这可能是一个特殊情况,但你应该能够使用numpy的digitize函数。需要注意的是,分组必须单调递减或单调递增。
>>> import numpy
>>> a = numpy.array([10,7,2,0])
>>> b = numpy.array([10,9,8,7,6,5,4,3,2,1])
>>> indices = [numpy.where(a<=x)[0][0] for x in b]
[0, 1, 1, 1, 2, 2, 2, 2, 2, 3]
>>> numpy.digitize(b,a)
array([0, 1, 1, 1, 2, 2, 2, 2, 2, 3])
定时测试的设置:
a = np.arange(50)[::-1]
b = np.random.randint(0,50,1E3)
np.allclose([np.where(a<=x)[0][0] for x in b],np.digitize(b,a))
Out[55]: True
一些时间:
%timeit [np.where(a<=x)[0][0] for x in b]
100 loops, best of 3: 4.97 ms per loop
%timeit np.digitize(b,a)
10000 loops, best of 3: 48.1 µs per loop
看起来速度提升了两个数量级,但这将在很大程度上取决于箱子的数量。你的时间将会有所变化。
为了与 Jamie 的答案进行比较,我计时了以下两段代码。由于我主要想关注 searchsorted 和 digitize 的速度,因此我稍微简化了 Jamie 的代码。相关代码如下:
a = np.arange(size_a)[::-1]
b = np.random.randint(0, size_a, size_b)
ja = np.take(a, np.searchsorted(a, b, side='right', sorter=a)-1)
if ~np.allclose(ja,np.digitize(b,a)):
print 'Comparison failed'
timing_digitize[num_a,num_b] = timeit.timeit('np.digitize(b,a)',
'import numpy as np; from __main__ import a, b',
number=3)
timing_searchsorted[num_a,num_b] = timeit.timeit('np.take(a, np.searchsorted(a, b, side="right", sorter=a)-1)',
'import numpy as np; from __main__ import a, b',
number=3)
这超出了我的有限的matplotlib能力范围,因此使用DataGraph进行操作。我绘制了timing_digitize/timing_searchsorted的对数比率,当值大于零时,searchsorted更快,而值小于零时,digitize更快。颜色也代表了相对速度。例如,它显示在右上方(a=1E6,b=1E6),digitize比searchsorted慢大约300倍,而对于较小的大小,digitize可以快10倍左右。黑线大致是平衡点:
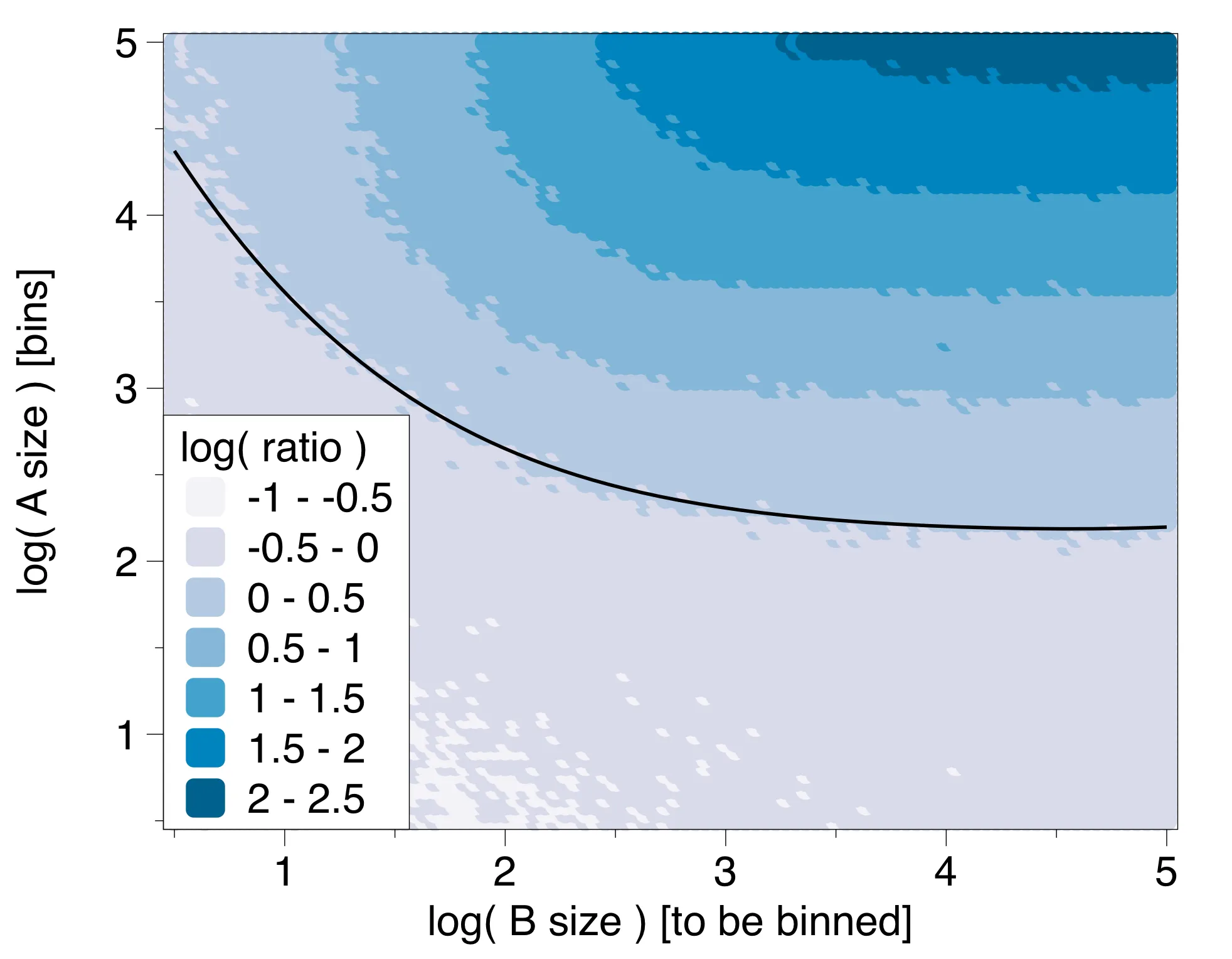 看起来对于大型案例,就原始速度而言,
看起来对于大型案例,就原始速度而言,searchsorted几乎总是更快的,但如果箱数较小,则digitize的简单语法几乎同样优秀。
a和b的合理大小吗?这会严重影响方法的时间。 - Daniel