我试图使用
stargazer 包输出回归结果。我使用 lfe 包中的 felm 进行回归。除了 F 统计量的值保持为空白外,stargazer 输出表格正常显示所有内容。但是,这个问题不会在 lm 结果中出现。
什么是原因?如何让我的 felm 回归的 F 统计量值出现在 stargazer 输出中?
我知道我可以手动添加一行来显示 F 值,但如果可能的话,我更愿意采用更自动化的方法。
以下是使用提供的数据样本代码 here
library(foreign)
temp_dat <- read.dta("http://www.kellogg.northwestern.edu/faculty/petersen/htm/papers/se/test_data.dta")
temp_lm <- lm(y ~ x, temp_dat)
temp_felm <- felm(y ~ x, temp_dat)
library(stargazer)
stargazer(temp_lm, temp_felm, type = "text")
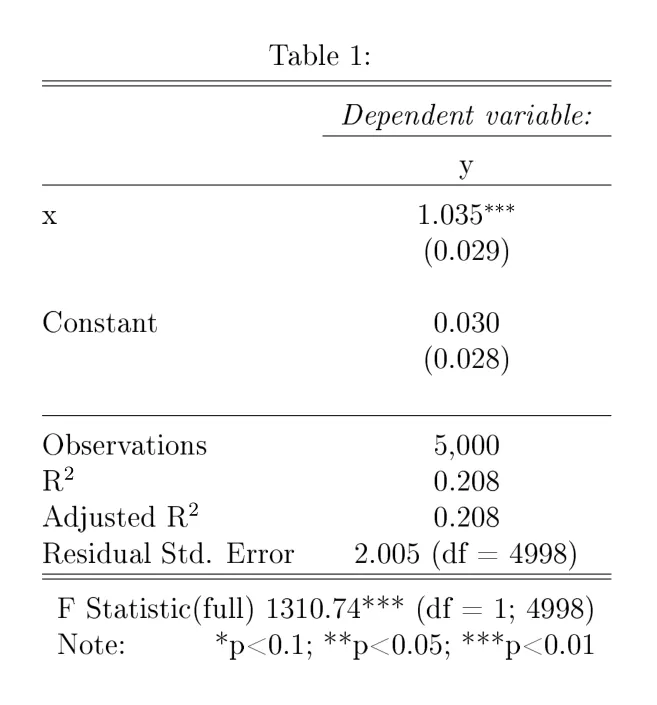
输出:
====================================================================
Dependent variable:
------------------------------------
y
OLS felm
(1) (2)
--------------------------------------------------------------------
x 1.035*** 1.035***
(0.029) (0.029)
Constant 0.030 0.030
(0.028) (0.028)
--------------------------------------------------------------------
Observations 5,000 5,000
R2 0.208 0.208
Adjusted R2 0.208 0.208
Residual Std. Error (df = 4998) 2.005 2.005
F Statistic 1,310.740*** (df = 1; 4998)
====================================================================
Note: *p<0.1; **p<0.05; ***p<0.01
texreg是高度可扩展的。我建议查看手册以了解如何使用createTexreg函数。我将在上面添加一个函数来完成这个任务。 - paqmo