我正在尝试用 Python 找出在一系列计划的航天器机动中发生的俯仰旋转的通用方法。你可以将其视为 移位检测 问题的一个特例。
让我们考虑我的测量数据中的
让我们考虑我的测量数据中的
solar_elevation_angle 变量,它标识了从航天器仪器测量到的太阳高度角。对于那些想要使用数据的人,我将 solar_elevation_angle.txt 文件保存在 这里。import numpy as np
import matplotlib.pyplot as plt
from matplotlib import gridspec
from scipy.signal import argrelmax
from scipy.ndimage.filters import gaussian_filter1d
solar_elevation_angle = np.loadtxt("solar_elevation_angle.txt", dtype=np.float32)
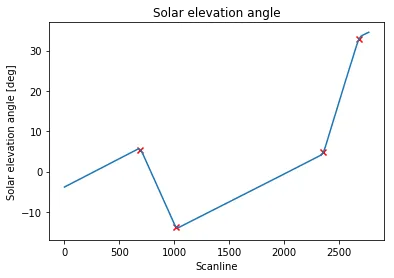
fig, ax = plt.subplots()
ax.set_title('Solar elevation angle')
ax.set_xlabel('Scanline')
ax.set_ylabel('Solar elevation angle [deg]')
ax.plot(solar_elevation_angle)
plt.show()

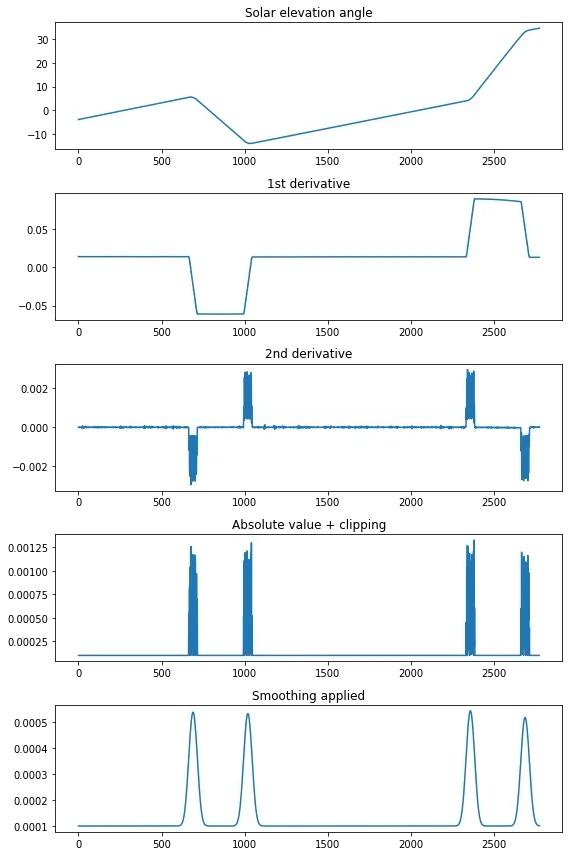
扫描线是我的时间维度。斜率变化的四个点确定了航天器的俯仰旋转。
正如您所看到的,在航天器机动区域之外,太阳高度角随时间的演变几乎是线性的,对于这种特定的航天器,这应该始终如此(除了重大故障)。
请注意,在每次航天器机动期间,斜率变化显然是连续的,尽管在我的角度值集合中离散化。这意味着:对于每次机动,尝试找到一个单独的扫描线来确定机动发生的位置并没有真正意义。我的目标是为每次机动确定一个“代表性”扫描线,该扫描线位于定义机动发生时间间隔的扫描线范围内(例如中间值或左边界)。
一旦我获得了所有机动发生的“代表性”扫描线索引集,我就可以使用这些索引进行机动持续时间的粗略估计,或自动放置图表上的标签。
到目前为止,我的解决方案是:
- 使用
np.gradient计算太阳高度角的二阶导数。 - 计算结果曲线的绝对值和剪裁。剪切是必要的,因为我认为在线性段中存在离散化噪声,这将严重影响点4中“真实”局部最大值的识别。
- 对结果曲线应用平滑处理,以消除多个峰值。我使用scipy的1d高斯滤波器进行试验和误差sigma值。
- 确定局部最大值。
以下是我的代码:
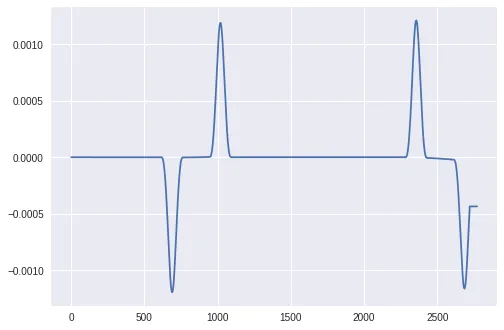
fig = plt.figure(figsize=(8,12))
gs = gridspec.GridSpec(5, 1)
ax0 = plt.subplot(gs[0])
ax0.set_title('Solar elevation angle')
ax0.plot(solar_elevation_angle)
solar_elevation_angle_1stdev = np.gradient(solar_elevation_angle)
ax1 = plt.subplot(gs[1])
ax1.set_title('1st derivative')
ax1.plot(solar_elevation_angle_1stdev)
solar_elevation_angle_2nddev = np.gradient(solar_elevation_angle_1stdev)
ax2 = plt.subplot(gs[2])
ax2.set_title('2nd derivative')
ax2.plot(solar_elevation_angle_2nddev)
solar_elevation_angle_2nddev_clipped = np.clip(np.abs(np.gradient(solar_elevation_angle_2nddev)), 0.0001, 2)
ax3 = plt.subplot(gs[3])
ax3.set_title('absolute value + clipping')
ax3.plot(solar_elevation_angle_2nddev_clipped)
smoothed_signal = gaussian_filter1d(solar_elevation_angle_2nddev_clipped, 20)
ax4 = plt.subplot(gs[4])
ax4.set_title('Smoothing applied')
ax4.plot(smoothed_signal)
plt.tight_layout()
plt.show()
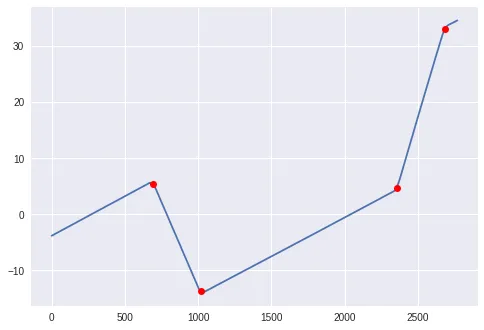
我可以使用scipy的argrelmax函数轻松地识别出局部极大值:
max_idx = argrelmax(smoothed_signal)[0]
print(max_idx)
# [ 689 1019 2356 2685]
哪个正确地识别了我正在寻找的扫描线索引:
fig, ax = plt.subplots()
ax.set_title('Solar elevation angle')
ax.set_xlabel('Scanline')
ax.set_ylabel('Solar elevation angle [deg]')
ax.plot(solar_elevation_angle)
ax.scatter(max_idx, solar_elevation_angle[max_idx], marker='x', color='red')
plt.show()