我正在处理一个包含3个类别[0,1,2]的分类问题,类别分布不平衡,如下所示。
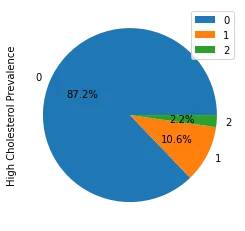
我想使用Python中的XGBClassifier来解决这个分类问题,但是模型不响应class_weight的调整,而是偏向于多数类0,而忽略少数类1,2。除了class_weight以外,还有哪些超参数可以帮助我?
我尝试了以下方法:1)使用sklearn的compute_class_weight计算类别权重;2)根据类别的相对频率设置权重;3)手动调整极端值的类别,例如{0:0.5,1:100,2:200}。但是在任何情况下,都不能帮助分类器考虑到少数类别。
观察:
我可以在二元分类问题中解决这个问题:通过识别类别[1,2],将问题变成二元分类,然后通过调整
scale_pos_weight使分类器正常工作(即使在这种情况下,单独使用class_weight也无法帮助)。 但是,据我所知,scale_pos_weight只适用于二元分类。对于多分类问题,是否有类似的参数?
使用RandomForestClassifier替代XGBClassifier,我可以通过设置class_weight='balanced_subsample'和调整max_leaf_nodes来解决问题。但是由于某些原因,这种方法在XGBClassifier上不起作用。
备注:我知道有平衡技术,比如过/欠采样或SMOTE。但是尽可能地避免它们,并优先考虑使用模型的超参数调整来解决问题。
我的观察结果表明,在二元情况下,这种方法是可行的。