我一直在尝试使用spaCy获取依赖树,但我找不到如何获取树的任何信息,只能在如何浏览树方面找到一些内容。
9个回答
88
如果有人想要轻松查看spacy生成的依赖树,一种解决方案是将其转换为nltk.tree.Tree并使用nltk.tree.Tree.pretty_print方法。以下是一个示例:
import spacy
from nltk import Tree
en_nlp = spacy.load('en')
doc = en_nlp("The quick brown fox jumps over the lazy dog.")
def to_nltk_tree(node):
if node.n_lefts + node.n_rights > 0:
return Tree(node.orth_, [to_nltk_tree(child) for child in node.children])
else:
return node.orth_
[to_nltk_tree(sent.root).pretty_print() for sent in doc.sents]
输出:
jumps
________________|____________
| | | | | over
| | | | | |
| | | | | dog
| | | | | ___|____
The quick brown fox . the lazy
编辑: 如果您要更改令牌表示形式,可以这样做:
def tok_format(tok):
return "_".join([tok.orth_, tok.tag_])
def to_nltk_tree(node):
if node.n_lefts + node.n_rights > 0:
return Tree(tok_format(node), [to_nltk_tree(child) for child in node.children])
else:
return tok_format(node)
导致结果如下:
jumps_VBZ
__________________________|___________________
| | | | | over_IN
| | | | | |
| | | | | dog_NN
| | | | | _______|_______
The_DT quick_JJ brown_JJ fox_NN ._. the_DT lazy_JJ
- Christos Baziotis
4
4我认为保留Spacy中的依赖关系和词性标注非常重要。 - Krzysiek
干得好!有没有一种简单的方法在两个节点之间添加依赖标签? - David Batista
4看一下我的修改。如果你想给树增加其他内容,可以编辑
tok_format(tok)。此外,你应该阅读文档。Spacy使用两种不同的词性表示方法 tok.pos_ 和 tok.tag_。https://spacy.io/docs/#token-postags - Christos Baziotis4
tok.dep_ 属性可与 tok.tag_ 一起使用,表示句法依存关系。 - Shirish Kadam66
这棵树本身不是一个对象;你只能通过标记之间的关系来浏览它。这就是为什么文档中谈论如何导航树,而不是“获取”它。
首先,让我们解析一些文本以获取Doc对象:
>>> import spacy
>>> nlp = spacy.load('en_core_web_sm')
>>> doc = nlp('First, I wrote some sentences. Then spaCy parsed them. Hooray!')
doc 是一个 Sequence 类型的 Token 对象集合:
>>> doc[0]
First
>>> doc[1]
,
>>> doc[2]
I
>>> doc[3]
wrote
但它没有一个根节点。我们解析了由三个句子组成的文本,因此有三个不同的树,每个树都有自己的根。如果我们想从每个句子的根开始解析,首先需要将句子作为不同的对象获取。幸运的是,doc通过 .sents 属性向我们公开了这些对象:
>>> sentences = list(doc.sents)
>>> for sentence in sentences:
... print(sentence)
...
First, I wrote some sentences.
Then spaCy parsed them.
Hooray!
每个句子都是一个带有
.root属性指向其根标记的Span。通常,根标记将是句子的主要动词(尽管对于不寻常的句子结构,如没有动词的句子,这可能不是真实的)。>>> for sentence in sentences:
... print(sentence.root)
...
wrote
parsed
Hooray
有了根令牌,我们可以通过每个令牌的
.children属性向下遍历树。例如,让我们找到第一句话中动词的主语和宾语。每个子令牌的.dep_属性描述其与父级的关系;例如,'nsubj'的dep_表示一个令牌是其父级的名义主语。>>> root_token = sentences[0].root
>>> for child in root_token.children:
... if child.dep_ == 'nsubj':
... subj = child
... if child.dep_ == 'dobj':
... obj = child
...
>>> subj
I
>>> obj
sentences
我们也可以通过查看这些标记的子节点来继续向下遍历树形结构:
>>> list(obj.children)
[some]
因此,具有上述属性,您可以浏览整个树。如果您想将某些依赖关系树可视化为例句以帮助您理解结构,则建议尝试使用displaCy。
- Mark Amery
26
您可以使用下面的库来查看您的依赖树,发现它非常有帮助!
你可以使用下面的库来查看你的依赖树,发现它非常有帮助!
import spacy
from spacy import displacy
nlp = spacy.load('en')
doc = nlp(u'This is a sentence.')
displacy.serve(doc, style='dep')
您可以使用浏览器打开它,它看起来像: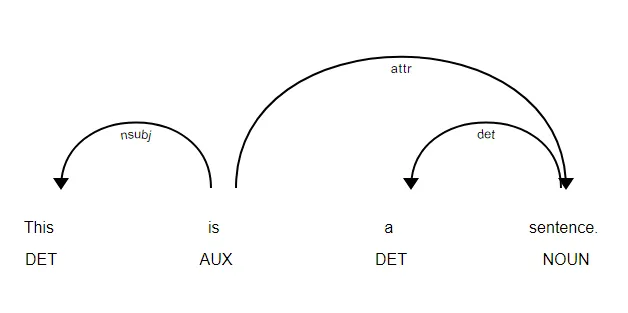
要生成SVG文件:
from pathlib import Path
output_path = Path("yourpath/.svg")
svg = displacy.render(doc, style='dep')
with output_path.open("w", encoding="utf-8") as fh:
fh.write(svg)
- Rohan
3
3JFI.. serve选项还将树形图作为网页链接打开。对于静态图像(可以使用'render'选项
displacy.render(doc, style='dep'))。 - prashanth2补充@prashanth的评论,您还可以打印到图像(您可以在Firefox中打开/查看,例如,请注意您需要指定完整路径(
/home/victoria/...而不是~/...)。 代码:from pathlib import Path; output_path = Path("/home/victoria/dependency_plot.svg"); svg = displacy.render(doc, style='dep', jupyter=False); output_path.open("w", encoding="utf-8").write(svg) - Victoria Stuart奇怪的是,当我以svg格式渲染时,依赖标签会消失,但当我使用
serve渲染时,它们会被打印出来。 - Suzana9
我不确定这是否是一个新的API调用,但Document类上有一个.print_tree()方法可以快速处理此操作。它将依赖树转储为JSON格式,并处理多个句子根节点等情况。
https://spacy.io/api/doc#print_tree
import spacy
nlp = spacy.load('en')
doc1 = nlp(u'This is the way the world ends. So you say.')
print(doc1.print_tree(light=True))
print_tree这个名称有点不准确,因为该方法本身并不打印任何内容,而是返回一个包含每个句子的字典列表。
- Christopher Reiss
1
10Doc.print_tree方法在v2.1中已被弃用,建议使用Doc.to_json方法代替。 - Viper
6
我也需要这样做,下面是完整代码:
import sys
def showTree(sent):
def __showTree(token):
sys.stdout.write("{")
[__showTree(t) for t in token.lefts]
sys.stdout.write("%s->%s(%s)" % (token,token.dep_,token.tag_))
[__showTree(t) for t in token.rights]
sys.stdout.write("}")
return __showTree(sent.root)
如果您想要终端的间距:
def showTree(sent):
def __showTree(token, level):
tab = "\t" * level
sys.stdout.write("\n%s{" % (tab))
[__showTree(t, level+1) for t in token.lefts]
sys.stdout.write("\n%s\t%s [%s] (%s)" % (tab,token,token.dep_,token.tag_))
[__showTree(t, level+1) for t in token.rights]
sys.stdout.write("\n%s}" % (tab))
return __showTree(sent.root, 1)
- Krzysiek
1
我刚刚添加了一个打印模块,以及匹配树(或查找节点)的正则表达式模式。如果您感兴趣,这是链接:
https://github.com/krzysiekfonal/grammaregex它目前还不能直接安装,但本周应该会完成,并通过pip提供。 - Krzysiek
1
虽然spaCy库在过去的5年中可能有所改变,但@Mark Amery的方法非常有效。这是我一直在做的事情,以便在大量文本中分解句子,以获取名义上描述的特征以及与它们相关联的NP或VP。我们采取的另一种方法(可能在过去5年中已经出现在SpaCy中)...如果您查看短语中的根VB,并注意dep类型,该根的祖先和祖先的子项,您基本上会找到指向主题、对象和根的头部。您可以将它们分成修饰语从句,这些从句基于同位语或连词等来告诉您这些从句是否是对特征描述的补充还是核心。有了这个,您可以重写句子,我主要是为了剥离多余的内容并创建由硬细节组成的片段。不知道是否对其他人有帮助,但这是我在纸上绘制nsubj、dobj、conjuncts和pobjs几周后,与SpaCy的基于张量的建模进行比较后遵循的策略。在我看来,值得注意的是,SpaCy完成的标记似乎总是100%正确的-每次都是如此,即使片段相隔20个单词,而且写得非常糟糕。我从来没有对其输出产生过任何怀疑-这显然是无价的。
- chuckjones242
0
这段代码可以用来读取Spacy依存句法树;
import numpy as np
import spacy
rootNodeName = "ROOT"
class ParseNode:
def __init__(self, token, w):
self.word = token.text
self.w = w #or token.i
self.governor = None
self.dependentList = []
self.parseLabel = None
def generateSentenceParseNodeList(tokenizedSentence):
sentenceParseNodeList = []
for w, token in enumerate(tokenizedSentence):
print("add parseNode: w = ", w, ": text = ", token.text)
parseNode = ParseNode(token, w)
sentenceParseNodeList.append(parseNode)
return sentenceParseNodeList
def generateDependencyParseTree(tokenizedSentence, sentenceParseNodeList):
parseTreeHeadNode = None
for w, tokenDependent in enumerate(tokenizedSentence):
parseNodeDependent = sentenceParseNodeList[tokenDependent.i]
print("add dependency relation: tokenDependent w = ", w, ": text = ", tokenDependent.text, ", i = ", tokenDependent.i, ", tag_ = ", tokenDependent.tag_, ", head.text = ", tokenDependent.head.text, ", dep_ = ", tokenDependent.dep_)
if(tokenDependent.dep_ == rootNodeName):
parseTreeHeadNode = parseNodeDependent
else:
tokenGovernor = tokenDependent.head
parseNodeGovernor = sentenceParseNodeList[tokenGovernor.i]
parseNodeDependent.governor = parseNodeGovernor
parseNodeGovernor.dependentList.append(parseNodeDependent)
parseNodeDependent.parseLabel = tokenDependent.dep_
return parseTreeHeadNode
nlp = spacy.load('en_core_web_md')
text = "This is an example sentence."
tokenizedSentence = nlp(text)
sentenceParseNodeList = generateSentenceParseNodeList(tokenizedSentence)
parseTreeHeadNode = generateDependencyParseTree(tokenizedSentence, sentenceParseNodeList)
- user2585501
-2
我还不太了解解析方面的知识。然而,我的文献研究结果表明,spaCy具有一种移位-规约依赖解析算法。这个算法解析问题/句子,产生一个解析树。为了可视化这个过程,你可以使用DisplaCy,这是一个CSS和Javascript的结合,可以与Python和Cython一起工作。此外,你可以使用SpaCy库进行解析,并导入自然语言工具包(NLTK)。希望这可以帮助到你。
- lilienfa
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
- 相关问题
- 7 使用Displacy (Python)可视化依存关系解析
- 74 spaCy的词性标注和依存关系标注是什么意思?
- 18 SpaCy:如何获取spacy模型名称?
- 3 如何使用nltk或spacy从括号解析字符串中获取解析NLP树对象?
- 3 如何获取旧版的Spacy模型?
- 9 如何使用Spacy解析动词
- 20 如何获取spaCy NER概率
- 7 SpaCy:如何从字符索引获取标记
- 4 如何在Python中使用Spacy依赖树获取祖先的子节点?涉及到IT技术相关内容。
- 4 为什么 spaCy 依存关系符号定义中的“case”和“compound”不像 spacy.symbols 包中的“nsubj”那样被识别?