我注意到了在遍历numpy数组时,直接遍历和通过tolist方法遍历之间有一个有意义的区别。请参见下面的时间表:
直接遍历
[i for i in np.arange(10000000)]
通过 tolist 遍历
[i for i in np.arange(10000000).tolist()]
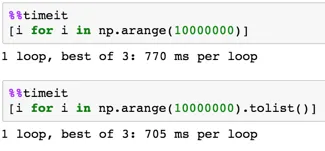
鉴于我已经发现了一种更快的方法。我想问还有什么可以使它更快吗?
遍历numpy数组最快的方法是什么?
我注意到了在遍历numpy数组时,直接遍历和通过tolist方法遍历之间有一个有意义的区别。请参见下面的时间表:
直接遍历
[i for i in np.arange(10000000)]
通过 tolist 遍历
[i for i in np.arange(10000000).tolist()]
鉴于我已经发现了一种更快的方法。我想问还有什么可以使它更快吗?
遍历numpy数组最快的方法是什么?
这实际上并不奇怪。让我们逐个检查方法,从最慢的开始。
[i for i in np.arange(10000000)]
这种方法要求Python逐个元素地访问存储在C内存范围中的NumPy数组,为每个元素分配一个Python对象并在列表中创建指向该对象的指针。每当您在C后端存储的NumPy数组和将其拉入纯Python之间进行数据传输时,都会产生一些开销。这种方法将这种成本乘以1000万次。
接下来:
[i for i in np.arange(10000000).tolist()]
.tolist()一次调用numpy C后端并将所有元素一次性分配到列表中。然后,您使用Python遍历该列表。list(np.arange(10000000))
这个基本上和上面做的一样,但是它创建了一个numpy原生类型对象的列表(例如np.int64)。使用list(np.arange(10000000))和np.arange(10000000).tolist()所需的时间应该差不多。
因此,就迭代而言,使用numpy的主要优势在于您不需要进行迭代。操作以向量化的方式应用于数组上。迭代只会减慢速度。如果您发现自己正在迭代数组元素,您应该尝试找到一种重构算法的方法,使其仅使用numpy操作(它有如此多的内置函数!)或者如果确实必要,可以使用np.apply_along_axis, np.apply_over_axis或np.vectorize。
list(np.arange(10))和np.arange(10).tolist()之间有一个微妙的区别:前者将导致一个由np.int64组成的列表,后者将导致一个由Python int组成的列表。对于诸如序列化(例如使用JSON)之类的操作,第一个会有问题。因为JSON无法处理np.int64,所以第一个会出错。 - MaxNoeIn [1034]: timeit [i for i in np.arange(10000000)]
1 loop, best of 3: 2.16 s per loop
In [1035]: timeit [i for i in range(10000000)]
1 loop, best of 3: 1.26 s per loop
tolist 将 arange 转换为列表; 这样做需要更长的时间,但迭代仍然在列表上进行。
In [1036]: timeit [i for i in np.arange(10000000).tolist()]
1 loop, best of 3: 1.6 s per loop
使用list() - 与数组的直接迭代同时进行;这表明直接迭代首先执行此操作。
In [1037]: timeit [i for i in list(np.arange(10000000))]
1 loop, best of 3: 2.18 s per loop
In [1038]: timeit np.arange(10000000).tolist()
1 loop, best of 3: 927 ms per loop
有时需要在 .tolist 上进行迭代。
In [1039]: timeit list(np.arange(10000000))
1 loop, best of 3: 1.55 s per loop
通常情况下,如果必须循环,使用列表会更快。访问列表元素更简单。
查看通过索引返回的元素。
a[0] 是另一个 numpy 对象; 它由 a 中的值构建而成,但不仅仅是获取的值
list(a)[0] 是相同类型;列表只是 [a[0], a[1], a[2]]]
In [1043]: a = np.arange(3)
In [1044]: type(a[0])
Out[1044]: numpy.int32
In [1045]: ll=list(a)
In [1046]: type(ll[0])
Out[1046]: numpy.int32
但是tolist将数组转换为一个纯列表,本例中是一个整数列表。它比list()做更多的工作,但在编译代码时完成。
In [1047]: ll=a.tolist()
In [1048]: type(ll[0])
Out[1048]: int
list(anarray),它很少做有用的事情,并且不如tolist()强大。a.tolist()是从数组创建整数列表的最快向量化方式。它进行迭代,但是是在编译代码中完成的。tolist 只对一维数组有效,当你添加第二个轴时,性能提升就会消失:
import numpy as np
import timeit
num_repeats = 10
x = np.arange(10000000)
via_tolist = timeit.timeit("[i for i in x.tolist()]", number=num_repeats, globals={"x": x})
direct = timeit.timeit("[i for i in x]",number=num_repeats, globals={"x": x})
print(f"tolist: {via_tolist / num_repeats}")
print(f"direct: {direct / num_repeats}")
tolist: 0.430838281600154
direct: 0.49088368080047073
import numpy as np
import timeit
num_repeats = 10
x = np.arange(10000000*10).reshape(-1, 10)
via_tolist = timeit.timeit("[i for i in x.tolist()]", number=num_repeats, globals={"x": x})
direct = timeit.timeit("[i for i in x]", number=num_repeats, globals={"x": x})
print(f"tolist: {via_tolist / num_repeats}")
print(f"direct: {direct / num_repeats}")
tolist: 2.5606724178003786
direct: 1.2158976945000177
我的测试用例有一个numpy数组
[[ 34 107]
[ 963 144]
[ 921 1187]
[ 0 1149]]
我只使用range和enumerate一次进行遍历
使用range
loopTimer1 = default_timer()
for l1 in range(0,4):
print(box[l1])
print("Time taken by range: ",default_timer()-loopTimer1)
结果
[ 34 107]
[963 144]
[ 921 1187]
[ 0 1149]
Time taken by range: 0.0005405639985838206
loopTimer2 = default_timer()
for l2,v2 in enumerate(box):
print(box[l2])
print("Time taken by enumerate: ", default_timer() - loopTimer2)
结果
[ 34 107]
[963 144]
[ 921 1187]
[ 0 1149]
Time taken by enumerate: 0.00025605700102460105
我选择了这个测试案例 enumerate ,它会更快地运行。
list(np.arange(1000000))看起来非常快。 - Divakarlist()会生成一个由np.int32对象构成的列表;而tolist则会生成一个由int构成的列表。它们不是一样的。 - hpauljtolist是最快的方法。还是要对数组的每个元素应用一些标量函数? - hpaulj