直接的
.apply() 解决方案:
df['Count'] = df.B.apply(lambda x: sum('Closed' in v for v in x.values()))
print(df)
输出:
A B Count
0 1 {'Mon': 'Closed', 'Tue': 'Open', 'Wed': 'Closed'} 2
1 2 {'Mon': 'Open', 'Tue': 'Open', 'Wed': 'Closed'} 1
2 3 {'Mon': 'Open', 'Tue': 'Open', 'Wed': 'Open'} 0
基准测试:
import perfplot
import pandas as pd
def f1(df):
df['Count'] = df.B.apply(lambda x: sum('Closed' in v for v in x.values()))
return df
def f2(df):
df['count'] = df.B.astype(str).str.count('Closed')
return df
def f4(df):
df['count'] = pd.DataFrame(df['B'].tolist()).stack().eq("Closed").sum(level=0)
return df
def setup(n):
A = [*range(n)]
B = [{'Mon': 'Closed', 'Tue': 'Open', 'Wed': 'Closed'} for _ in range(n)]
df = pd.DataFrame({'A': A,
'B': B})
return df
perfplot.show(
setup=setup,
kernels=[f1, f2, f4],
labels=['apply(sum)', 'str.count()', 'stack.eq()'],
n_range=[10**i for i in range(1, 7)],
xlabel='N (* len(df))',
equality_check=None,
logx=True,
logy=True)
结果:
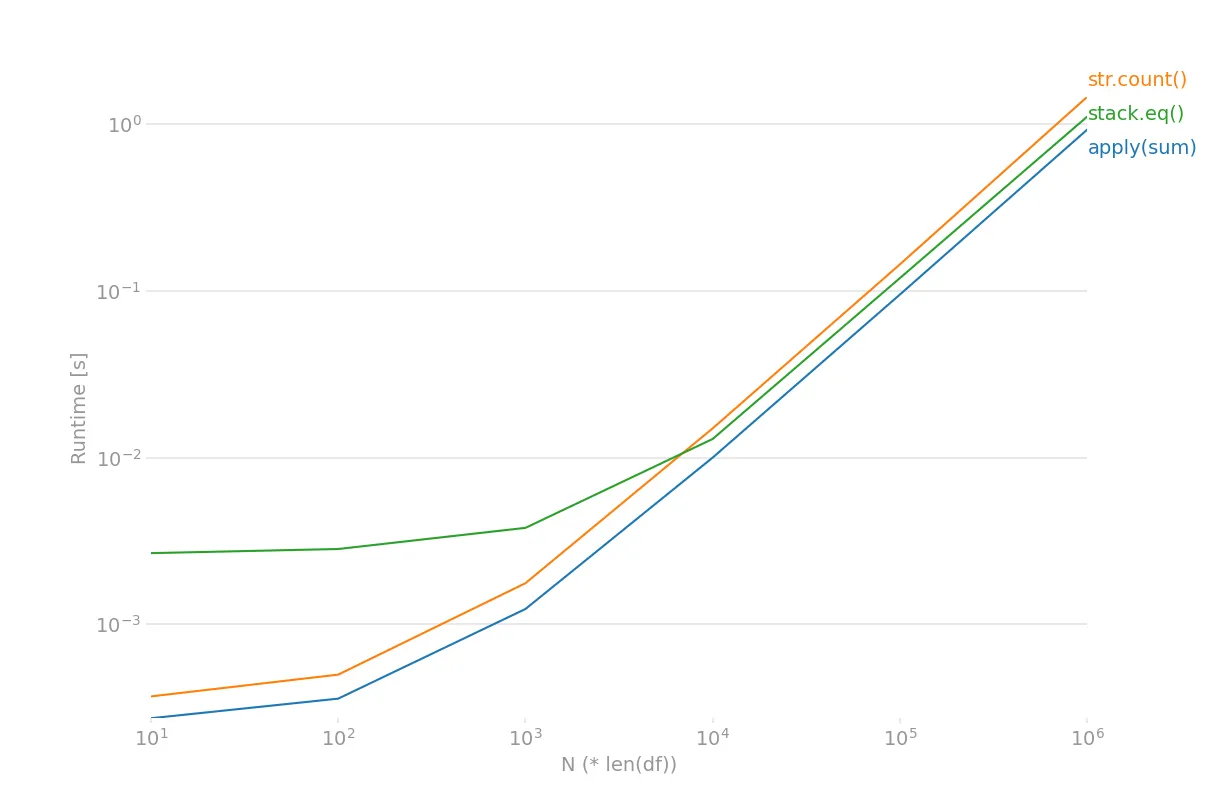
所以看起来直接使用 apply() 和 sum() 是最快的。