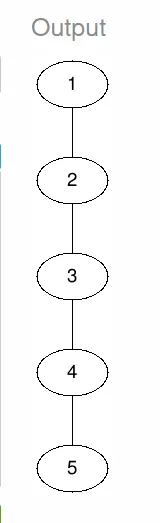
假设v是树T的一个节点,则节点v的深度可以定义如下:
- 如果节点v是根节点,则v的深度为1。
- 否则,节点v的深度为其父节点深度加1。
基于上述定义,下面的递归算法depth通过在v的父节点上递归调用自身,并将返回值加1,计算了树T中节点v的深度。
算法depth(T, y):
- 步骤1:如果
T.isRoot(v),则返回1 - 步骤2:否则,返回
1 + depth(T, T.parent(v))
一棵树T的高度等于其所有叶子节点中深度最大的节点的深度。虽然这个定义是正确的,但它并不会导致一个效率高的算法。事实上,如果我们将上述查找深度的算法应用于树T中的每个节点,我们将得到一个O(n2)时间复杂度的算法来计算T的高度。
按照上述语句,为什么时间复杂度是O(n2)?如果我们对每个叶子节点都尝试运行此算法,则需要O(n)的时间,找到最大值也需要O(n)的时间。因此总复杂度应该是O(n)+O(n)=O(2n)==O(n),对吗?