我正在处理一个时间序列预测问题,并构建了以下类似的LSTM模型:
当我使用以下5个拆分训练模型时:
def create_model():
model = Sequential()
model.add(LSTM(50,kernel_regularizer=l2(0.01), recurrent_regularizer=l2(0.01), bias_regularizer=l2(0.01), input_shape=(train_X.shape[1], train_X.shape[2])))
model.add(Dropout(0.591))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
return model
当我使用以下5个拆分训练模型时:
tss = TimeSeriesSplit(n_splits = 5)
X = data.drop(labels=['target_prediction'], axis=1)
y = data['target_prediction']
for train_index, test_index in tss.split(X):
train_X, test_X = X.iloc[train_index, :].values, X.iloc[test_index,:].values
train_y, test_y = y.iloc[train_index].values, y.iloc[test_index].values
model=create_model()
history = model.fit(train_X, train_y, epochs=10, batch_size=64,validation_data=(test_X, test_y), verbose=0, shuffle=False)
我遇到了过拟合问题。附上损失图表 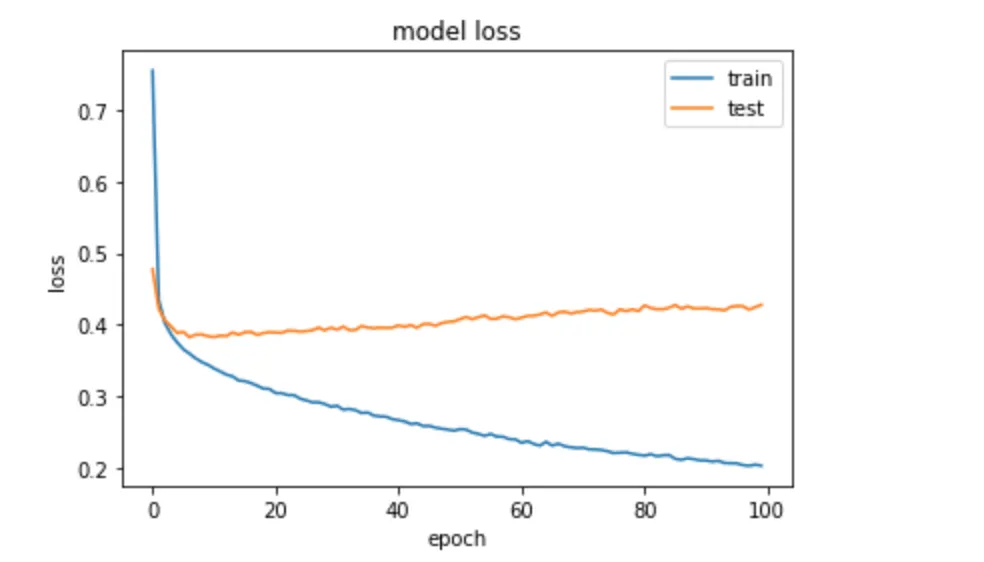
我不确定为什么在使用Keras模型中的正则化器时会出现过拟合。感谢任何帮助。
编辑: 尝试了这些结构
def create_model():
model = Sequential()
model.add(LSTM(20, input_shape=(train_X.shape[1], train_X.shape[2])))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
return model
def create_model(x,y):
# define LSTM
model = Sequential()
model.add(Bidirectional(LSTM(20, return_sequences=True), input_shape=(x,y)))
model.add(TimeDistributed(Dense(1, activation='sigmoid')))
model.compile(loss='mean_squared_error', optimizer='adam')
return model
但仍然存在过拟合问题。