我正在尝试在一个二元分类问题的模型训练中使用'is_unbalance'参数,其中正类约占3%。如果我设置'is_unbalance'参数,我观察到二元对数损失在第一次迭代中下降,但之后就一直增加。我只有在启用此参数'is_unbalance'时才会注意到这种行为。否则,对数损失会稳步下降。感谢您的帮助。谢谢。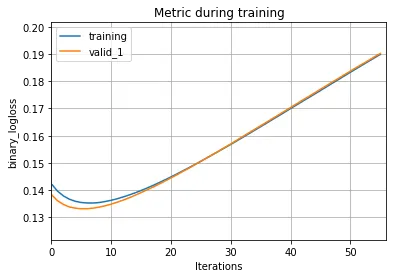
WEIGHTS = y_train.value_counts(normalize = True).min() / y_train.value_counts(normalize = True)
TRAIN_WEIGHTS = pd.DataFrame(y_train.rename('old_target')).merge(WEIGHTS, how = 'left', left_on = 'old_target', right_on = WEIGHTS.index).target.values
train_data = lgb.Dataset(X_train, label=y_train, weight = TRAIN_WEIGHTS)
当你设置Is_unbalace: True时,算法会尝试自动平衡被支配标签的权重(在训练集中具有正/负分数)。 如果你想在不平衡的数据集情况下改变scale_pos_weight(默认为1,意味着假设正负标签相等),你可以使用以下公式(基于lightgbm存储库上的此问题)来正确设置它。 sample_pos_weight = 负样本数量 / 正样本数量