我正在使用scikit learn拟合k最近邻分类器,并注意到当使用两个向量之间的余弦相似度时,拟合速度更快,通常比使用欧几里得相似度快一个数量级或更多。请注意,这两种方法都是sklearn内置的;我没有使用任何自定义实现。
为什么会有如此大的差异?我知道scikit learn使用Ball树或KD树来计算邻居图,但我不确定度量形式为什么会影响算法的运行时间。
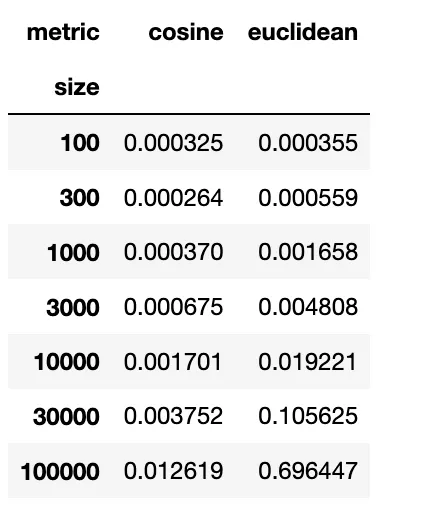
为了量化效果,我进行了一次模拟实验,其中我使用欧几里得或余弦度量对随机数据进行了KNN拟合,并记录了每种情况下的运行时间。每种情况下的平均运行时间如下所示:
import numpy as np
import time
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
res=[]
n_trials=10
for trial_id in range(n_trials):
for n_pts in [100,300,1000,3000,10000,30000,100000]:
for metric in ['cosine','euclidean']:
knn=KNeighborsClassifier(n_neighbors=20,metric=metric)
X=np.random.randn(n_pts,100)
labs=np.random.choice(2,n_pts)
starttime=time.time()
knn.fit(X,labs)
elapsed=time.time()-starttime
res.append([elapsed,n_pts,metric,trial_id])
res=pd.DataFrame(res,columns=['time','size','metric','trial'])
av_times=pd.pivot_table(res,index='size',columns='metric',values='time')
print(av_times)
sklearn==0.24.2,没有发现任何显著差异。如果你正在使用相同版本的话,可能与你的本地机器有关。 - amin_nejad