我有一个数据框 df
df<-structure(list(ID = structure(c(1L, 3L, 5L, 6L, 8L, 9L, 10L,
11L, 12L, 13L, 14L, 15L, 16L, 17L, 18L, 19L, 20L, 21L, 22L, 23L,
24L, 28L, 29L, 30L, 33L, 34L, 37L, 38L, 40L, 41L, 42L, 43L, 44L,
45L, 46L, 48L, 49L, 50L, 52L, 53L, 54L, 56L, 57L, 60L, 61L, 62L,
63L, 64L, 65L, 66L, 67L, 69L, 71L, 74L, 75L, 86L, 88L, 90L, 92L,
94L, 95L, 100L, 101L, 107L, 108L, 109L, 110L, 111L, 112L), .Label = c("AU-Tum",
"AU-Wac", "BE-Bra", "BE-Jal", "BE-Vie", "BR-Cax", "BR-Sa3", "CA-Ca1",
"CA-Ca2", "CA-Ca3", "CA-Gro", "Ca-Man", "CA-NS1", "CA-NS2", "CA-NS3",
"CA-NS4", "CA-NS5", "CA-NS6", "CA-NS7", "CA-Oas", "CA-Obs", "CA-Ojp",
"CA-Qcu", "CA-Qfo", "CA-SF1", "CA-SF2", "CA-SF3", "CA-SJ1", "CA-SJ2",
"CA-SJ3", "CA-TP1", "CA-TP2", "CA-TP4", "CN-Cha", "CN-Ku1", "CZ-Bk1",
"De-Bay", "DE-Hai", "DE-Har", "DE-Tha", "DE-Wet", "DK-Sor", "ES-Es1",
"FI-Hyy", "FI-Sod", "FR-Fon", "FR-Hes", "FR-Lbr", "FR-Pue", "GF-Guy",
"ID-Pag", "IL-Yat", "IT-Col", "IT-Cpz", "IT-Lav", "IT-Non", "IT-Pt1",
"IT-Ro1", "IT-Ro2", "IT-Sro", "JP-Tak", "JP-Tef", "JP-Tom", "NL-Loo",
"PT-Esp", "RU-Fyo", "RU-Zot", "SE-Abi", "SE-Fla", "SE-Nor", "SE-Sk1",
"SE-Sk2", "SE-St1", "UK-Gri", "UK-Ham", "US-Bar", "US-Blo", "US-Bn1",
"US-Bn2", "Us-Bn3", "US-Dk3", "US-Fmf", "US-Fwf", "US-Ha1", "US-Ha2",
"US-Ho1", "US-Ho2", "US-Lph", "US-Me1", "US-Me3", "US-Nc2", "US-NR1",
"US-Oho", "US-So2", "US-So3", "US-Sp1", "US-Sp2", "US-Sp3", "US-Syv",
"US-Umb", "US-Wcr", "US-Wi0", "US-Wi1", "US-Wi2", "US-Wi4", "US-Wi8",
"VU-Coc", "CA-Cbo", "RU-Ab", "RU-Be", "RU-Mix", "TH-Mae"), class = "factor"),
VarA = c(98.5, 77, 63.2222222222222, 97, 52.5, 3.5, 15.5,
71, 161.833333333333, 153.5, 73, 39, 40, 23, 14, 5.5, 78,
129.5, 73.5, 4, 100, 10, 3, 30, 65.5, 198, 45.5, 20, 111.5,
44, 68.5, 102.5, 39.1111111111111, 83.8, 136, 31.5, 56.5,
101, 39.25, 108.5, 52.1666666666667, 9.5, 13, 52.1428571428571,
66.5, 1, 44.25, 106, 19, 202.571428571429, 200, 36.6, 2,
21.2, 69, 135, 46.5, 17.5, 96, 80.6666666666667, 10.6666666666667,
86.5, 70.5, 19.5, 85, 200, 50, 250, 30.5), Y = c(436.783385497984,
55.1825021383702, 526.4133417369, 560, 391.49284084118, -519.814235572849,
11.5525291214872, 162.441016515717, 39.0395567645998, -70.4910326673707,
17.1155716306239, -106.326129257097, -94.9308303585276, -66.4285516217351,
-144.929052323413, -220.613145695315, 157.129576861289, 44.1257786633602,
46.8326830295943, -146.719591499443, 30.8043649939355, -4.10548956954153,
-108.258462657337, 90.3369144331664, 126.866108251153, 42.9489971246803,
-45.4886732113082, 483.932040393885, 590.754048774834, 82.1480000555981,
76.8863707484328, 404.007940533033, 202.629066249886, -46.9675149230141,
557.939170770813, 300.979565786038, 224.256197650044, 148.719307398695,
201.195892312115, 466.727302447427, 552.762670615377, 481.359543363331,
467.379381521489, 444.812610935212, 308.198167469197, -638.973101716489,
321.395064735785, 181.896345832773, 629.214319321327, -176.181996958815,
214, 59.1716887350485, -186.42650026083, 515.533437888983,
595.091753601562, 255.499246957091, 368.347069109092, 141.97570288631,
39.5917358684237, 105.039591642989, 77.9087587283187, 153.700042322307,
198.276033313996, 358.242634316906, 156.666666666667, 270,
247, 100, -10)), .Names = c("ID", "VarA", "Y"), row.names = c(NA,
-69L), class = "data.frame")
我正在进行非线性回归分析,以拟合模型的参数。
library (minpack.lm)
fit1<- nlsLM(Y~A*(1-exp(k*VarA)), data = NEP_Mean_Site,
start = list(A=192.93829, k=-0.08976), control = list(maxiter = 500))
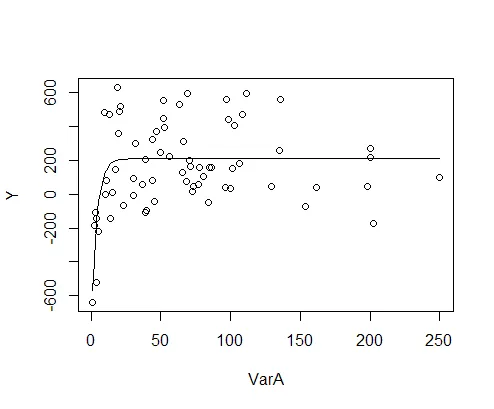
当我将非线性模型的输出与我的数据绘制在一起时,得到了这个输出。
coeff(fit1)
f<- function (x) {211.00044*(1-exp(-0.07224*x))}
plot(df$VarA, df$Y)
curve(f, add=T)
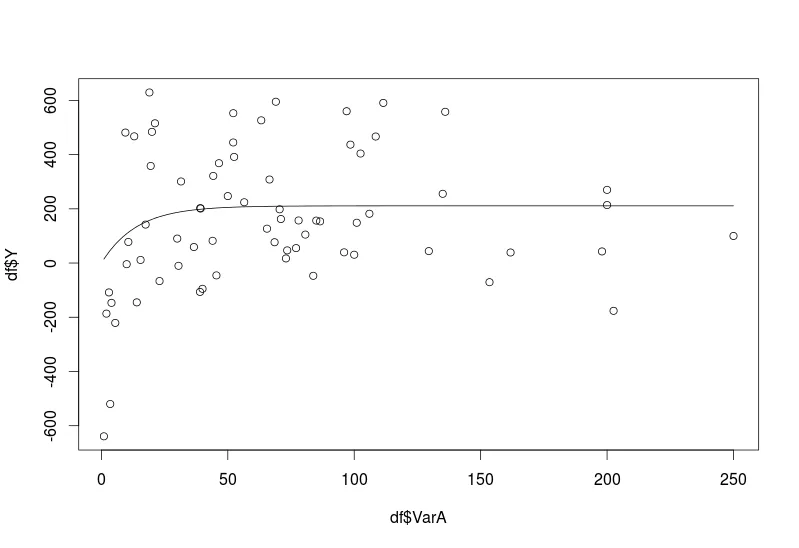
然而,我想让我的模型从零以下开始。 我猜我需要调整我的模型并在我的nls拟合中包含一个偏移量,但找不到如何实现的方法。 有人知道该怎么做吗?