如果你想要在T在2和7之间时,计算列G的平均值:
df_new.loc[(df_new['T']>2) & (df_new['T']<7), 'G'].mean()
更新
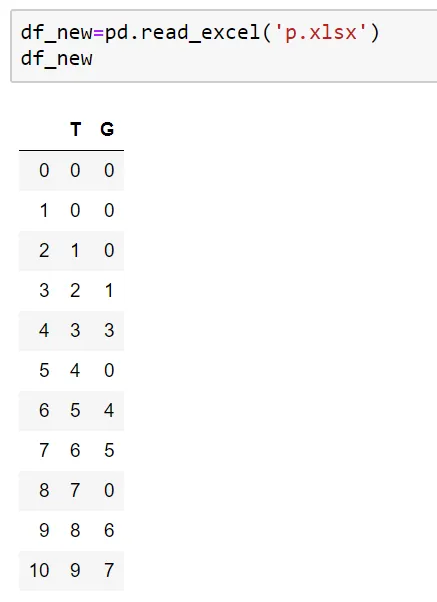
如果您没有任何期望输出,很难知道您想要什么。如果您有以下数据:
print(df)
T G
0 0 0
1 0 0
2 1 0
3 2 1
4 3 3
5 4 0
6 5 4
7 6 5
8 7 0
9 8 6
10 9 7
你想要像这样的东西:
print(df)
T G
0 0 0
1 0 0
2 1 0
3 2 1
4 3 3
5 4 3
6 5 3
7 6 3
8 7 0
9 8 6
10 9 7
然后你可以使用布尔索引和DataFrame.loc:
avg = df.loc[(df['T']>2) & (df['T']<7), 'G'].mean()
df.loc[(df['T']>2) & (df['T']<7), 'G'] = avg
print(df)
T G
0 0 0.0
1 0 0.0
2 1 0.0
3 2 1.0
4 3 3.0
5 4 3.0
6 5 3.0
7 6 3.0
8 7 0.0
9 8 6.0
10 9 7.0
更新2
如果您有一些样本数据:
print(df)
T G
0 0 1
1 2 2
2 3 3
3 3 1
4 3 2
5 10 4
6 2 5
7 2 5
8 2 5
9 10 5
方法 1:要简单地获取这些手段的列表,您可以为您的间隔创建组,并在 m 上进行过滤:
m = df['T'].between(0,5,inclusive=False)
g = m.ne(m.shift()).cumsum()[m]
lst = df.groupby(g).mean()['G'].tolist()
print(lst)
[2.0, 5.0]
方法二:如果您想在各自的T值处包含这些手段,那么可以尝试以下方法:
m = df['T'].between(0,5,inclusive=False)
g = m.ne(m.shift()).cumsum()
df['G_new'] = df.groupby(g)['G'].transform('mean')
print(df)
T G G_new
0 0 1 1
1 2 2 2
2 3 3 2
3 3 1 2
4 3 2 2
5 10 4 4
6 2 5 5
7 2 5 5
8 2 5 5
9 10 5 5
{kind=link}
{kind=link}
{kind=link}
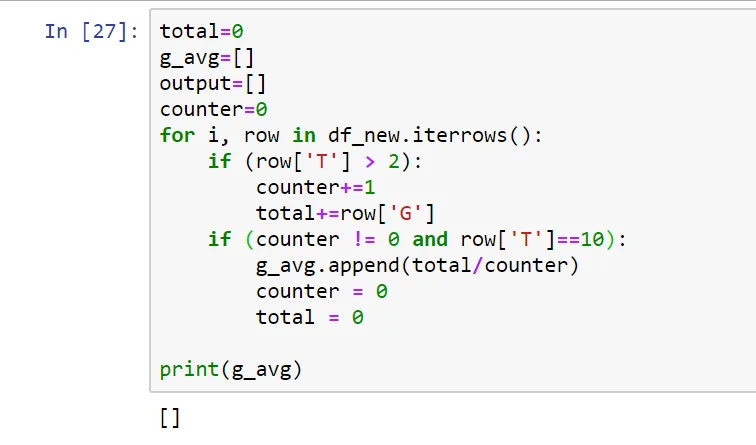
df_new[df_new['T'] > 2]['G'].mean()。 - sim