我目前有一个不平衡的数据集,如下图所示: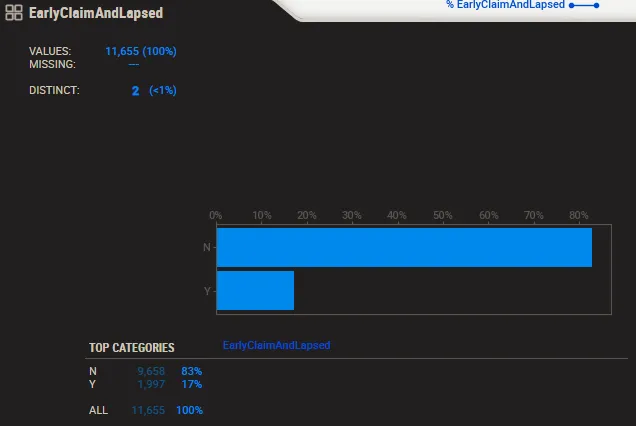 然后,在训练LightGBM模型时,我使用'is_unbalance'参数,并将其设置为
然后,在训练LightGBM模型时,我使用'is_unbalance'参数,并将其设置为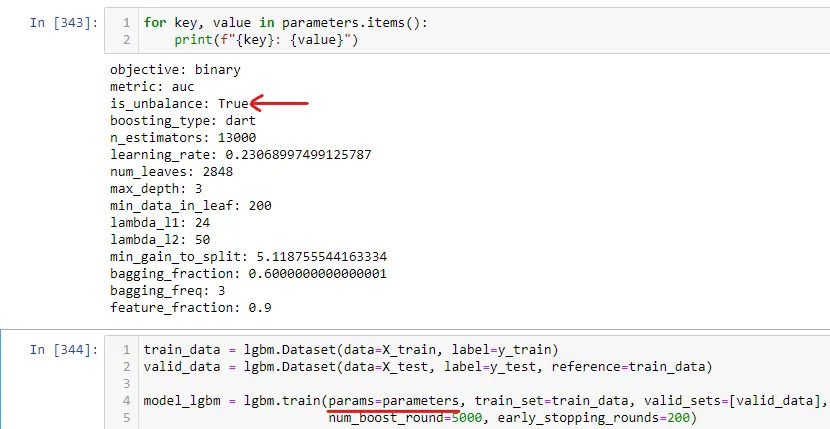 使用sckit-learn API的示例:
使用sckit-learn API的示例: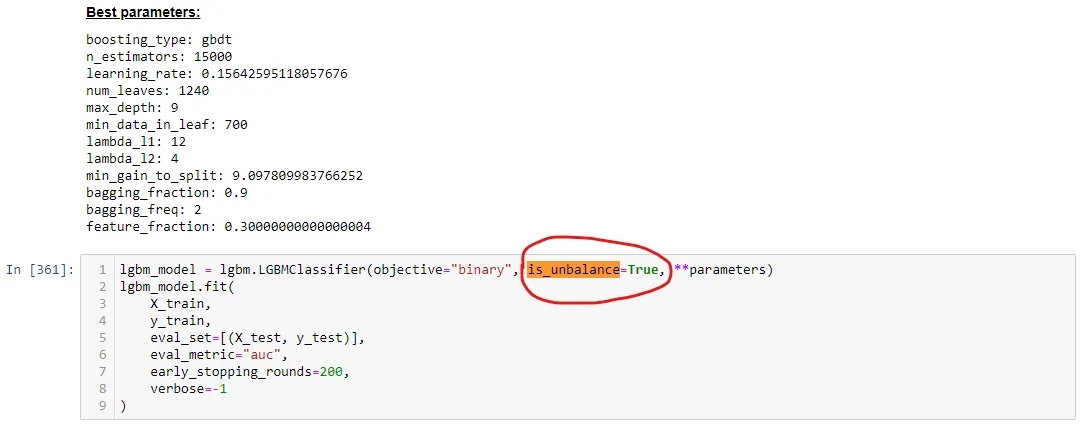 我的问题是:
我的问题是:
然后,在训练LightGBM模型时,我使用'is_unbalance'参数,并将其设置为True。下面的图表显示了我如何使用该参数。
使用本机API的示例:
使用sckit-learn API的示例:
我的问题是:
- 我应用'is_unbalance'参数的方式正确吗?
- 如何使用'scale_pos_weight'代替'is_unbalance'?
- 还是我应该使用像'SMOTE-ENN'或'SMOTE+TOME'这样的'SMOTE'技术来平衡数据集?