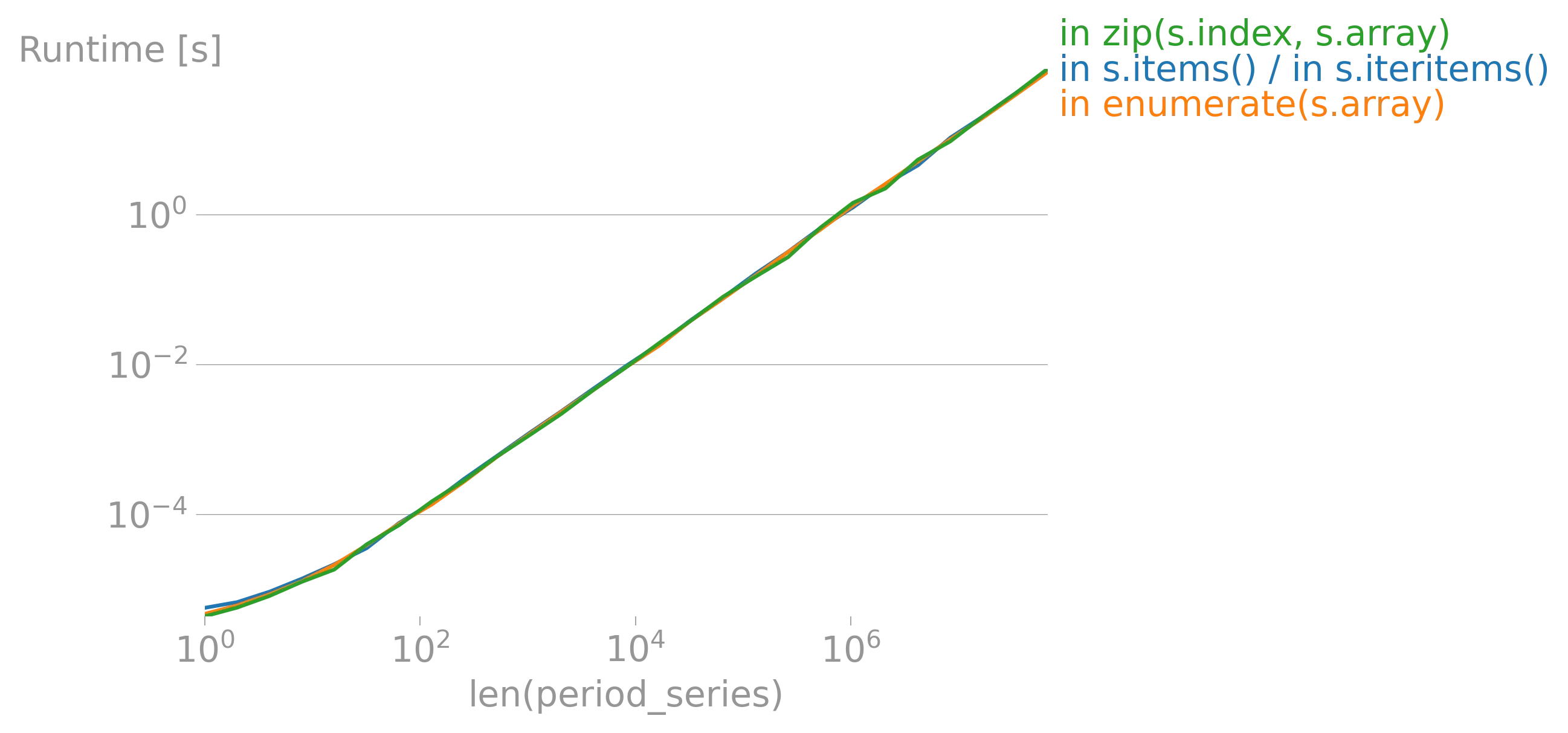
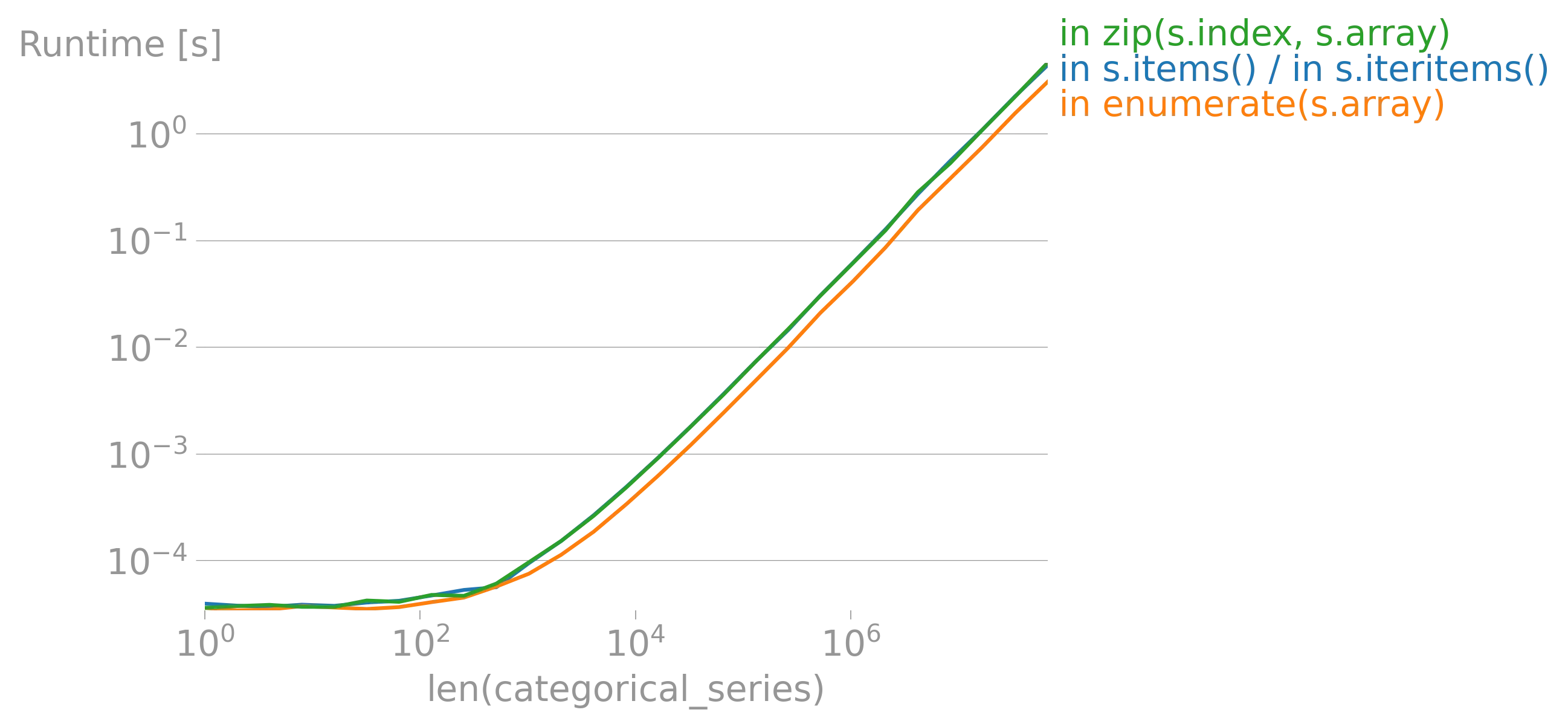
iterrows的论点(https://dev59.com/h2Qn5IYBdhLWcg3w5qlg#55557758)很可能也适用于Series。话虽如此,“最佳方式”是指什么?性能?简洁性?惯用性? - fsimonjetz.apply()、Series的加和乘等方法。你还没有展示出为什么print()不是一个使用案例。给我们展示一些使用案例吧。 - smci