在R中是否可以生成已知平均数、标准差、偏度和峰度的分布?目前看来最好的方法是创建随机数并相应地进行转换。
如果有专门用于生成特定分布的软件包可供使用,我尚未找到。
谢谢。
在R中是否可以生成已知平均数、标准差、偏度和峰度的分布?目前看来最好的方法是创建随机数并相应地进行转换。
如果有专门用于生成特定分布的软件包可供使用,我尚未找到。
谢谢。
在SuppDists软件包中有一个Johnson分布。Johnson会为您提供与矩或分位数匹配的分布。其他评论正确指出,只有4个矩不能确定一个分布。但是Johnson肯定会尝试。
这里有一个将Johnson拟合到一些样本数据的示例:
require(SuppDists)
## make a weird dist with Kurtosis and Skew
a <- rnorm( 5000, 0, 2 )
b <- rnorm( 1000, -2, 4 )
c <- rnorm( 3000, 4, 4 )
babyGotKurtosis <- c( a, b, c )
hist( babyGotKurtosis , freq=FALSE)
## Fit a Johnson distribution to the data
## TODO: Insert Johnson joke here
parms<-JohnsonFit(babyGotKurtosis, moment="find")
## Print out the parameters
sJohnson(parms)
## add the Johnson function to the histogram
plot(function(x)dJohnson(x,parms), -20, 20, add=TRUE, col="red")
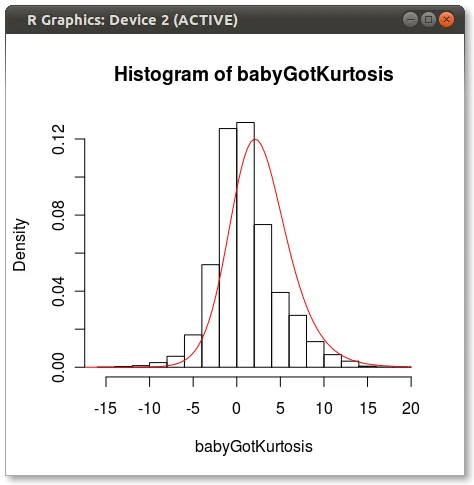
您可以看到其他人指出的问题,即四个矩无法完全捕捉分布的一些方面。
祝好运!
编辑 由于Hadley在评论中指出约翰逊拟合不准确。我做了一个快速测试,并使用 moment="quant" 拟合Johnson分布,该方法使用5个分位数而不是4个矩来拟合约翰逊分布。结果看起来好多了:
parms<-JohnsonFit(babyGotKurtosis, moment="quant")
plot(function(x)dJohnson(x,parms), -20, 20, add=TRUE, col="red")
以下是生成的内容:
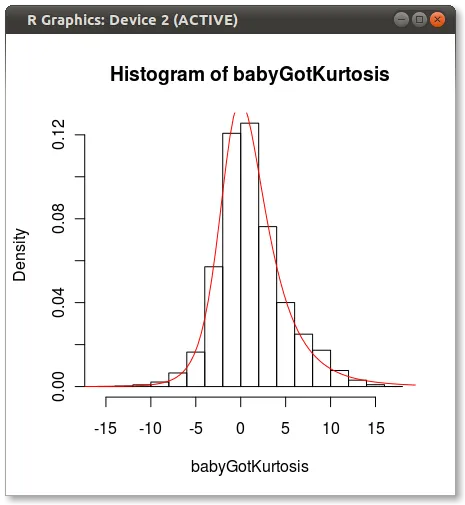
有人想知道为什么使用矩进行拟合时,Johnson似乎存在偏差?
这是一个有趣的问题,没有一个很好的解决方案。我假设即使你不知道其他时刻的分布情况,你也知道分布应该长什么样子,例如呈单峰分布。
有几种不同的方法可以解决这个问题:
假设一个潜在的分布并匹配时刻。有许多标准的R软件包可以做到这一点。缺点是多元一般化可能不清楚。
鞍点逼近。在这篇论文中:
Gillespie,C.S.和Renshaw,E。 An improved saddlepoint approximation. Mathematical Biosciences,2007。
当偏度不太大时,我们研究了在只给出前几个时刻时恢复pdf/pmf的情况。我们发现这种方法是可行的。
Laguerre扩展:
Mustapha,H.和Dimitrakopoulosa,R. Generalized Laguerre expansions of multivariate probability densities with moments。计算机与应用数学,2010。
这篇论文中的结果似乎更为有前途,但我还没有编写出来。
你可能需要使用PearsonDS库。它允许你使用前四个矩中的组合,但是峰度必须大于偏度的平方加1。
要从该分布生成10个随机值,请尝试:
library("PearsonDS")
moments <- c(mean = 0,variance = 1,skewness = 1.5, kurtosis = 4)
rpearson(10, moments = moments)
这个问题被问了三年多,所以我希望我的回答不会太晚。
在知道一些矩的情况下,有一种方法可以唯一地确定一个分布。那就是最大熵方法。从该方法得出的分布是最大化您对分布结构的无知,在您已知情况下。任何其他也具有您指定的矩但不是最大熵分布的分布都隐含着比您输入的更多的结构。要最大化的函数是Shannon的信息熵,$S[p(x)] = - \int p(x)log p(x) dx$。知道均值、标准差、偏度和峰度,分别转化为约束条件的第一、二、三和四个矩。
问题在于,然后在约束条件下最大化S:
1)$\int x p(x) dx = "第一矩"$, 2)$\int x^2 p(x) dx = "第二矩"$, 3)...等等
我推荐书籍《Harte, J., Maximum Entropy and Ecology: A Theory of Abundance, Distribution, and Energetics (Oxford University Press, New York, 2011)》。
这里是一个尝试在R中实现此方法的链接: https://stats.stackexchange.com/questions/21173/max-entropy-solver-in-r
这些参数并不能完全定义一个分布。为此,您需要密度或等价的分布函数。
正如@David和@Carl在上面所写的,有几个专门用于生成不同分布的软件包,例如请参阅CRAN上的概率分布任务视图。
如果您对理论感兴趣(如何绘制符合给定参数的特定分布的数字样本),那么只需寻找适当的公式,例如请参阅维基上的伽马分布,并使用提供的参数构建一个简单的质量系统来计算比例和形状。
请参见此处的具体示例,我根据平均值和标准差计算了所需beta分布的alpha和beta参数。