我是Python和编程的初学者。我需要帮助比较两个数据帧,它们长度不同,并且除一个列标签之外,其他列标签也不同。在这两个数据集之间相同的列是我想通过比较数据帧来实现的列。我的数据如下:
df: 'fruits' 'trees' 'sports' 'countries'
bananas mongolia basketball Spain
grapes Oak rugby Thailand
oranges Osage Orange baseball Egypt
apples Maple golf Chile
df2: 'cars' 'flowers' 'countries' 'vegetables'
Audi Rose Spain Carrots
BMW Tulip Nigeria Celery
Honda Dandelion Egypt Onion
我希望能够基于“countries”列比较这两个数据框,并创建三个独立的输出,每个输出都在自己的数据框中。我一直在使用Pandas,并使用pd.concat将df1和df2合并成一个数据框。即使它们不匹配,我也希望保留其余数据框的行。
以下是我期望的输出:
输出# 1:df中不包含在df2中的值:
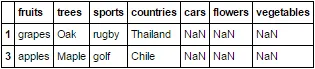
d3: 'fruits' 'trees' 'sports' 'countries'
grapes Oak rugby Thailand
apples Maple golf Chile
输出# 2:df2中不在df中的值
df4: 'cars' 'flowers' 'countries' 'vegetables'
BMW Tulip Nigeria Celery
输出# 3:df和df2中的值(结合不同数据帧的列)。
df5: 'fruits' 'trees' 'sports' 'cars' 'flowers' 'countries' 'vegetables'
bananas mongolia basketball Audi Rose Spain Carrots
Oranges Osage Orange baseball Honda Dandelion Egypt Onion
希望这一切都说得通。 我尝试了很多不同的方法(isin,DataFrame.diff和.difference,df-df2,numpy数组等),我已经搜索了所有地方,但是找不到我正在寻找的确切内容。 非常感谢任何帮助! 谢谢!


df和df2是您提供的数据框的名称。outer_parts函数内部的df1和df2是它们自己的存在。在这个例子中,我将df和df2传递给函数outer_parts,然后在函数内部对它们进行操作,作为df1和df2。那就是说...是的,df在某种程度上相当于df1,只不过在函数内部。希望我没有搞混事情。 - piRSquared