我有一个包含两个分类列[Message]和 [Intent]的小数据集,大约有1000条记录。 我想创建一个分类模型并对新的未知信息进行预测。
这29个独特的意图是不平衡的,它们的值计数范围从116到4不等:
intent_1 116
intent_2 98
intent_3 81
intent_4 78
intent_5 73
intent_6 68
intent_7 66
intent_8 65
intent_9 62
intent_10 61
intent_11 56
intent_12 53
intent_13 50
intent_14 49
intent_15 45
intent_16 40
intent_17 37
intent_18 32
intent_19 31
intent_20 30
intent_21 25
intent_22 22
intent_23 21
intent_24 19
intent_25 15
intent_26 12
intent_27 10
intent_28 9
intent_29 4
我最初尝试了一个CNN模型,并使用了准确率和分类交叉熵指标,但结果不佳:
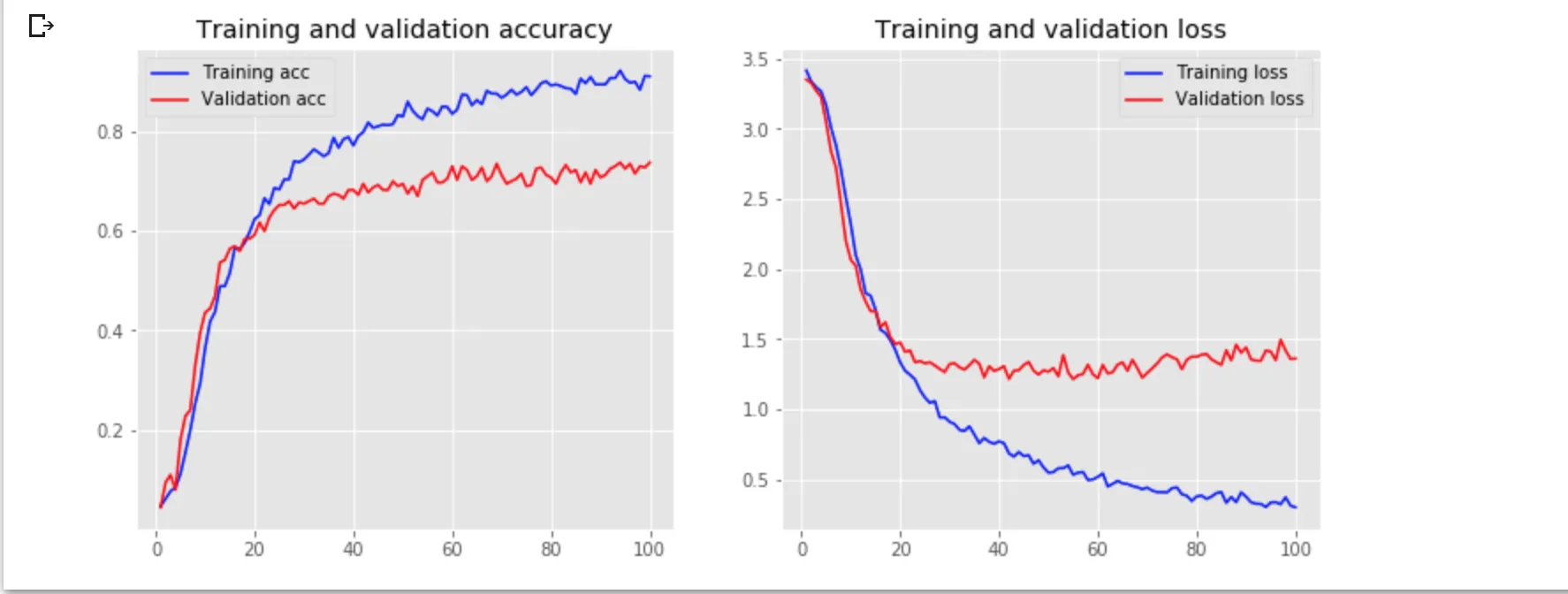
在调整批量大小、迭代次数、drop-off、激活函数、预先训练的词嵌入等参数后,我还尝试了一个bi-lstm模型,但我的模型仍然存在过拟合问题。
因此,在训练模型之前,我尝试添加了一个过度抽样的步骤来解决类别不平衡的问题,但现在的结果更糟糕了。
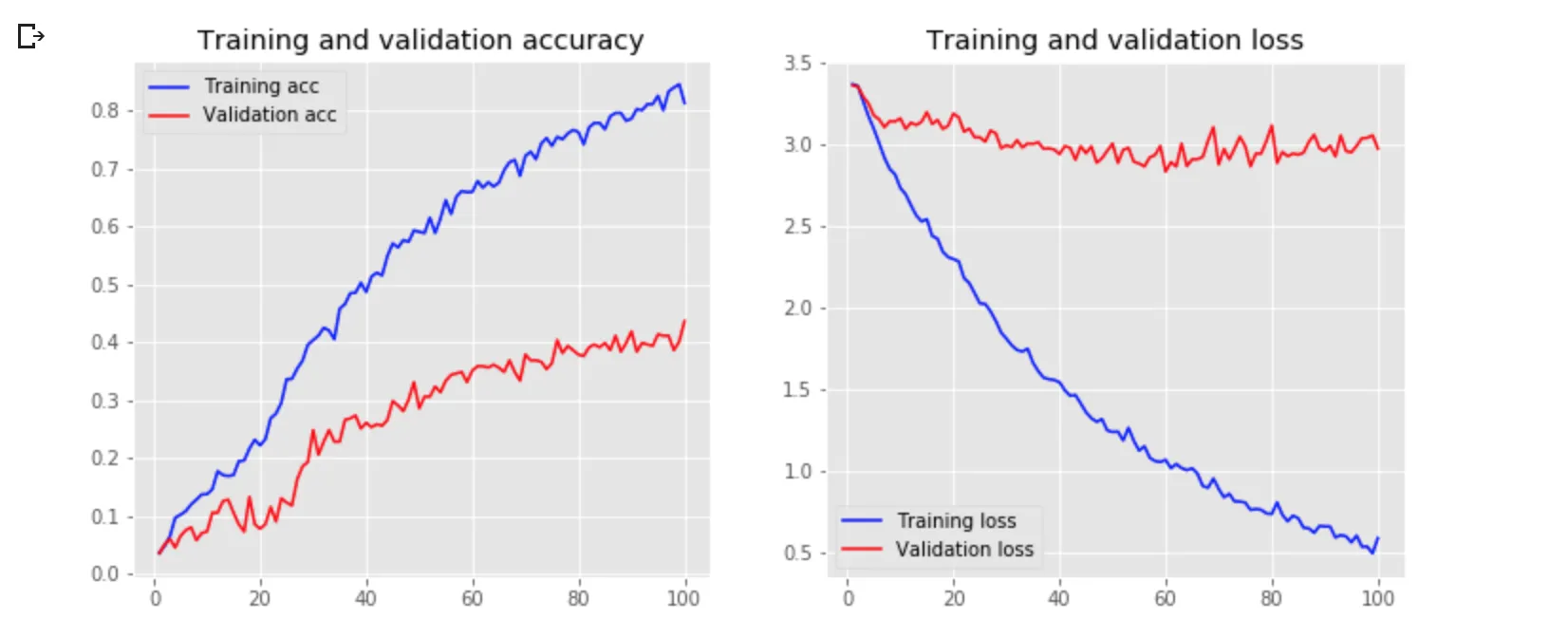
有人可以帮我吗?这是我目前的代码:
#load training and validation files and concatenate them
def load_datasets(train_file, val_file):
train = pd.read_excel(train_file)
val = pd.read_csv(val_file, error_bad_lines=False, sep=";")
#drop additional info column
train.drop(train.columns[1], axis=1, inplace=True)
#concatenate two dataframes
frames = [train, val]
result = pd.concat(frames)
intent = result["Label"]
unique_intent = list(set(intent))
sentences = list(result["Message"])
return(intent, unique_intent, sentences)
intent, unique_intent, sentences = load_datasets("Training.xlsx","Validation.csv")
#define stemmer
stemmer = SnowballStemmer("english")
#define lemmatizer
lemmatizer = WordNetLemmatizer()
#clean the data : remove punctuation, tokenize, lowercase, lemmatize
def preprocessing(sentences):
words = []
for sent in sentences:
clean = re.sub(r'[^ a-z A-Z 0-9]', " ", sent)
w = word_tokenize(clean)
#stemming
words.append([lemmatizer.lemmatize(i.lower()) for i in w])
return words
cleaned = preprocessing(sentences)
#creating tokenizer
def create_tokenizer(words, filters = '!"#$%&()*+,-./:;<=>?@[\]^_`{|}~'):
token = Tokenizer(filters = filters)
token.fit_on_texts(words)
return token
#defining maximum length
def max_length(words):
return(len(max(words, key = len)))
#show vocabulary size and maximum length
word_tokenizer = create_tokenizer(cleaned)
vocab_size = len(word_tokenizer.word_index) + 1
max_length = max_length(cleaned)
print("Vocab Size = %d and Maximum length = %d" % (vocab_size, max_length))
#### Vocab Size = 811 and Maximum length = 45
#encoding list of words
def encoding_doc(token, words):
return(token.texts_to_sequences(words))
encoded_doc = encoding_doc(word_tokenizer, cleaned)
#add padding to make words of equal length to use in the model
def padding_doc(encoded_doc, max_length):
return(pad_sequences(encoded_doc, maxlen = max_length,
padding = "post"))
padded_doc = padding_doc(encoded_doc, max_length)
output_tokenizer = create_tokenizer(unique_intent,
filters = '!"#$%&()*+,-/:;<=>?@[\]^`{|}~')
output_tokenizer.word_index
encoded_output = encoding_doc(output_tokenizer, intent)
encoded_output = np.array(encoded_output).reshape(len(encoded_output), 1)
#one-hot encoding
def one_hot(encode):
o = OneHotEncoder(sparse=False, categories='auto')
return(o.fit_transform(encode))
output_one_hot = one_hot(encoded_output)
#split dataset to train (70%) and validation set (30%)
from sklearn.model_selection import train_test_split
train_X, val_X, train_Y, val_Y = train_test_split(padded_doc, output_one_hot,
shuffle = True,
random_state=1,
test_size = 0.3)
print("Shape of train_X = %s and train_Y = %s" % (train_X.shape, train_Y.shape))
print("Shape of val_X = %s and val_Y = %s" % (val_X.shape, val_Y.shape))
#### Shape of train_X = (929, 45) and train_Y = (929, 29)
#### Shape of val_X = (399, 45) and val_Y = (399, 29)
#Over Sample
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import recall_score
clf_rf = RandomForestClassifier(n_estimators=10)
clf_rf.fit(x_train_res, y_train_res)
#over sampling
from sklearn.model_selection import train_test_split
from imblearn.over_sampling import SMOTENC
x_train, x_val, y_train, y_val = train_test_split(train_X, train_Y,
shuffle = True,
test_size = 0.3)
sm = SMOTENC(categorical_features=[0,44], k_neighbors=2)
x_train_res, y_train_res = sm.fit_sample(x_train, y_train)
print('Validation Results')
print(clf_rf.score(x_val, y_val))
print(recall_score(y_val, clf_rf.predict(x_val),average='micro'))
print('\nTest Results')
print(clf_rf.score(val_X, val_Y))
print(recall_score(val_Y, clf_rf.predict(val_X),average='micro'))
### Validation Results
### 0.4495798319327731
### 0.4495798319327731
### Test Results
### 0.14035087719298245
### 0.14035087719298245
#Define the model
def create_model(vocab_size, max_length):
model = Sequential()
model.add(Embedding(vocab_size, 100, input_length=max_length, trainable=False))
model.add(Dropout(0.2))
model.add(Conv1D(64, 5, activation='relu'))
model.add(MaxPooling1D(pool_size=4))
model.add(LSTM(32))
model.add(Dense(29, activation='softmax'))
return model
model = create_model(vocab_size, max_length)
model.compile(loss = "categorical_crossentropy", optimizer = "adam",
metrics = ["accuracy"])
model.summary()
filename = 'model.h5'
checkpoint = ModelCheckpoint(filename, monitor='val_loss', verbose=1,
save_best_only=True, mode='min')
hist = model.fit(x_train_res, y_train_res, epochs = 100, batch_size = 32,
validation_data = (val_X, val_Y), callbacks = [checkpoint])
model = load_model("model.h5")
plt.style.use('ggplot')
def plot_history(hist):
acc = hist.history['acc']
val_acc = hist.history['val_acc']
loss = hist.history['loss']
val_loss = hist.history['val_loss']
x = range(1, len(acc)+1)
plt.figure(figsize=(12,5))
plt.subplot(1, 2, 1)
plt.plot(x, acc, 'b', label='Training acc')
plt.plot(x, val_acc, 'r', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.subplot(1,2,2)
plt.plot(x, loss, 'b', label='Training loss')
plt.plot(x, val_loss, 'r', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plot_history(hist)