我有一个CSV文件,其格式我无法更改。该文件具有多级索引:两行标题。第一行(更高级别的索引)在值不变时为空白。
我得到的列表“l”似乎是我想要的:
这个代码可以给出正确的索引,但数值消失了。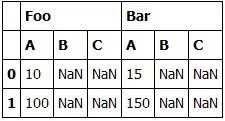 我强烈感觉自己的方法不够Pythonic,也没有将列表转换为字典的意义。有什么办法可以正确地使用多重索引?
我强烈感觉自己的方法不够Pythonic,也没有将列表转换为字典的意义。有什么办法可以正确地使用多重索引?
我的标题看起来像:
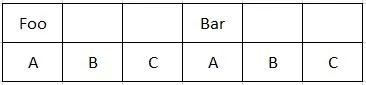
实际上是这样的,而我想要的是:
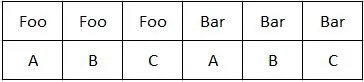
我希望能够使用Python 2.7和Pandas正确处理它。
我决定在索引的第一级上循环,如果值为空白,则将其设置为左侧相同的值。
我首先在Pandas中加载数据框:
df = pd.read_csv(myFile, header=[0,1], sep=',')
df

我尝试了以下方法:
for i, val in enumerate(df.columns.values):
if val[0][:7] == 'Unnamed':
l.append([l[i-1][0], val[1]])
else:
l.append(val)
我得到的列表“l”似乎是我想要的:
[('Foo', 'A'),
['Foo', 'B'],
['Foo', 'C'],
('Bar', 'A'),
['Bar', 'B'],
['Bar', 'C']]
我尝试过以下两种方法:
df.columns = l
生成一个非多级索引的数据框
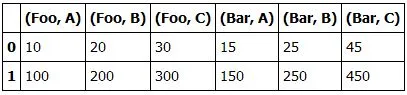
index = pd.MultiIndex.from_tuples(l)
df.reindex(columns = index)
这个代码可以给出正确的索引,但数值消失了。
我强烈感觉自己的方法不够Pythonic,也没有将列表转换为字典的意义。有什么办法可以正确地使用多重索引?