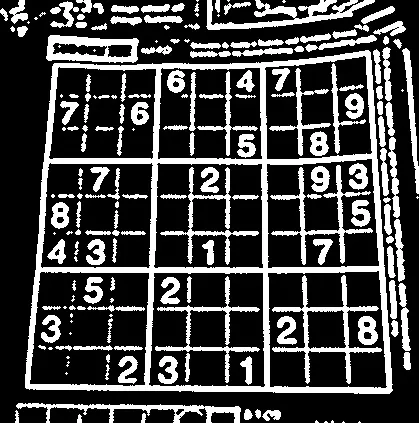
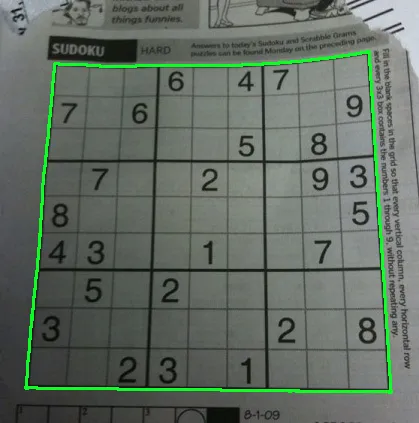
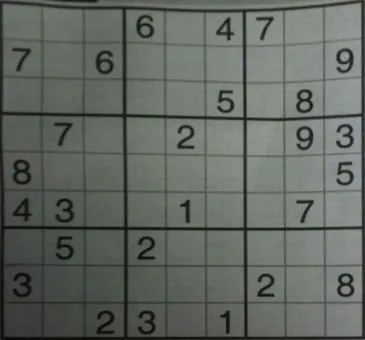
这是我的解决方案,适用于任何图像,无论是否扭曲。
- 将图像转换为灰度
- 应用自适应阈值处理以将图像转换为二进制(自适应阈值处理比普通阈值处理更好,因为原始图像在不同区域可能具有不同的光照)
- 识别大正方形的四个角
- 将图像进行透视变换,使其成为最终的正方形图像
根据原始图像的扭曲程度,识别出的角可能顺序错乱,我们需要将它们排列在正确的顺序中。这里使用的方法是识别出大正方形的质心,并从那里确定角的顺序。
以下是代码:
import cv2
import numpy as np
def euclidian_distance(point1, point2):
distance = np.sqrt((point1[0] - point2[0]) ** 2 + (point1[1] - point2[1]) ** 2)
return distance
def order_corner_points(corners):
sort_corners = [(corner[0][0], corner[0][1]) for corner in corners]
sort_corners = [list(ele) for ele in sort_corners]
x, y = [], []
for i in range(len(sort_corners[:])):
x.append(sort_corners[i][0])
y.append(sort_corners[i][1])
centroid = [sum(x) / len(x), sum(y) / len(y)]
for _, item in enumerate(sort_corners):
if item[0] < centroid[0]:
if item[1] < centroid[1]:
top_left = item
else:
bottom_left = item
elif item[0] > centroid[0]:
if item[1] < centroid[1]:
top_right = item
else:
bottom_right = item
ordered_corners = [top_left, top_right, bottom_right, bottom_left]
return np.array(ordered_corners, dtype="float32")
def image_preprocessing(image, corners):
ordered_corners = order_corner_points(corners)
print("ordered corners: ", ordered_corners)
top_left, top_right, bottom_right, bottom_left = ordered_corners
width1 = euclidian_distance(bottom_right, bottom_left)
width2 = euclidian_distance(top_right, top_left)
height1 = euclidian_distance(top_right, bottom_right)
height2 = euclidian_distance(top_left, bottom_right)
width = max(int(width1), int(width2))
height = max(int(height1), int(height2))
dimensions = np.array([[0, 0], [width, 0], [width, width],
[0, width]], dtype="float32")
matrix = cv2.getPerspectiveTransform(ordered_corners, dimensions)
transformed_image = cv2.warpPerspective(image, matrix, (width, width))
transformed_image = cv2.resize(transformed_image, (252, 252), interpolation=cv2.INTER_AREA)
return transformed_image
def get_square_box_from_image(image):
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blur = cv2.medianBlur(gray, 3)
adaptive_threshold = cv2.adaptiveThreshold(blur, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY_INV, 11, 3)
corners = cv2.findContours(adaptive_threshold, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
corners = corners[0] if len(corners) == 2 else corners[1]
corners = sorted(corners, key=cv2.contourArea, reverse=True)
for corner in corners:
length = cv2.arcLength(corner, True)
approx = cv2.approxPolyDP(corner, 0.015 * length, True)
print(approx)
puzzle_image = image_preprocessing(image, approx)
break
return puzzle_image
original = cv2.imread("large_puzzle.jpg")
sudoku = get_square_box_from_image(original)
这是给定图像和自定义示例的结果