spaCy在其源代码中有一个词汇表,它将标记代码映射到标记标签,用于其POS标记、句法类别、短语类型、依赖标签等。
它非常广泛,包括多个框架(例如通用依赖关系、Penn Treebank等),并支持多种语言。
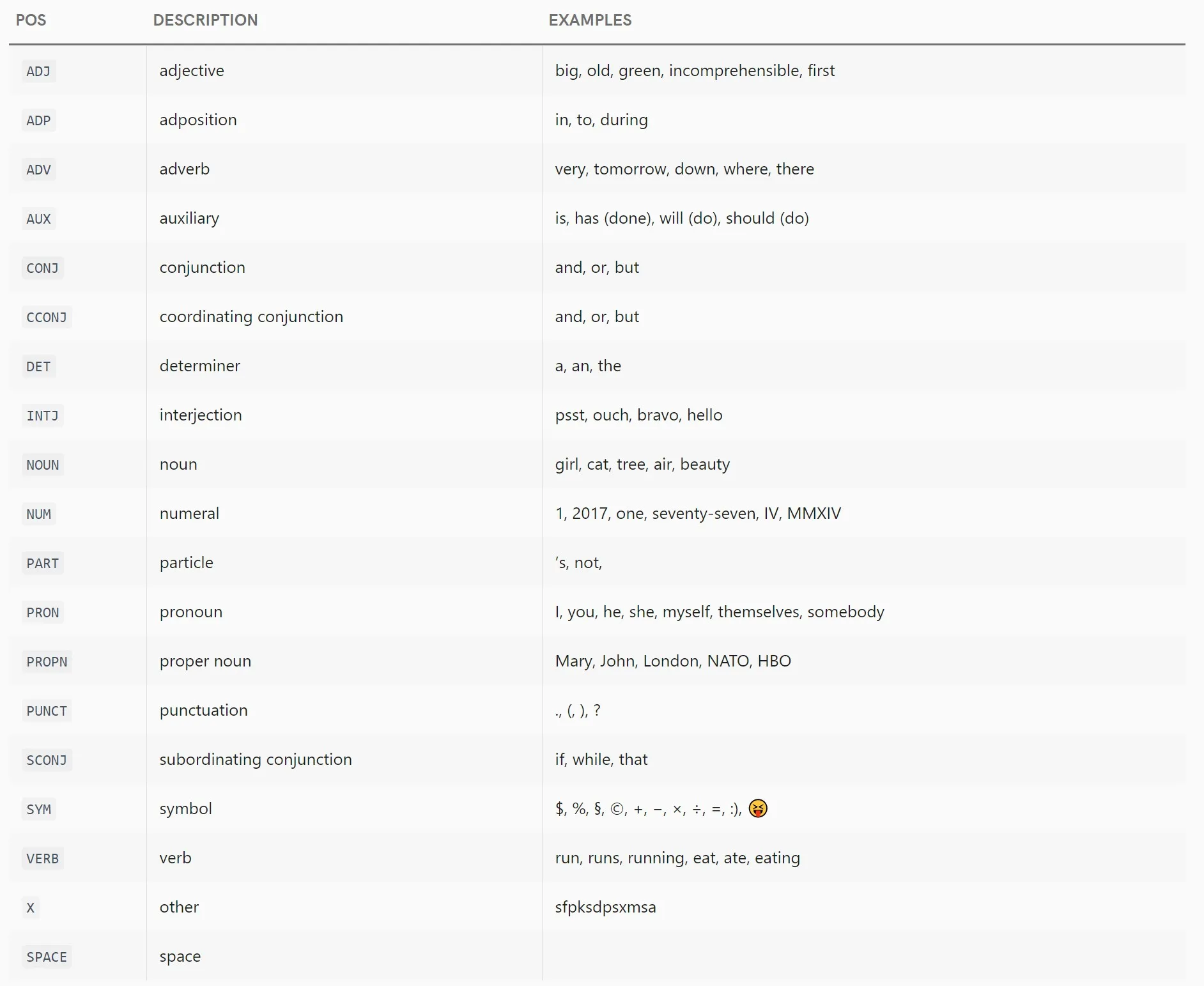
GLOSSARY = {
"ADJ": "adjective",
"ADP": "adposition",
"ADV": "adverb",
"AUX": "auxiliary",
"CONJ": "conjunction",
"CCONJ": "coordinating conjunction",
"DET": "determiner",
"INTJ": "interjection",
"NOUN": "noun",
"NUM": "numeral",
"PART": "particle",
"PRON": "pronoun",
"PROPN": "proper noun",
"PUNCT": "punctuation",
"SCONJ": "subordinating conjunction",
"SYM": "symbol",
"VERB": "verb",
"X": "other",
"EOL": "end of line",
"SPACE": "space",
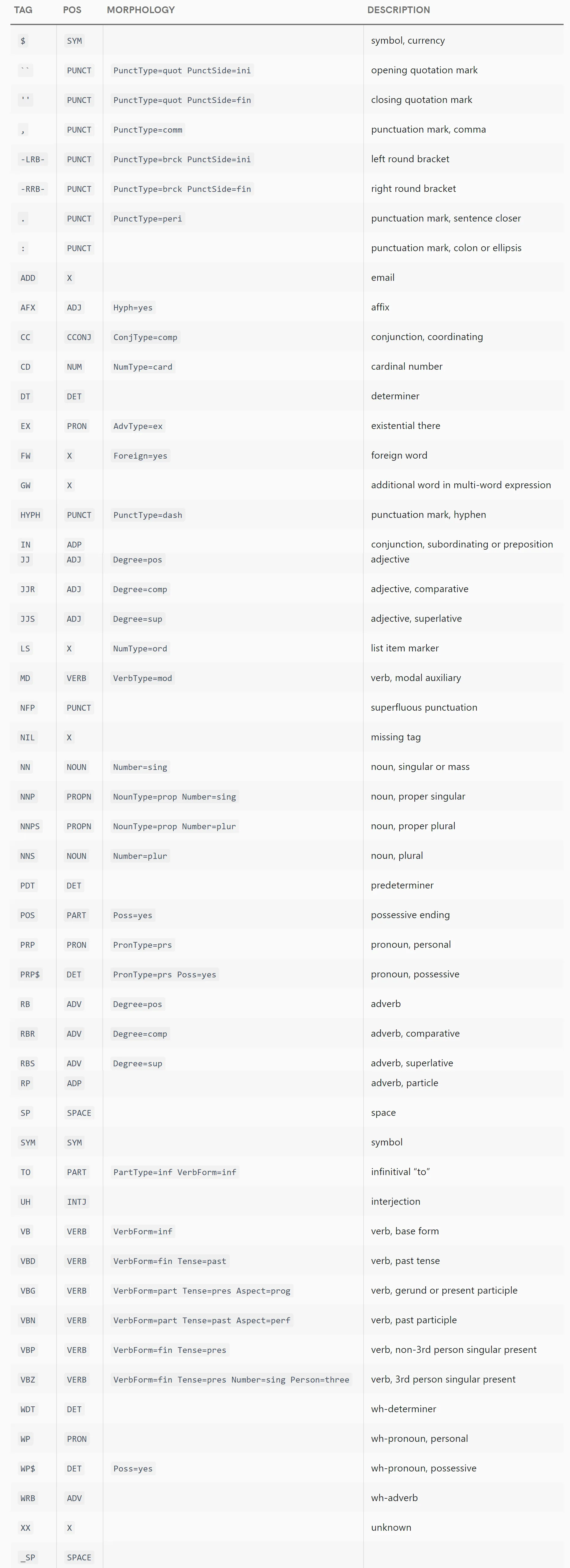
".": "punctuation mark, sentence closer",
",": "punctuation mark, comma",
"-LRB-": "left round bracket",
"-RRB-": "right round bracket",
"``": "opening quotation mark",
'""': "closing quotation mark",
"''": "closing quotation mark",
":": "punctuation mark, colon or ellipsis",
"$": "symbol, currency",
"#": "symbol, number sign",
"AFX": "affix",
"CC": "conjunction, coordinating",
"CD": "cardinal number",
"DT": "determiner",
"EX": "existential there",
"FW": "foreign word",
"HYPH": "punctuation mark, hyphen",
"IN": "conjunction, subordinating or preposition",
"JJ": "adjective (English), other noun-modifier (Chinese)",
"JJR": "adjective, comparative",
"JJS": "adjective, superlative",
"LS": "list item marker",
"MD": "verb, modal auxiliary",
"NIL": "missing tag",
"NN": "noun, singular or mass",
"NNP": "noun, proper singular",
"NNPS": "noun, proper plural",
"NNS": "noun, plural",
"PDT": "predeterminer",
"POS": "possessive ending",
"PRP": "pronoun, personal",
"PRP$": "pronoun, possessive",
"RB": "adverb",
"RBR": "adverb, comparative",
"RBS": "adverb, superlative",
"RP": "adverb, particle",
"TO": 'infinitival "to"',
"UH": "interjection",
"VB": "verb, base form",
"VBD": "verb, past tense",
"VBG": "verb, gerund or present participle",
"VBN": "verb, past participle",
"VBP": "verb, non-3rd person singular present",
"VBZ": "verb, 3rd person singular present",
"WDT": "wh-determiner",
"WP": "wh-pronoun, personal",
"WP$": "wh-pronoun, possessive",
"WRB": "wh-adverb",
"SP": "space (English), sentence-final particle (Chinese)",
"ADD": "email",
"NFP": "superfluous punctuation",
"GW": "additional word in multi-word expression",
"XX": "unknown",
"BES": 'auxiliary "be"',
"HVS": 'forms of "have"',
"_SP": "whitespace",
"$(": "other sentence-internal punctuation mark",
"$,": "comma",
"$.": "sentence-final punctuation mark",
"ADJA": "adjective, attributive",
"ADJD": "adjective, adverbial or predicative",
"APPO": "postposition",
"APPR": "preposition; circumposition left",
"APPRART": "preposition with article",
"APZR": "circumposition right",
"ART": "definite or indefinite article",
"CARD": "cardinal number",
"FM": "foreign language material",
"ITJ": "interjection",
"KOKOM": "comparative conjunction",
"KON": "coordinate conjunction",
"KOUI": 'subordinate conjunction with "zu" and infinitive',
"KOUS": "subordinate conjunction with sentence",
"NE": "proper noun",
"NNE": "proper noun",
"PAV": "pronominal adverb",
"PROAV": "pronominal adverb",
"PDAT": "attributive demonstrative pronoun",
"PDS": "substituting demonstrative pronoun",
"PIAT": "attributive indefinite pronoun without determiner",
"PIDAT": "attributive indefinite pronoun with determiner",
"PIS": "substituting indefinite pronoun",
"PPER": "non-reflexive personal pronoun",
"PPOSAT": "attributive possessive pronoun",
"PPOSS": "substituting possessive pronoun",
"PRELAT": "attributive relative pronoun",
"PRELS": "substituting relative pronoun",
"PRF": "reflexive personal pronoun",
"PTKA": "particle with adjective or adverb",
"PTKANT": "answer particle",
"PTKNEG": "negative particle",
"PTKVZ": "separable verbal particle",
"PTKZU": '"zu" before infinitive',
"PWAT": "attributive interrogative pronoun",
"PWAV": "adverbial interrogative or relative pronoun",
"PWS": "substituting interrogative pronoun",
"TRUNC": "word remnant",
"VAFIN": "finite verb, auxiliary",
"VAIMP": "imperative, auxiliary",
"VAINF": "infinitive, auxiliary",
"VAPP": "perfect participle, auxiliary",
"VMFIN": "finite verb, modal",
"VMINF": "infinitive, modal",
"VMPP": "perfect participle, modal",
"VVFIN": "finite verb, full",
"VVIMP": "imperative, full",
"VVINF": "infinitive, full",
"VVIZU": 'infinitive with "zu", full',
"VVPP": "perfect participle, full",
"XY": "non-word containing non-letter",
"AD": "adverb",
"AS": "aspect marker",
"BA": "把 in ba-construction",
"CS": "subordinating conjunction",
"DEC": "的 in a relative clause",
"DEG": "associative 的",
"DER": "得 in V-de const. and V-de-R",
"DEV": "地 before VP",
"ETC": "for words 等, 等等",
"IJ": "interjection",
"LB": "被 in long bei-const",
"LC": "localizer",
"M": "measure word",
"MSP": "other particle",
"NR": "proper noun",
"NT": "temporal noun",
"OD": "ordinal number",
"ON": "onomatopoeia",
"P": "preposition excluding 把 and 被",
"PN": "pronoun",
"PU": "punctuation",
"SB": "被 in short bei-const",
"VA": "predicative adjective",
"VC": "是 (copula)",
"VE": "有 as the main verb",
"VV": "other verb",
"NP": "noun phrase",
"PP": "prepositional phrase",
"VP": "verb phrase",
"ADVP": "adverb phrase",
"ADJP": "adjective phrase",
"SBAR": "subordinating conjunction",
"PRT": "particle",
"PNP": "prepositional noun phrase",
"acl": "clausal modifier of noun (adjectival clause)",
"acomp": "adjectival complement",
"advcl": "adverbial clause modifier",
"advmod": "adverbial modifier",
"agent": "agent",
"amod": "adjectival modifier",
"appos": "appositional modifier",
"attr": "attribute",
"aux": "auxiliary",
"auxpass": "auxiliary (passive)",
"case": "case marking",
"cc": "coordinating conjunction",
"ccomp": "clausal complement",
"clf": "classifier",
"complm": "complementizer",
"compound": "compound",
"conj": "conjunct",
"cop": "copula",
"csubj": "clausal subject",
"csubjpass": "clausal subject (passive)",
"dative": "dative",
"dep": "unclassified dependent",
"det": "determiner",
"discourse": "discourse element",
"dislocated": "dislocated elements",
"dobj": "direct object",
"expl": "expletive",
"fixed": "fixed multiword expression",
"flat": "flat multiword expression",
"goeswith": "goes with",
"hmod": "modifier in hyphenation",
"hyph": "hyphen",
"infmod": "infinitival modifier",
"intj": "interjection",
"iobj": "indirect object",
"list": "list",
"mark": "marker",
"meta": "meta modifier",
"neg": "negation modifier",
"nmod": "modifier of nominal",
"nn": "noun compound modifier",
"npadvmod": "noun phrase as adverbial modifier",
"nsubj": "nominal subject",
"nsubjpass": "nominal subject (passive)",
"nounmod": "modifier of nominal",
"npmod": "noun phrase as adverbial modifier",
"num": "number modifier",
"number": "number compound modifier",
"nummod": "numeric modifier",
"oprd": "object predicate",
"obj": "object",
"obl": "oblique nominal",
"orphan": "orphan",
"parataxis": "parataxis",
"partmod": "participal modifier",
"pcomp": "complement of preposition",
"pobj": "object of preposition",
"poss": "possession modifier",
"possessive": "possessive modifier",
"preconj": "pre-correlative conjunction",
"prep": "prepositional modifier",
"prt": "particle",
"punct": "punctuation",
"quantmod": "modifier of quantifier",
"rcmod": "relative clause modifier",
"relcl": "relative clause modifier",
"reparandum": "overridden disfluency",
"root": "root",
"ROOT": "root",
"vocative": "vocative",
"xcomp": "open clausal complement",
"ac": "adpositional case marker",
"adc": "adjective component",
"ag": "genitive attribute",
"ams": "measure argument of adjective",
"app": "apposition",
"avc": "adverbial phrase component",
"cd": "coordinating conjunction",
"cj": "conjunct",
"cm": "comparative conjunction",
"cp": "complementizer",
"cvc": "collocational verb construction",
"da": "dative",
"dh": "discourse-level head",
"dm": "discourse marker",
"ep": "expletive es",
"hd": "head",
"ju": "junctor",
"mnr": "postnominal modifier",
"mo": "modifier",
"ng": "negation",
"nk": "noun kernel element",
"nmc": "numerical component",
"oa": "accusative object",
"oc": "clausal object",
"og": "genitive object",
"op": "prepositional object",
"par": "parenthetical element",
"pd": "predicate",
"pg": "phrasal genitive",
"ph": "placeholder",
"pm": "morphological particle",
"pnc": "proper noun component",
"rc": "relative clause",
"re": "repeated element",
"rs": "reported speech",
"sb": "subject",
"sbp": "passivized subject (PP)",
"sp": "subject or predicate",
"svp": "separable verb prefix",
"uc": "unit component",
"vo": "vocative",
"PERSON": "People, including fictional",
"NORP": "Nationalities or religious or political groups",
"FACILITY": "Buildings, airports, highways, bridges, etc.",
"FAC": "Buildings, airports, highways, bridges, etc.",
"ORG": "Companies, agencies, institutions, etc.",
"GPE": "Countries, cities, states",
"LOC": "Non-GPE locations, mountain ranges, bodies of water",
"PRODUCT": "Objects, vehicles, foods, etc. (not services)",
"EVENT": "Named hurricanes, battles, wars, sports events, etc.",
"WORK_OF_ART": "Titles of books, songs, etc.",
"LAW": "Named documents made into laws.",
"LANGUAGE": "Any named language",
"DATE": "Absolute or relative dates or periods",
"TIME": "Times smaller than a day",
"PERCENT": 'Percentage, including "%"',
"MONEY": "Monetary values, including unit",
"QUANTITY": "Measurements, as of weight or distance",
"ORDINAL": '"first", "second", etc.',
"CARDINAL": "Numerals that do not fall under another type",
"PER": "Named person or family.",
"MISC": "Miscellaneous entities, e.g. events, nationalities, products or works of art",
"EVT": "Festivals, cultural events, sports events, weather phenomena, wars, etc.",
"PROD": "Product, i.e. artificially produced entities including speeches, radio shows, programming languages, contracts, laws and ideas",
"DRV": "Words (and phrases?) that are dervied from a name, but not a name in themselves, e.g. 'Oslo-mannen' ('the man from Oslo')",
"GPE_LOC": "Geo-political entity, with a locative sense, e.g. 'John lives in Spain'",
"GPE_ORG": "Geo-political entity, with an organisation sense, e.g. 'Spain declined to meet with Belgium'",
}
{kind=link}
{kind=link}
{kind=link}