这个问题出现在我的算法课上。这是我的想法:
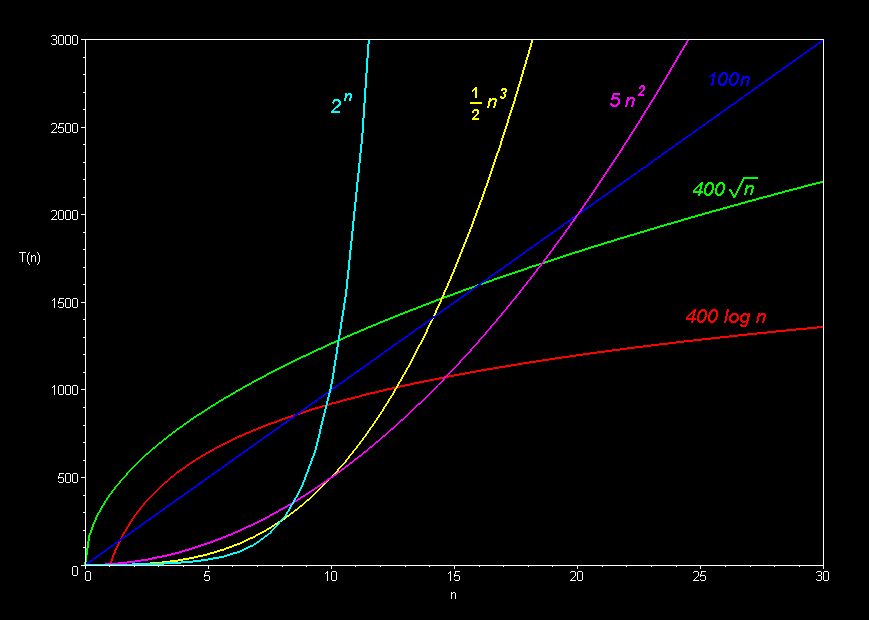
我认为答案是否定的,时间复杂度为O(n)的算法不总是比时间复杂度为O(n²)的算法更快。
例如,假设我们有总时间函数S(n) = 99999999n和T(n) = n²。显然,S(n) = O(n)且T(n) = O(n²),但对于所有n < 99999999,T(n)比S(n)更快。
这种推理是否有效?我稍微怀疑一下,因为尽管这是一个反例,但它可能是一个反对错误想法的反例。
非常感谢!
我认为答案是否定的,时间复杂度为O(n)的算法不总是比时间复杂度为O(n²)的算法更快。
例如,假设我们有总时间函数S(n) = 99999999n和T(n) = n²。显然,S(n) = O(n)且T(n) = O(n²),但对于所有n < 99999999,T(n)比S(n)更快。
这种推理是否有效?我稍微怀疑一下,因为尽管这是一个反例,但它可能是一个反对错误想法的反例。
非常感谢!