我以两种方式计算Pearson相关性:
在Tensorflow中,我使用以下度量标准:
tf.contrib.metrics.streaming_pearson_correlation(y_pred, y_true)
当我用测试数据评估我的网络时,我得到了以下结果:
损失 = 0.5289223349094391
皮尔森相关系数 = 0.3701728057861328
(损失是mean_squared_error)
然后我使用Scipy预测测试数据并计算相同的指标:
import scipy.stats as measures
per_coef = measures.pearsonr(y_pred, y_true)[0]
mse_coef = np.mean(np.square(np.array(y_pred) - np.array(y_true)))
以下是我的结果:
Pearson = 0.5715300096509959
MSE = 0.5289223312665985
这是已知的问题吗?这正常吗?
最小、完整和可验证的示例
import tensorflow as tf
import scipy.stats as measures
y_pred = [2, 2, 3, 4, 5, 5, 4, 2]
y_true = [1, 2, 3, 4, 5, 6, 7, 8]
## Scipy
val2 = measures.pearsonr(y_pred, y_true)[0]
print("Scipy's Pearson = {}".format(val2))
## Tensorflow
logits = tf.placeholder(tf.float32, [8])
labels = tf.to_float(tf.Variable(y_true))
acc, acc_op = tf.contrib.metrics.streaming_pearson_correlation(logits,labels)
sess = tf.Session()
sess.run(tf.local_variables_initializer())
sess.run(tf.global_variables_initializer())
sess.run(acc, {logits:y_pred})
sess.run(acc_op, {logits:y_pred})
print("Tensorflow's Pearson:{}".format(sess.run(acc,{logits:y_pred})))
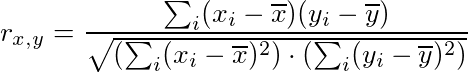
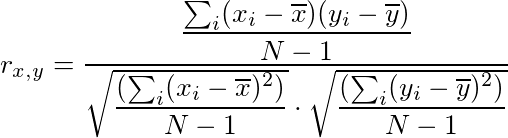
y_pred = [2, 2, 3, 4, 5, 5, 4, 2],y_true = [1, 2, 3, 4, 5, 6, 7, 8]? - Warren Weckesser0.3806076。 - 0xsxfloat64而不是float32运行tensorflow代码会发生什么? - Warren Weckesser