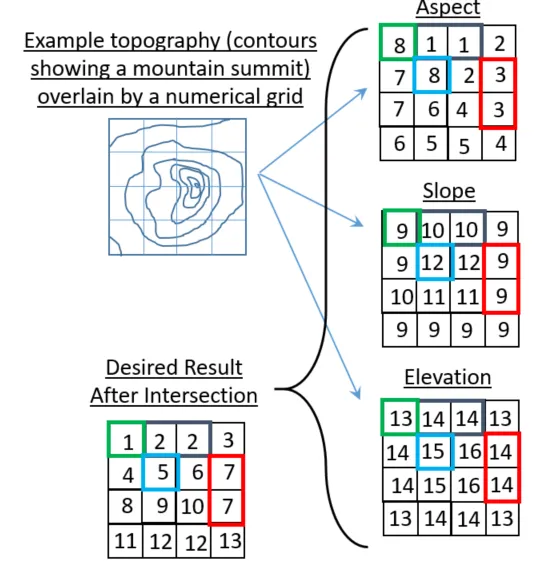
每个网格位置都与一个元组相关联,由
asp、
slp和
elv中的一个值组成。例如,左上角具有元组
(8,9,13)。我们希望将此元组映射到一个唯一标识该元组的数字。
一种方法是将
(8,9,13)视为3D数组
np.arange(9*13*17).reshape(9,13,17)中的索引。选择这个特定的数组是为了容纳
asp、
slp和
elv中最大的值。
In [107]: asp.max()+1
Out[107]: 9
In [108]: slp.max()+1
Out[108]: 13
In [110]: elv.max()+1
Out[110]: 17
现在,我们可以将元组(8,9,13)映射到数字1934:
In [113]: x = np.arange(9*13*17).reshape(9,13,17)
In [114]: x[8,9,13]
Out[114]: 1934
如果我们对网格中的每个位置都这样做,那么我们就会得到每个位置的唯一编号。我们可以在此停止,并让这些唯一的数字作为标签。
或者,我们可以使用np.unique并使用return_inverse=True生成较小的整数标签(从0开始递增):
uniqs, labels = np.unique(vals, return_inverse=True)
labels = labels.reshape(vals.shape)
例如,
import numpy as np
asp = np.array([8,1,1,2,7,8,2,3,7,6,4,3,6,5,5,4]).reshape((4,4))
slp = np.array([9,10,10,9,9,12,12,9,10,11,11,9,9,9,9,9]).reshape((4,4))
elv = np.array([13,14,14,13,14,15,16,14,14,15,16,14,13,14,14,13]).reshape((4,4))
x = np.arange(9*13*17).reshape(9,13,17)
vals = x[asp, slp, elv]
uniqs, labels = np.unique(vals, return_inverse=True)
labels = labels.reshape(vals.shape)
产生。
array([[11, 0, 0, 1],
[ 9, 12, 2, 3],
[10, 8, 5, 3],
[ 7, 6, 6, 4]])
上述方法只适用于
asp、
slp和
elv中的值为小整数的情况。如果整数太大,它们的最大值乘积可能会超出可以传递给
np.arange的最大允许值。此外,生成如此大的数组也是低效的。
如果这些值是浮点数,则不能将它们解释为3D数组
x中的索引。
因此,要解决这些问题,首先使用
np.unique将
asp、
slp和
elv中的值转换为唯一的整数标签:
indices = [ np.unique(arr, return_inverse=True)[1].reshape(arr.shape) for arr in [asp, slp, elv] ]
M = np.array([item.max()+1 for item in indices])
x = np.arange(M.prod()).reshape(M)
vals = x[indices]
uniqs, labels = np.unique(vals, return_inverse=True)
labels = labels.reshape(vals.shape)
这将产生与上述相同的结果,但即使asp、slp、elv是浮点数和/或大整数,也能正常工作。
最后,我们可以避免生成
np.arange:
x = np.arange(M.prod()).reshape(M)
vals = x[indices]
通过将
vals计算为索引和步长的乘积:
M = np.r_[1, M[:-1]]
strides = M.cumprod()
indices = np.stack(indices, axis=-1)
vals = (indices * strides).sum(axis=-1)
将所有东西放在一起:
import numpy as np
asp = np.array([8,1,1,2,7,8,2,3,7,6,4,3,6,5,5,4]).reshape((4,4))
slp = np.array([9,10,10,9,9,12,12,9,10,11,11,9,9,9,9,9]).reshape((4,4))
elv = np.array([13,14,14,13,14,15,16,14,14,15,16,14,13,14,14,13]).reshape((4,4))
def find_labels(*arrs):
indices = [np.unique(arr, return_inverse=True)[1] for arr in arrs]
M = np.array([item.max()+1 for item in indices])
M = np.r_[1, M[:-1]]
strides = M.cumprod()
indices = np.stack(indices, axis=-1)
vals = (indices * strides).sum(axis=-1)
uniqs, labels = np.unique(vals, return_inverse=True)
labels = labels.reshape(arrs[0].shape)
return labels
print(find_labels(asp, slp, elv))