我以前从未见过双轴快速排序。 它是快速排序的升级版吗? 那么双轴快速排序和快速排序有什么区别?
3个回答
98
我在Java文档中找到了以下内容:
排序算法是由Vladimir Yaroslavskiy、Jon Bentley和Joshua Bloch提供的双轴快速排序。该算法在许多数据集上提供O(n log(n))的性能,而其他快速排序算法则会退化为二次性能,并且通常比传统的(单轴)快速排序实现更快。
然后我在谷歌搜索结果中找到了以下内容:
快速排序算法的理论:
- 从数组中选取一个元素作为枢轴。
- 重新排列数组,使所有小于枢轴的元素都在枢轴之前,而所有大于枢轴的元素都在枢轴之后(相等的值可以在任意一侧)。完成分区后,枢轴元素位于其最终位置。
- 递归地对较小元素的子数组和较大元素的子数组进行排序。
与此相比,双轴快速排序:
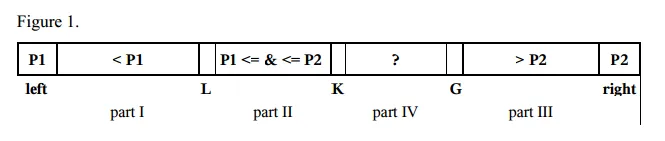
- 对于小型数组(长度<17),使用插入排序算法。
- 选择两个枢轴元素P1和P2。例如,我们可以将第一个元素a[left]作为P1,将最后一个元素a[right]作为P2。
- P1必须小于P2,否则它们将被交换。因此,有以下几个部分:
- 从left+1到L-1的索引i表示元素小于P1的部分一;
- 从L到K-1的索引i表示元素大于等于P1且小于等于P2的部分二;
- 从G+1到right-1的索引i表示元素大于P2的部分三;
- 从K到G的索引i表示待检查的其余元素的部分四。
- 从部分IV中获取下一个元素a[K],并将其与两个枢轴P1和P2进行比较,然后将其放置在相应的部分I、II或III中。
- Brutal_JL
8
71这就是为什么我们非常感激Java库的设计者,因为我们不需要实现自己的排序算法,否则我们都将使用冒泡排序;-) - donturner
1为什么插入排序中使用17?这是任意的吗? - abksrv
12@abksrv,MergeSort的时间复杂度为O(n log n),而InsertionSort的时间复杂度为O(n^2),不过实际上它们的时间复杂度分别是C1 * n * log(n)和C2 * n * n(其中C1和C2是一些常数)。当n很大时,这些常数是不相关紧要的。当n很小时,它们可能是相关重要的。假定实现者研究并发现17是一个临界点,使得C1 * log(17) > C2 * 17,但C1 * log(18) < C2 * 18。 - John Hascall
6Yaroslovsky原始论文(http://codeblab.com/wp-content/uploads/2009/09/DualPivotQuicksort.pdf)将使用插入排序的阈值设置为27,而不是17。另一方面,Yaroslovsky、Bentley和Bloch在Java 8中的实现(http://hg.openjdk.java.net/jdk8/jdk8/jdk/file/tip/src/share/classes/java/util/DualPivotQuicksort.java)将阈值设为47。 - Harfangk
1优化版由Yaroslovsky最近合并至OpenJDK - https://bugs.openjdk.java.net/browse/JDK-8226297 - Joe Bowbeer
显示剩余3条评论
11
我想强调的是,从算法角度来看(即成本仅考虑比较和交换的次数),2个轴点快速排序和3个轴点快速排序并不比经典的快速排序(使用1个轴点)更好,甚至更糟。但是,在实践中它们更快,因为它们利用了现代计算机体系结构的优势,特别是它们的缓存未命中数更少。因此,如果我们删除所有缓存,只剩下CPU和主内存,我认为2/3个轴点快速排序比经典的快速排序更差。
参考资料: 3个轴点快速排序: https://epubs.siam.org/doi/pdf/10.1137/1.9781611973198.6 分析其为何优于经典快速排序: https://arxiv.org/pdf/1412.0193v1.pdf 完整而不太详细的参考资料: https://algs4.cs.princeton.edu/lectures/23Quicksort.pdf
参考资料: 3个轴点快速排序: https://epubs.siam.org/doi/pdf/10.1137/1.9781611973198.6 分析其为何优于经典快速排序: https://arxiv.org/pdf/1412.0193v1.pdf 完整而不太详细的参考资料: https://algs4.cs.princeton.edu/lectures/23Quicksort.pdf
- Duong Nguyen
2
深刻的回答。可能是这里最好的一个。最后一个链接已经过时了。你还有文件吗? - Sadderdaze
您可以在此处找到所有更新的课程讲义:https://algs4.cs.princeton.edu/lectures/ - zemageht
3
如果您感兴趣,可以看一下他们如何在Java中实现这个算法:
http://grepcode.com/file/repository.grepcode.com/java/root/jdk/openjdk/8u40-b25/java/util/DualPivotQuicksort.java#DualPivotQuicksort.sort%28int%5B%5D%2Cint%2Cint%2Cint%5B%5D%2Cint%2Cint%29
如源代码所述:
“如果可能,使用给定的工作区数组片段对数组的指定范围进行排序。
该算法在许多数据集上提供O(n log(n))的性能,而导致其他快速排序算法降级为二次性能,并且通常比传统的(单脉冲)快速排序实现更快。”
“如果可能,使用给定的工作区数组片段对数组的指定范围进行排序。
该算法在许多数据集上提供O(n log(n))的性能,而导致其他快速排序算法降级为二次性能,并且通常比传统的(单脉冲)快速排序实现更快。”
- Anatoly Yakimchuk
1
您还可以从以下链接浏览代码:https://www.codatlas.com/github.com/lambdalab-mirror/jdk7u-jdk/master/src/share/classes/java/util/Arrays.java https://github.com/openjdk-mirror/jdk7u-jdk/blob/master/src/share/classes/java/util/Arrays.java - firephil
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接