我听别人说,由于二分搜索将搜索所需的输入减半,因此它是O(log n)算法。由于我不是数学背景,我无法理解它。有人能详细解释一下吗?这与对数级数有关吗?
如何计算二分查找的复杂度
156
- Bunny Rabbit
1
1这可能对你有所帮助:https://dev59.com/q3E95IYBdhLWcg3wb9hb#13093274 - 2cupsOfTech
15个回答
437
这里有一种更数学的方式来理解,虽然并不复杂。在我看来比非正式的方式更清晰:
问题是,你可以将N除以2多少次直到得到1?这基本上意味着进行二进制搜索(减半),直到找到为止。用公式表示如下:
1 = N / 2x
乘以2x:
2x = N
现在做log2:
log2(2x) = log2 N
x * log2(2) = log2 N
x * 1 = log2 N
这意味着你可以将log N个数字分割成若干段,直到将所有数字都分割开为止。这意味着您必须对log N进行“二进制搜索步骤”,直到找到您的元素。
- duedl0r
7
1我刚刚计算出 t(n) = (2^2)*K。如何将其转换为对数形式? - Shan Khan
2相同的概念可以通过图形方式解释:https://dev59.com/q3E95IYBdhLWcg3wb9hb#13093274 - 2cupsOfTech
1比二叉树的解释容易多了。 - NoName
1非常好的答案。 - VHS
一个简单的例子总比一篇长文章更容易让我理解。 - Zhou Haibo
显示剩余2条评论
26
对于二分查找,T(N) = T(N/2) + O(1) // 递归关系
应用主定理计算递归关系的运行时间复杂度: T(N) = aT(N/b) + f(N)
在这里,a = 1,b = 2 => log (以 b 为底 a 的对数) = 1
此外,在这里 f(N) = n^c log^k(n) //k = 0 & c = log (以 b 为底 a 的对数)
因此,T(N) = O(N^c log^(k+1)N) = O(log(N))
来源:http://en.wikipedia.org/wiki/Master_theorem
应用主定理计算递归关系的运行时间复杂度: T(N) = aT(N/b) + f(N)
在这里,a = 1,b = 2 => log (以 b 为底 a 的对数) = 1
此外,在这里 f(N) = n^c log^k(n) //k = 0 & c = log (以 b 为底 a 的对数)
因此,T(N) = O(N^c log^(k+1)N) = O(log(N))
来源:http://en.wikipedia.org/wiki/Master_theorem
- abstractKarshit
2
1当a=1且b=2时,为什么log(以b为底a)等于1,而不是0? - GAURANG VYAS
它应该是零。因为1=n^0,所以c也是零。因此它是O(n^0 log n)= O(log(n))。 - mlanier
19
T(n)=T(n/2)+1
T(n/2)= T(n/4)+1+1
将T(n/2)的值代入上式,得到T(n)=T(n/4)+1+1......+1+1
=T(2^k/2^k)+1+1....+1(一直加到k次)
=T(1)+k
由于我们取了2^k=n,因此k=log n
因此,时间复杂度为O(log n)
- Dhiren Biren
12
它不仅减少搜索时间,而且减少的是对数。请想一想:如果你在一个有128个条目的表中进行线性搜索,并且需要寻找你的值,平均需要搜索大约64个条目,这就是n/2或线性时间。采用二分搜索法,每次迭代可以消除1/2的可能条目,最多只需要7次比较就可以找到你的值(以2为底的128的对数是7,即2的7次方等于128)。这就是二分搜索的威力。
- Michael Dorgan
4
抱歉打扰,但是128不是一个均匀填充的树。我使用了一个基本的例子来理解这个问题,我发现7个条目可以均匀地填满一棵有3层的树。我计算出复杂度应该是17/7(比较总和的平均值),即2.43。但是log2(7)是2.81。那么我错过了什么? - Perry Monschau
两个答案 - 第一个:即使在数学上没有错误,我们也可以看到2.43平均值比线性回归的3.5平均值要好,而且这只是一个低值。当你有成百上千的条目时,log2()比线性回归要好得多。我想你也看到了这一点,所以我们继续下一个。 - Michael Dorgan
1第二个答案:我不确定你所说的树是什么类型,其中7已经填满了所有内容。当我想到一个完美的8项条目的树时,我看到一个总共有8个叶子的3层深的树。在这棵树中,无论您搜索哪个数字,从根到叶子需要3次比较。对于7个条目,其中一条路径将少进行一次比较,因此为20/7(3次比较的6个节点,2次比较的1个节点),即约为2.85。Log2(7)约为2.81。我没有数学背景来解释0.04的差异,但我猜测这与没有可用的小数位或其他魔术有关 :) - Michael Dorgan
这个数字是叶子节点的数量?而不是节点的数量?哦,原来我一直缺失了这么重要的信息...我觉得很奇怪,因为每个分支节点也可以是潜在的停止点。无论如何,感谢你帮我澄清这个问题! - Perry Monschau
5
二分查找算法的时间复杂度属于O(log n)类。这被称为大O符号。你应该理解的方式是,给定大小为n的输入集合时,函数执行所需的时间的渐近增长不会超过log n。
这只是正式的数学术语,以便能够证明陈述等。它有一个非常简单的解释。当n变得非常大时,对数函数将超过执行函数所需的时间。"输入集"的大小n只是列表的长度。
简而言之,二分查找在O(log n)中的原因是每次迭代都将输入集减半。更容易地想象反向情况。在x次迭代中,二分查找算法最多可以检查多长的列表?答案是2^x。由此我们可以看出,反过来,对于长度为n的列表,平均需要log2 n次迭代。
如果问为什么是O(log n)而不是O(log2 n),那是因为再次简单地说 - 使用大O符号,常数不计算。
这只是正式的数学术语,以便能够证明陈述等。它有一个非常简单的解释。当n变得非常大时,对数函数将超过执行函数所需的时间。"输入集"的大小n只是列表的长度。
简而言之,二分查找在O(log n)中的原因是每次迭代都将输入集减半。更容易地想象反向情况。在x次迭代中,二分查找算法最多可以检查多长的列表?答案是2^x。由此我们可以看出,反过来,对于长度为n的列表,平均需要log2 n次迭代。
如果问为什么是O(log n)而不是O(log2 n),那是因为再次简单地说 - 使用大O符号,常数不计算。
- vidstige
5
假设二分查找的迭代在经过k次后终止。 每次迭代,数组都会被对半分割。因此,任何一次迭代时数组的长度是n。 在第一次迭代中,
Length of array = n
在第二次迭代中,
Length of array = n⁄2
在第3次迭代中,
Length of array = (n⁄2)⁄2 = n⁄22
因此,在第k次迭代之后,
Length of array = n⁄2k
此外,我们知道在进行k次分割之后,数组的长度会变为1。因此,
Length of array = n⁄2k = 1
=> n = 2k
对两侧应用对数函数:
=> log2 (n) = log2 (2k)
=> log2 (n) = k log2 (2)
As (loga (a) = 1)
因此,
As (loga (a) = 1)
k = log2 (n)
因此,二分查找的时间复杂度为
log2 (n)
- SirPhemmiey
4
应该有一种方法将您的答案发送到顶部。 - saran
更精确地说,在迭代
k 后,数组长度 = n⁄2^(k-1)。 - volperossa在两边应用对数函数:这个对数函数的想法从哪里来的? - John Doe
@saran - 我该怎么做呢? - SirPhemmiey
3
这里是维基百科的条目。
如果你看简单的迭代方法,你只需要消除一半的要搜索的元素,直到找到所需的元素。
我们来解释一下如何得出公式。
假设最初有N个元素,然后你先试着用⌊N/2⌋进行搜索。其中N是下限和上限的总和。第一次N的值将等于(L + H),其中L是要搜索的列表的第一个索引(0),而H是最后一个索引。如果你很幸运,在中间找到了要查找的元素[例如,你在列表{16, 17, 18, 19, 20}中搜索18,那么你计算⌊(0+4)/2⌋ = 2,其中0是下限(数组的第一个元素的索引L),4是上限(数组的最后一个元素的索引H)。在上面的例子中,L=0,H=4。现在2就是你要查找的元素18的索引。太棒了!你找到它了。
如果情况是不同的数组{15,16,17,18,19},但你仍在搜索18,那么你就没那么幸运了。你会执行第一个N/2(即⌊(0+4)/2⌋=2),然后意识到索引2处的元素17不是你要查找的那个数。现在你知道在下一次迭代搜索中,你至少不必再寻找数组的一半。你的搜索工作减少了一半。因此,每次尝试查找以前未能找到的元素时,你都不会再搜索之前搜索过的一半元素列表。
所以最坏的情况是
[N]/2 + [(N/2)]/2 + [((N/2)/2)]/2.....
即:
N/21 + N/22 + N/23 +..... + N/2x …..
直到...你完成搜索,在那里你要查找的元素位于列表的末尾。
这表明最坏的情况是当你达到N/2x时,其中x是2x=N的值。
在其他情况下,N/2x,其中x是2x<N的值。x的最小值可以是1,这是最好的情况。
现在,最坏的情况是数值为2x=N:
=> log2(2x) = log2(N)
=> x * log2(2) = log2(N)
=> x * 1 = log2(N)
=> 更正式地说,⌊log2(N)+1⌋
注意:此处保留了HTML标签。
- RajKon
2
1你如何获得更正式的版本? - Christian
使用了一个 floor 函数。详细信息请参见答案中提供的维基链接(https://en.wikipedia.org/wiki/Binary_search_algorithm)的性能部分。 - RajKon
3
在二分查找中,需要进行的最大比较次数是⌊log₂(n) + 1⌋。平均情况下,需要进行约log₂(n) - 1次比较。以下链接提供更多信息:
- Jonathan M
2
以下是使用主定理解决二分查找的方案,并且带有易读的LaTeX。
对于二分查找的递归关系中的每个递归,我们将问题转化为一个子问题,其运行时间为T(N/2)。因此:
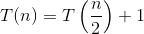
代入主定理中,我们得到:
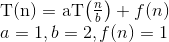
现在,因为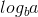 为0,而f(n)为1,我们可以使用主定理的第二种情况,因为:
为0,而f(n)为1,我们可以使用主定理的第二种情况,因为:
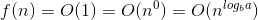
这意味着:
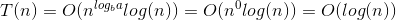
- id01
1
T(N) = T(N/2) + 1
意思是:T(N)等于T(N/2)加1。T(N) = T(N/2) + 1 = (T(N/4) + 1)+ 1
意思是:T(N)等于T(N/2)加1,而T(N/2)又等于T(N/4)加1,所以T(N)等于T(N/4)加2。...
T(N) = T(N/N) + (1 + 1 + 1 +... + 1) = 1 + logN (以2为底的对数) = 1 + logN
因此,二分查找的时间复杂度为O(logN)
- TizeeU0U
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接