假设该值存在,我如何在数据框中创建另一列“testFinal”,其中将包含 df["test"] 和 "df["test"] 0.2秒后" 的绝对值之差,例如,testFinal 的第一个值是 2 和 0.2 秒后的值之间差的绝对值 -> 因此为 8,结果为 abs(2-8) = 6。我的目标是计算“testFinal”。我不知道是否清晰,所以这里有个例子。
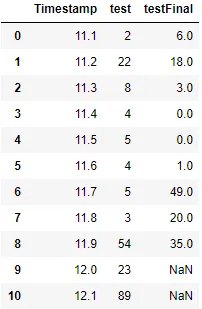
注意:时间戳不是均匀的,因此两个值之间的间隔可能随时间而异。
非常感谢
以下是数据框的代码
df = pd.DataFrame({'Timestamp':[11.1,11.2,11.3,11.4,11.5,11.6,11.7,11.8,11.9,12.0,12.10],
'test':[2,22,8,4,5,4,5,3,54,23,89],
'testFinal':[6,18,3,0,0,1,49,20,35,np.NaN,np.NaN]})