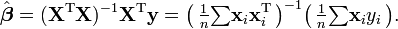stack.ma_stack.shape
(1461, 390, 327)
我进行了一个快速测试,循环遍历每一行和列:
from scipy.stats.mstats import linregress
#Ordinal dates
x = stack.date_list_o
#Note: idx should be row, col
def sample_lstsq(idx):
b = stack.ma_stack[:, idx[0], idx[1]]
#Note, this is masked stats version
slope, intercept, r_value, p_value, std_err = linregress(x, b)
return slope
out = np.zeros_like(stack.ma_stack[0])
for row in np.arange(stack.ma_stack.shape[1]):
for col in np.arange(stack.ma_stack.shape[2]):
out[row, col] = sample_lstsq((row, col))
我知道这个方法可以运行(但速度慢)。我知道肯定有更高效的方法。我已经尝试使用索引数组和np.vectorize,但我认为这并不能提供任何真正的改进。我考虑将所有内容转储到Pandas或尝试移植到Cython,但我希望能坚持使用NumPy/SciPy。或者并行解决方案是我改善性能的最佳选择?此外,有人对NumPy/SciPy线性回归选项进行过基准测试吗?我找到了以下选项,但还没有自己进行测试:
- scipy.stats.linregress
- numpy.linalg.leastsq
- numpy.polyfit(deg=1)
我希望有一种现有的方法可以在不需要太多实现工作的情况下显著提高性能。谢谢。
编辑于12/3/13 @02:29
@HYRY建议的方法对于上述样本数据集非常有效(运行时间约为15秒),该数据集在所有维度(空间和时间)上均为连续(未屏蔽)。 但是,当将包含缺失数据的掩蔽数组传递给np.linalg.leastsq时,所有屏蔽值都将填充为fill_value(默认值1E20),这会导致虚假的线性拟合。
幸运的是,numpy屏蔽数组模块具有np.ma.polyfit(deg = 1),它可以处理类似于np.linalg.leastsq的2D y数组。 查看源代码(https://github.com/numpy/numpy/blob/v1.8.0/numpy/ma/extras.py#L1852),ma polyfit只是一个使用x和y掩码的组合掩码的np.polyfit包装器。 当y中的缺失数据位置恒定时,这对于2D y非常有效。
不幸的是,我的数据在空间和时间上具有可变的缺失数据位置。以下是另一个堆栈的示例:
In [146]: stack.ma_stack.shape
Out [146]: (57, 1889, 1566)
抽样单个索引会返回一个时间序列,其中有6个未屏蔽的值:
In [147]: stack.ma_stack[:,0,0]
Out [147]:
masked_array(data = [-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
519.7779541015625 -- -- -- 518.9047241210938 -- -- -- -- -- -- --
516.6539306640625 516.0836181640625 515.9403686523438 -- -- -- --
514.85205078125 -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --],
mask = [ True True True True True True True True True True True True
True True True True True True True True True False True True
True False True True True True True True True False False False
True True True True False True True True True True True True
True True True True True True True True True],
fill_value = 1e+20)
采样不同的位置会返回不同时间切片中未屏蔽值的数量:
In [148]: stack.ma_stack[:,1888,1565]
Out[148]:
masked_array(data = [-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
729.0936889648438 -- -- -- 724.7155151367188 -- -- -- -- -- -- --
722.076171875 720.9276733398438 721.9603881835938 -- 720.3294067382812 --
-- 713.9591064453125 709.8037719726562 707.756103515625 -- -- --
703.662353515625 -- -- -- -- 708.6276245117188 -- -- -- -- --],
mask = [ True True True True True True True True True True True True
True True True True True True True True True False True True
True False True True True True True True True False False False
True False True True False False False True True True False True
True True True False True True True True True],
fill_value = 1e+20)
每个索引的最小未遮盖值为6,最大值为45。因此,每个位置至少有一些被遮盖的值。 作为参考,我的x(时间序数)值都没有被遮盖:
In [150]: stack.date_list_o
Out[150]:
masked_array(data = [ 733197.64375 733962.64861111 733964.65694444 733996.62361111
733999.64236111 734001.63541667 734033.64305556 734071.64722222
734214.675 734215.65694444 734216.625 734226.64722222
734229.63819444 734232.65694444 734233.67847222 734238.63055556
734238.63055556 734245.65277778 734245.65277778 734255.63125
734255.63125 734307.85 734326.65138889 734348.63888889
734348.63958333 734351.85 734363.70763889 734364.65486111
734390.64722222 734391.63194444 734394.65138889 734407.64652778
734407.64722222 734494.85 734527.85 734582.85
734602.65486111 734664.85555556 734692.64027778 734741.63541667
734747.85 734807.85555556 734884.85555556 734911.65763889
734913.64375 734917.64236111 734928.85555556 734944.71388889
734961.62777778 735016.04583333 735016.62777778 735016.85555556
735036.65347222 735054.04583333 735102.63125 735119.61180556
735140.63263889],
mask = False,
fill_value = 1e+20)
所以我重塑了stack.ma_stack并运行了polyfit:
newshape = (stack.ma_stack.shape[0], stack.ma_stack.shape[1]*stack.ma_stack.shape[2])
print newshape
#(57, 2958174)
y = stack.ma_stack.reshape(newshape)
p = np.ma.polyfit(x, y, deg=1)
但是在第1500列左右,y中的每一行都被“累积”掩码,导致一些投诉和空输出:
RankWarning: Polyfit may be poorly conditioned
** On entry to DLASCL, parameter number 4 had an illegal value
...
因此,似乎在不同位置使用具有缺失数据的二维y是行不通的。我需要一个leastsq拟合,该拟合使用每个y列中的所有可用未屏蔽数据。也许可以通过仔细压缩x和y并跟踪未屏蔽索引来实现这一点。
还有其他想法吗?Pandas看起来可能是一个不错的解决方案。
编辑于12/3/13 @20:29
@HYRY提供了一个解决方案,适用于时间(轴=0)维度中的缺失值。 我必须稍微修改一下以处理空间(轴=1,2)维度中的缺失值。 如果特定的空间索引在时间上仅有一个未屏蔽的条目,我们肯定不想尝试进行线性回归。 这是我的实现:
def linreg(self):
#Only compute where we have n_min unmasked values in time
n_min = 3
valid_idx = self.ma_stack.count(axis=0).filled(0) >= n_min
#Returns 2D array of unmasked columns
y = self.ma_stack[:, valid_idx]
#Extract mask for axis 0 - invert, True where data is available
mask = ~y.mask
#Remove masks, fills with fill_value
y = y.data
#Independent variable is time ordinal
x = self.date_list_o
x = x.data
#Prepare matrices and solve
X = np.c_[x, np.ones_like(x)]
a = np.swapaxes(np.dot(X.T, (X[None, :, :] * mask.T[:, :, None])), 0, 1)
b = np.dot(X.T, (mask*y))
r = np.linalg.solve(a, b.T)
#Create output grid with original dimensions
out = np.ma.masked_all_like(self.ma_stack[0])
#Fill in the valid indices
out[valid_idx] = r[:,0]
运行时非常快 - 仅 ~5-10 秒钟处理这里讨论的数组维度。