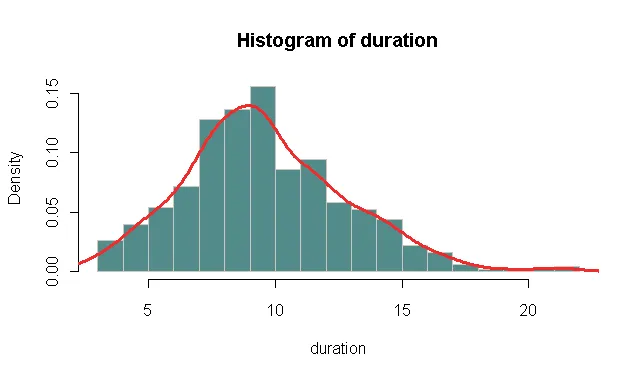
我需要分析关于DSL线路的互联网会话数据。我想查看会话持续时间的分布情况。我想到一个简单的方法是首先制作所有会话持续时间的概率密度图。
我已经在R中加载了数据并使用了`density()`函数,代码如下:
我是新手,对R和这种分析一窍不通。通过谷歌搜索,我找到了以下内容。我得到了一个图表,但是还有一些问题。这个函数是我想要做的正确函数吗?还是有其他的函数?
在图表中,我发现Y轴刻度从0到1.5。我不明白为什么是1.5,难道不应该是从0到1吗?
此外,我想获得更平滑的曲线。由于数据集非常大,所以线条非常粗糙。在展示时将它们平滑处理会更好。我该如何做呢?
我已经在R中加载了数据并使用了`density()`函数,代码如下:
plot(density(data$duration), type = "l", col = "blue", main = "Density Plot of Duration",
xlab = "duration(h)", ylab = "probability density")
我是新手,对R和这种分析一窍不通。通过谷歌搜索,我找到了以下内容。我得到了一个图表,但是还有一些问题。这个函数是我想要做的正确函数吗?还是有其他的函数?
在图表中,我发现Y轴刻度从0到1.5。我不明白为什么是1.5,难道不应该是从0到1吗?
此外,我想获得更平滑的曲线。由于数据集非常大,所以线条非常粗糙。在展示时将它们平滑处理会更好。我该如何做呢?