虽然
使用中位数值在seaborn中标记箱线图作为参考,但那些答案不适用,因为由
matplotlib绘制的须线不容易直接从数据中计算得出。
如
matplotlib.pyplot.boxplot所示,须线应该在
Q1-1.5IQR和
Q3+1.5IQR处,然而只有当存在异常值时,才会将须线绘制到这些值上。否则,须线只会绘制到
Q1下方的最小值,和/或
Q3上方的最大值。
查看
days_total_bill.min()可以看到所有低须线只绘制到列中的最小值(
{'Thur': 7.51, 'Fri': 5.75, 'Sat': 3.07, 'Sun': 7.25})。
如何获取matplotlib箱线图的数据展示了如何使用
matplotlib.cbook.boxplot_stats提取matplotlib使用的所有箱线图统计数据。
boxplot_stats适用于不包含
NaN的值数组。在样本数据的情况下,每天(注释1.)的值数量不相同,因此不能使用
boxplot_stats(days_total_bill.values),而是使用列表推导式(注释2.)来获取每列的统计数据。
tips是一个整洁的数据框,因此相关数据(
'day'和
'total_bill')被转换为宽数据框,使用
pandas.DataFrame.pivot,因为
boxplot_stats需要数据以这种形式提供。
字典列表被转换为数据框(注释3.),其中使用
.iloc仅选择要进行注释的统计数据。此步骤是为了在进行注释时更容易迭代每天的相关统计数据。
数据使用
sns.boxplot绘制,但也可以使用
pandas.DataFrame.plot。
box_plot = days_total_bill.plot(kind='box', figsize=(12, 8), positions=range(len(days_total_bill.columns))),其中
range指定从0开始索引,因为默认情况下箱线图从1开始索引。
在python 3.11.4、pandas 2.0.3、matplotlib 3.7.1、seaborn 0.12.2中测试通过。
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib.cbook import boxplot_stats
tips = sns.load_dataset("tips")
days_total_bill = tips.pivot(columns='day', values='total_bill')
days_total_bill_stats = [boxplot_stats(days_total_bill[col].dropna().values)[0] for col in days_total_bill.columns]
stats = pd.DataFrame(days_total_bill_stats, index=days_total_bill.columns).iloc[:, [4, 5, 7, 8, 9]].round(2)
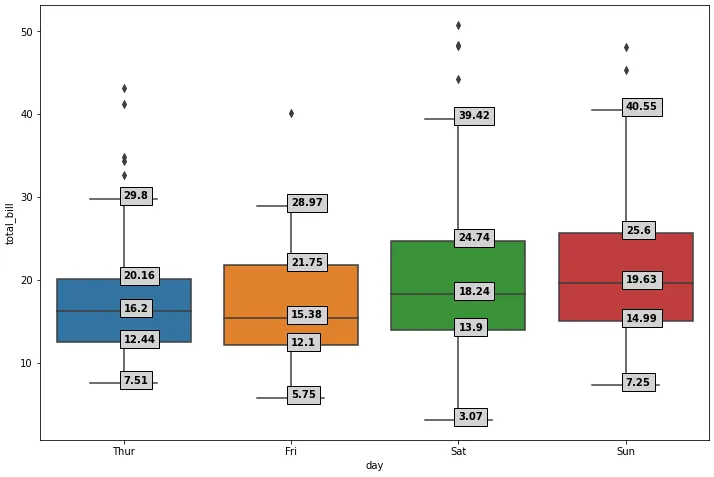
fig, ax = plt.subplots(figsize=(12, 8))
box_plot = sns.boxplot(data=days_total_bill, ax=ax)
for xtick in box_plot.get_xticks():
for col in stats.columns:
box_plot.text(xtick, stats[col][xtick], stats[col][xtick], horizontalalignment='left', size='medium', color='k', weight='semibold', bbox=dict(facecolor='lightgray'))
数据视图
提示
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
days_total_bill
day Thur Fri Sat Sun
0 NaN NaN NaN 16.99
1 NaN NaN NaN 10.34
2 NaN NaN NaN 21.01
3 NaN NaN NaN 23.68
4 NaN NaN NaN 24.59
...
239 NaN NaN 29.03 NaN
240 NaN NaN 27.18 NaN
241 NaN NaN 22.67 NaN
242 NaN NaN 17.82 NaN
243 18.78 NaN NaN NaN
days_total_bill_stats
[{'mean': 17.682741935483868,
'iqr': 7.712500000000002,
'cilo': 14.662203087202318,
'cihi': 17.73779691279768,
'whishi': 29.8,
'whislo': 7.51,
'fliers': array([32.68, 34.83, 34.3 , 41.19, 43.11]),
'q1': 12.442499999999999,
'med': 16.2,
'q3': 20.155},
{'mean': 17.15157894736842,
'iqr': 9.655000000000001,
'cilo': 11.902436010483171,
'cihi': 18.85756398951683,
'whishi': 28.97,
'whislo': 5.75,
'fliers': array([40.17]),
'q1': 12.094999999999999,
'med': 15.38,
'q3': 21.75},
{'mean': 20.441379310344825,
'iqr': 10.835,
'cilo': 16.4162347275501,
'cihi': 20.063765272449896,
'whishi': 39.42,
'whislo': 3.07,
'fliers': array([48.27, 44.3 , 50.81, 48.33]),
'q1': 13.905000000000001,
'med': 18.24,
'q3': 24.740000000000002},
{'mean': 21.41,
'iqr': 10.610000000000001,
'cilo': 17.719230764952172,
'cihi': 21.540769235047826,
'whishi': 40.55,
'whislo': 7.25,
'fliers': array([48.17, 45.35]),
'q1': 14.987499999999999,
'med': 19.63,
'q3': 25.5975}]
统计
whishi whislo q1 med q3
day
Thur 29.80 7.51 12.44 16.20 20.16
Fri 28.97 5.75 12.10 15.38 21.75
Sat 39.42 3.07 13.90 18.24 24.74
Sun 40.55 7.25 14.99 19.63 25.60
手动计算与Matplotlib盒须位置不匹配。
stats = tips.groupby(['day'])['total_bill'].quantile([0.25, 0.75]).unstack(level=1).rename({0.25: 'q1', 0.75: 'q3'}, axis=1)
stats.insert(0, 'iqr', stats['q3'].sub(stats['q1']))
stats['w_low'] = stats['q1'].sub(stats['iqr'].mul(1.5))
stats['w_hi'] = stats['q3'].add(stats['iqr'].mul(1.5))
stats = stats.round(2)
iqr q1 q3 w_low w_hi
day
Thur 7.71 12.44 20.16 0.87 31.72
Fri 9.66 12.10 21.75 -2.39 36.23
Sat 10.84 13.90 24.74 -2.35 40.99
Sun 10.61 14.99 25.60 -0.93 41.51