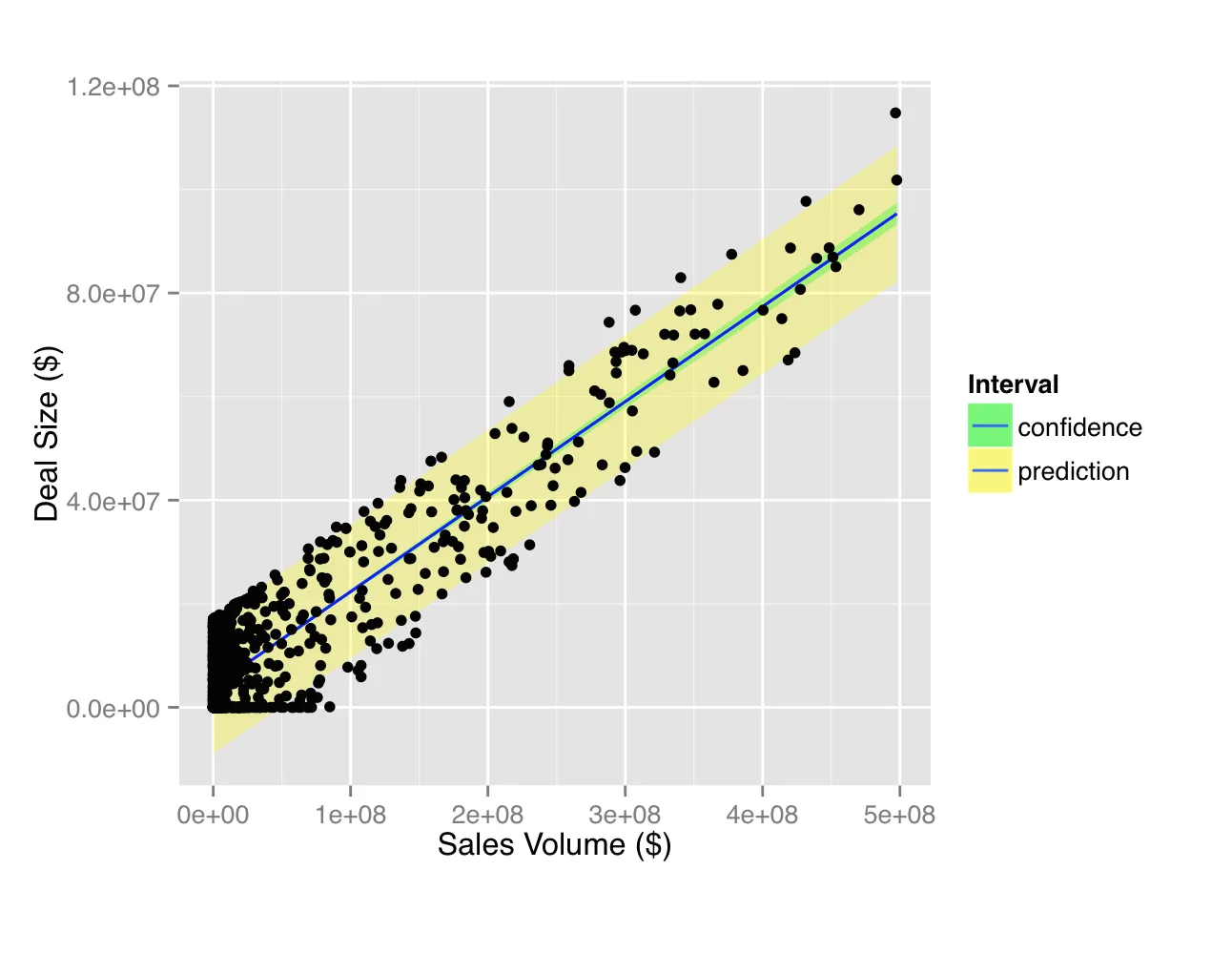
我正在尝试理解predict()的输出,以及了解这种方法是否适用于我要解决的问题。预测区间对我来说没有意义,但当我在散点图上绘制时,它看起来是一个好模型:
Call:
lm(formula = deal_size ~ sales_volume, data = accounts)
Residuals:
Min 1Q Median 3Q Max
-19123502 -3794671 -3426616 4838578 17328948
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.709e+06 1.727e+05 21.48 <2e-16 ***
sales_volume 1.898e-01 2.210e-03 85.88 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 6452000 on 1586 degrees of freedom
Multiple R-squared: 0.823, Adjusted R-squared: 0.8229
F-statistic: 7376 on 1 and 1586 DF, p-value: < 2.2e-16
预测是这样生成的:
d = data.frame(accounts, predict(fit, interval="prediction"))
当我在散点图上绘制销售量与交易规模,并叠加回归线和预测区间时,看起来很好,除了一些跨越零附近的负值区间。
我知道拟合是预测值,但是lwr和upr是什么?它们是否以绝对值(y坐标)定义区间?这些区间似乎非常宽,比起我的模型是否良好适合而言更加宽广。
sales_volume deal_size fit lwr upr
0 0 3709276.494 -8950776.04 16369329.03
0 8586337.22 3709276.494 -8950776.04 16369329.03
110000 549458.6512 3730150.811 -8929897.298 16390198.92
?predict.lm。 - J.R.