注意:这是《破解程序员面试》第五版中的问题4.3。
问题:给定一个已排序(按升序)的数组,请编写一个算法,创建一个具有最小高度的二叉搜索树。
以下是我用Java编写的解决此问题的算法:
public static IntTreeNode createBST(int[] array) {
return createBST(array, 0, array.length-1);
}
private static IntTreeNode createBST(int[] array, int left, int right) {
if(right >= left) {
int middle = array[(left + right)/2;
IntTreeNode root = new IntTreeNode(middle);
root.left = createBST(array, left, middle - 1);
root.right = createBST(array, middle + 1, right);
return root;
} else {
return null;
}
}
我对这段代码进行了检查,与作者的代码几乎相同。
但是我很难分析这个算法的时间复杂度。
我知道这不会像二分搜索那样在O(logn)内运行,因为在每个递归级别上你没有做同样数量的工作。例如,在第一级别上,1个单位的工作,第二级别-2个单位的工作,第三级别-4个单位的工作,一直到log2(n)级别-n个单位的工作。
因此,基于此,该算法所需的步骤数将受到以下数学表达式的上限约束:
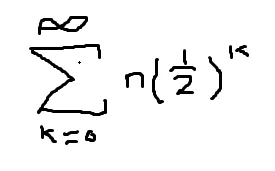
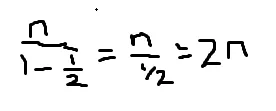 或2n,这将处于O(n)中。
或2n,这将处于O(n)中。你们是否同意我的结论,即该算法将以O(n)的速度运行,还是我漏掉了什么,它实际上以O(nlogn)或其他函数类运行?
f(n)和g(n)是函数...”),但足以让我在脑海中看到它,就像一条被切成碎片并展开的绳子,没有重叠。 - Beta