我有以下代码,基本上是使用randomForest尝试预测
代码的结果生成了这个图表:
iris数据中的Species。我真正感兴趣的是找出最好的特征(变量),以解释物种分类。我发现randomForestExplainer包是最适合这个目的的。library(randomForest)
library(randomForestExplainer)
forest <- randomForest::randomForest(Species ~ ., data = iris, localImp = TRUE)
importance_frame <- randomForestExplainer::measure_importance(forest)
randomForestExplainer::plot_multi_way_importance(importance_frame, size_measure = "no_of_nodes")
代码的结果生成了这个图表:
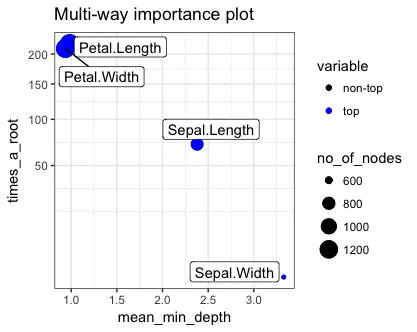
基于这个情节,解释Petal.Length和Petal.Width为什么是最好的因素的关键因素是这些(解释基于vignette):
mean_min_depth- 在参数mean_sample指定的三种方式之一中计算的平均最小深度,times_a_root- 使用Xj分割根节点的树的总数(即,基于Xj的值将整个样本分成两部分),no_of_nodes- 使用Xj进行分割的节点的总数(如果树较浅,则通常等于no_of_trees),
我不完全清楚为什么高times_a_root和no_of_nodes更好?而低mean_min_depth更好?
这是什么直观的解释呢?
vignette信息并没有帮助。