快速排序算法什么时候需要 O(n^2) 的时间复杂度?
6个回答
32
快速排序通过选取一个基准值,将所有比该基准值小的元素放在一边,将所有比该基准值大的元素放在另一边;然后以相同方式递归地对这两个子组进行排序(一直到全部排序完成)。如果每次选择最差的基准值(即列表中的最高或最低元素),那么你只需要对一个组进行排序,该组除了你选择的原始基准值之外的所有元素都在其中。这实质上让你得到n个需要遍历n次的组,因此具有O(n^2)复杂度。
导致这种情况发生的最常见原因是在快速排序实现中选择第一个或最后一个元素作为基准值。对于未排序的列表,这与其他任何方法一样有效,但对于已排序或近乎排序的列表(在实践中很常见),这很可能会给你带来最坏的情况。这就是为什么所有合格的实现通常会从列表中心选择基准值的原因。
有一些修改标准快速排序算法以避免这种情况的方法 - 其中一个例子是双轴快速排序,它被集成到Java 7中。
- Michael Berry
3
2Java的Arrays.sort方法使用双轴快速排序来避免O(N^2)边缘情况。 - Jimbo
@Jimbo 谢谢,我之前不知道 - 我现在已经添加了它。 - Michael Berry
好的解释。找到了快速排序的最坏情况示例,其中右侧枢轴为:
1,2,3,4,5,6,7,8,9,10;
10,2,3,4,5,6,7,8,9,1;
10,9,3,4,5,6,7,8,2,1;
10,9,8,4,5,6,7,3,2,1;
10,9,8,7,5,6,4,3,2,1;
10,9,8,7,6,5,4,3,2,1; - Dron4K
22
简而言之,以最低元素为首的快速排序算法的步骤如下:
有不同的方案选择基准元素。早期版本只取最左边的元素。在最坏的情况下,基准元素将始终是当前范围内的最低元素。
这里是用于生成最差序列的修改版快速排序的C++代码:
结果如下:
生成的序列为:
生成的序列是:
- 选择一个基准元素
- 对数组进行预排序,使得所有小于基准元素的元素在左侧
- 递归地对左侧和右侧执行步骤1和2
有不同的方案选择基准元素。早期版本只取最左边的元素。在最坏的情况下,基准元素将始终是当前范围内的最低元素。
以最左边的元素作为基准
在这种情况下,可以很容易地想出最坏情况是单调递增的数组:0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
最右侧的元素作为枢轴
同样地,选择最右侧的元素作为枢轴时,最坏情况是一个递减的序列。
20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
中心元素是枢轴
针对已排序数组的最坏情况,有一种可能的解决方案是使用中心元素(如果序列长度为偶数,则略微向左移动)。然后,最坏情况会变得更加奇特。它可以通过修改快速排序算法来构造,以将当前选定的枢轴元素对应的数组元素设置为单调递增的值。即,我们知道第一个枢轴是中心,所以中心必须是最低值,例如0。接下来,它被交换到最左边,即最左边的值现在位于中心,并且将成为下一个枢轴元素,因此它必须是1。现在,我们可以猜测数组将如下所示:
1 ? ? 0 ? ? ?
这里是用于生成最差序列的修改版快速排序的C++代码:
// g++ -std=c++11 worstCaseQuicksort.cpp && ./a.out
#include <algorithm> // swap
#include <iostream>
#include <vector>
#include <numeric> // iota
int main( void )
{
std::vector<int> v(20); /**< will hold the worst case later */
/* p basically saves the indices of what was the initial position of the
* elements of v. As they get swapped around by Quicksort p becomes a
* permutation */
auto p = v;
std::iota( p.begin(), p.end(), 0 );
/* in the worst case we need to work on v.size( sequences, because
* the initial sequence is always split after the first element */
for ( auto i = 0u; i < v.size(); ++i )
{
/* i can be interpreted as:
* - subsequence starting index
* - current minimum value, if we start at 0 */
/* note thate in the last step iPivot == v.size()-1 */
auto const iPivot = ( v.size()-1 + i )/2;
v[ p[ iPivot ] ] = i;
std::swap( p[ iPivot ], p[i] );
}
for ( auto x : v ) std::cout << " " << x;
}
结果如下:
0
0 1
1 0 2
2 0 1 3
1 3 0 2 4
4 2 0 1 3 5
1 5 3 0 2 4 6
4 2 6 0 1 3 5 7
1 5 3 7 0 2 4 6 8
8 2 6 4 0 1 3 5 7 9
1 9 3 7 5 0 2 4 6 8 10
6 2 10 4 8 0 1 3 5 7 9 11
1 7 3 11 5 9 0 2 4 6 8 10 12
10 2 8 4 12 6 0 1 3 5 7 9 11 13
1 11 3 9 5 13 7 0 2 4 6 8 10 12 14
8 2 12 4 10 6 14 0 1 3 5 7 9 11 13 15
1 9 3 13 5 11 7 15 0 2 4 6 8 10 12 14 16
16 2 10 4 14 6 12 8 0 1 3 5 7 9 11 13 15 17
1 17 3 11 5 15 7 13 9 0 2 4 6 8 10 12 14 16 18
10 2 18 4 12 6 16 8 14 0 1 3 5 7 9 11 13 15 17 19
1 11 3 19 5 13 7 17 9 15 0 2 4 6 8 10 12 14 16 18 20
16 2 12 4 20 6 14 8 18 10 0 1 3 5 7 9 11 13 15 17 19 21
1 17 3 13 5 21 7 15 9 19 11 0 2 4 6 8 10 12 14 16 18 20 22
12 2 18 4 14 6 22 8 16 10 20 0 1 3 5 7 9 11 13 15 17 19 21 23
1 13 3 19 5 15 7 23 9 17 11 21 0 2 4 6 8 10 12 14 16 18 20 22 24
这里有一定的顺序。右侧只是从零开始增加二的递增量。左侧也有一定的顺序。让我们使用Ascii艺术将左侧格式化为73个元素的最坏情况序列:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
------------------------------------------------------------------------------------------------------------
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35
37 39 41 43 45 47 49 51 53
55 57 59 61 63
65 67
69
71
标题是元素索引。在第一行中,从1开始,每2个元素增加1个数字。在第二行中,对每4个元素执行相同的操作,在第三行中,将数字分配给每8个元素,以此类推。在这种情况下,要写入第i行的第一个值位于索引2 ^ i-1处,但对于某些长度,这看起来有点不同。
得到的结构类似于一个倒置的二叉树,其节点从叶子开始自下而上标记。
左侧、中心和右侧元素的中位数是枢轴
另一种方法是使用最左侧、中心和最右侧元素的中位数。在这种情况下,最坏情况只能是,w.l.o.g.左子序列的长度为2(不仅像上面的示例那样只有长度为1)。同时,我们假设最右侧的值始终是中位数中最高的。这也意味着它是所有值中最高的。通过对程序进行调整,我们现在有:
auto p = v;
std::iota( p.begin(), p.end(), 0 );
auto i = 0u;
for ( ; i < v.size(); i+=2 )
{
auto const iPivot0 = i;
auto const iPivot1 = ( i + v.size()-1 )/2;
v[ p[ iPivot1 ] ] = i+1;
v[ p[ iPivot0 ] ] = i;
std::swap( p[ iPivot1 ], p[i+1] );
}
if ( v.size() > 0 && i == v.size() )
v[ v.size()-1 ] = i-1;
生成的序列为:
0
0 1
0 1 2
0 1 2 3
0 2 1 3 4
0 2 1 3 4 5
0 4 2 1 3 5 6
0 4 2 1 3 5 6 7
0 4 2 6 1 3 5 7 8
0 4 2 6 1 3 5 7 8 9
0 8 2 6 4 1 3 5 7 9 10
0 8 2 6 4 1 3 5 7 9 10 11
0 6 2 10 4 8 1 3 5 7 9 11 12
0 6 2 10 4 8 1 3 5 7 9 11 12 13
0 10 2 8 4 12 6 1 3 5 7 9 11 13 14
0 10 2 8 4 12 6 1 3 5 7 9 11 13 14 15
0 8 2 12 4 10 6 14 1 3 5 7 9 11 13 15 16
0 8 2 12 4 10 6 14 1 3 5 7 9 11 13 15 16 17
0 16 2 10 4 14 6 12 8 1 3 5 7 9 11 13 15 17 18
0 16 2 10 4 14 6 12 8 1 3 5 7 9 11 13 15 17 18 19
0 10 2 18 4 12 6 16 8 14 1 3 5 7 9 11 13 15 17 19 20
0 10 2 18 4 12 6 16 8 14 1 3 5 7 9 11 13 15 17 19 20 21
0 16 2 12 4 20 6 14 8 18 10 1 3 5 7 9 11 13 15 17 19 21 22
0 16 2 12 4 20 6 14 8 18 10 1 3 5 7 9 11 13 15 17 19 21 22 23
0 12 2 18 4 14 6 22 8 16 10 20 1 3 5 7 9 11 13 15 17 19 21 23 24
随机种子为0的伪随机元素是枢轴
对于中间元素和三数中值,最坏情况下的序列已经相当随机了,但为了使快速排序更加健壮,可以随机选择枢轴元素。如果所使用的随机序列在每次快速排序运行时都是可重复的,那么我们也可以构造出针对该序列的最坏情况序列。我们只需要调整第一个程序中的行,例如:
srand(0); // you shouldn't use 0 as a seed
for ( auto i = 0u; i < v.size(); ++i )
{
auto const iPivot = i + rand() % ( v.size() - i );
[...]
生成的序列是:
0
1 0
1 0 2
2 3 1 0
1 4 2 0 3
5 0 1 2 3 4
6 0 5 4 2 1 3
7 2 4 3 6 1 5 0
4 0 3 6 2 8 7 1 5
2 3 6 0 8 5 9 7 1 4
3 6 2 5 7 4 0 1 8 10 9
8 11 7 6 10 4 9 0 5 2 3 1
0 12 3 10 6 8 11 7 2 4 9 1 5
9 0 8 10 11 3 12 4 6 7 1 2 5 13
2 4 14 5 9 1 12 6 13 8 3 7 10 0 11
3 15 1 13 5 8 9 0 10 4 7 2 6 11 12 14
11 16 8 9 10 4 6 1 3 7 0 12 5 14 2 15 13
6 0 15 7 11 4 5 14 13 17 9 2 10 3 12 16 1 8
8 14 0 12 18 13 3 7 5 17 9 2 4 15 11 10 16 1 6
3 6 16 0 11 4 15 9 13 19 7 2 10 17 12 5 1 8 18 14
6 0 14 9 15 2 8 1 11 7 3 19 18 16 20 17 13 12 10 4 5
14 16 7 9 8 1 3 21 5 4 12 17 10 19 18 15 6 0 11 2 13 20
1 2 22 11 16 9 10 14 12 6 17 0 5 20 4 21 19 8 3 7 18 15 13
22 1 15 18 8 19 13 0 14 23 9 12 10 5 11 21 6 4 17 2 16 7 3 20
2 19 17 6 10 13 11 8 0 16 12 22 4 18 15 20 3 24 21 7 5 14 9 1 23
那么如何检查这些序列是否正确?
- 测量序列所花费的时间。将时间绘制成序列长度N的函数图像。如果曲线与O(N log(N))的比例关系不同,而是与O(N^2)的比例关系相同,则这些确实是最坏情况下的序列。
- 调整正确的快速排序算法,以便提供有关子序列长度和/或选择的枢轴元素的调试输出。其中一个子序列应始终为长度1(或中位数为3时长度为2)。打印出的选定枢轴元素应递增。
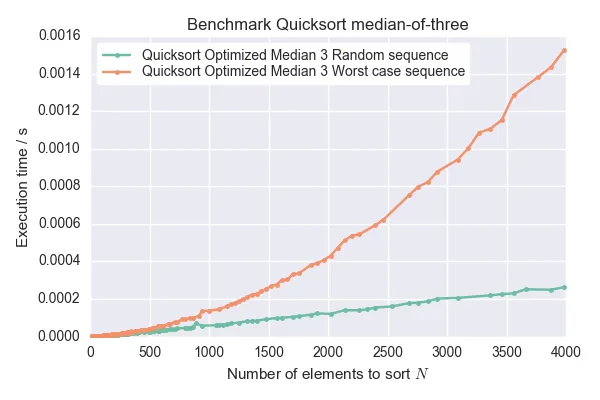
- mxmlnkn
7
我希望您自己完成了所有这些令人印象深刻的工作,而不是从其他地方窃取......这样我的+1才不会给一个剽窃者! - GhostCat
我希望我能够给予超过+1的评价。真的很棒! - Rüdiger Klaehn
我测试了您的中值轴算法示例输出,看起来它没有生成最坏情况的场景。例如:2 0 1 3 -> 需要比较10次元素进行排序,但在这种情况下1 3 0 2 -> 需要比较11次。 - kyxap
我认为我做得最差:2 4 3 1 @kyxap - Felipe Gutierrez
我偶然发现了这个“古怪快速排序”的早期实现(链接:https://www.cs.dartmouth.edu/~doug/aqsort.c)。但我还没有详细查看代码。 - mxmlnkn
显示剩余2条评论
10
当选择最小或最大数作为轴点时,会触发时间复杂度为O(n2)的最坏情况。
- Ghpst
4
不同的快速排序实现需要不同的数据集来使其达到最坏情况运行时间,这取决于算法选择的枢轴元素。正如Ghpst所说,选择最大或最小的数字会给你最坏情况。如果我没记错的话,快速排序通常使用随机元素作为枢轴,以最小化出现最坏情况的可能性。
- Alxandr
1
3我会说“随机化”,而不是“最小化”。机会保持不变,只是变得更不可预测 :) - Nikita Rybak
1
我认为如果数组是倒序的,那么选择最后一个元素作为枢轴将会是最坏情况。
- Zeel
0
导致快速排序最坏情况的因素如下:
- 当子数组完全不平衡时,最坏情况会发生
- 当一个子数组中有0个元素,而另一个子数组中有
n-1个元素时,最坏情况会发生。
换句话说,当快速排序接收到一个已排序的数组(按降序排列)时,最坏情况的运行时间为O(n^2)。
- Gary
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接