我认为RANSAC应该随机选择一部分点进行拟合,那么为什么它每次都返回相同的变换矩阵?
RANSAC会
反复选择一部分点,然后基于这些点进行模型拟合,然后检查在给定该拟合模型的情况下,数据集中有多少数据点是内点。一旦完成了许多次这样的操作,它就会选择具有最多内点的拟合模型,并将模型重新拟合到这些内点上。
对于任何给定的数据集、可变模型参数集和构成内点的规则,都会存在一个或多个(但通常只有一个)最大可能的“内点”集。例如,给定这个数据集(来自维基百科的
图像)。

...然后通过一些合理的异常值定义,任何线性模型可能具有的最大内点集是下面的蓝色集合:
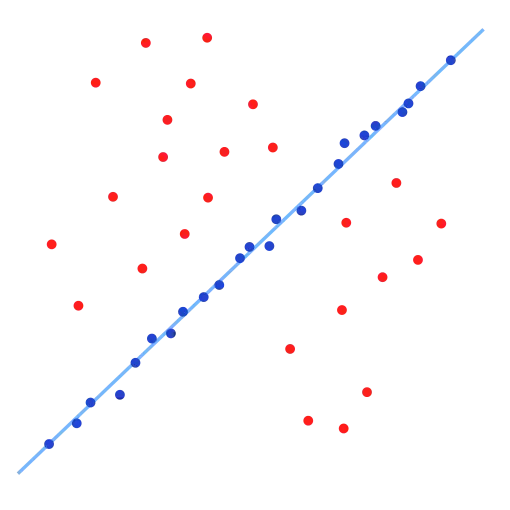
让我们称上面的蓝点集为最大可能的内点集合 -
I。
如果您随机选择少量点(例如两个或三个),并通过它们绘制最佳拟合线,那么很明显,只需要几次尝试就可以达到以下迭代:
- 所有随机选择的点都来自
I,因此
- 通过这些点的最佳拟合线大致等于上图中的最佳拟合线,因此
- 在该迭代中找到的内点集合正好是
I
从那一次迭代开始,所有进一步的迭代都是无用的,不能进一步改善模型(尽管RANSAC不知道何时找到了最大的内点集合)。
如果您拥有足够数量的迭代次数相对于数据集的大小,并且足够大比例的数据集是内点,则每次运行RANSAC时您最终都将以接近100%的概率找到最大的内点集。因此,RANSAC将(几乎)总是输出完全相同的模型。
这是一件好事情!通常,您希望RANSAC找到绝对最大的内点集,不想妥协。如果在这种情况下每次运行RANSAC都得到不同的结果,则表明您需要增加迭代次数。
(当然,在上面的情况下,我们谈论的是尝试通过2D平面中的点拟合一条线,而这不是findHomography所做的,但原理是相同的;通常仍会有一个单一的最大内点集,最终RANSAC将找到它。)
如何使此行为实际随机?
减少迭代次数(maxIters),以便RANSAC有时无法找到最大的内点集。
但是除了纯粹的学术好奇心外,通常没有理由这样做;您基本上正在故意告诉RANSAC输出较差的模型。