我正在使用Jupyter笔记本和pandas将多个csv文件导入python,其中一些文件没有正确的索引列。相反,使用需要操作的数据作为第一列。如何创建常规索引列作为第一列?这似乎是一个微不足道的问题,但我无法在任何地方找到有用的帮助。
我的数据框看起来像什么
我的数据框应该看起来像什么
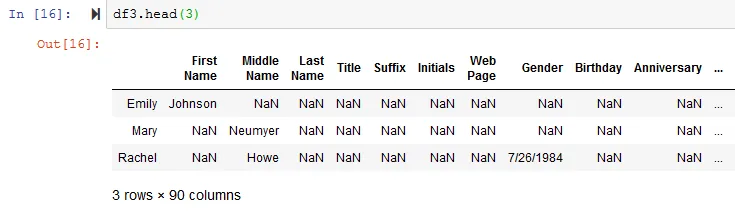{kind=link}
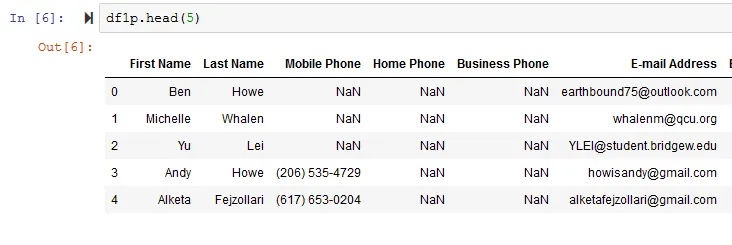{kind=link}
5个回答
6
请您尝试这个:
df.reset_index(inplace = True, drop = True)
如果这个有效,请告诉我。
- Suman Dey
2
请注意,通过这样做,您将失去当前用作索引的列。第二个示例来自文档。 - Nicolas Gervais
1是的,drop = True 将删除该列。df.reset_index(inplace = True) 应该可以工作。 - Suman Dey
1
当您读取csv文件时,请使用pandas.read_csv(index_col=#,*args)。如果它们没有适当的索引列,请设置index_col=False。
要更改现有DataFrame df的索引,请尝试使用方法df = df.reset_index()或df=df.set_index(#)。
- Adam
0
当您导入csv文件时,是否使用了index_col参数?根据文档,它应默认为None。如果您不使用该参数,则应该没问题。
无论如何,您都可以通过使用index_col=False来强制不使用列。从文档中可以看到:
注意:可以使用index_col=False来强制pandas不使用第一列作为索引,例如当您有一个每行末尾带有分隔符的格式错误文件时。
- Nicolas Gervais
0
由于您正在读取一些带有索引和一些不带索引的csv文件,并且似乎事先不知道哪些文件具有索引以及索引的名称是什么,我建议在pandas.read_csv()中不使用index_col参数。将其设置为False会忽略(可能)存在的索引,而将其设置为True似乎也无法解决问题,因为要么索引名称未知,要么根本没有索引。我也不建议直接使用data.reset_index(inplace=True)。
如果data是数据框,我建议从以下检查开始:
因为在尝试使这个工作时,可能已经向数据中添加了这个不需要的索引列。
为了保持旧索引,我会使用
从下次开始,我们将确保数据可以被读取。
因此,所有的数据框都将把它们的第一列设置为索引,这样可以使项目中的其余代码变得更简单。
如果data是数据框,我建议从以下检查开始:
if "Unnamed: 0" in data:
data.drop("Unnamed: 0", axis=1, inplace=True)
因为在尝试使这个工作时,可能已经向数据中添加了这个不需要的索引列。
为了保持旧索引,我会使用
data.index.name收集它们的名称,然后逐个替换。data.rename(columns={"indexname1": "raw_index"}, inplace=True)
data.rename(columns={"indexname2": "raw_index"}, inplace=True)
....
用于家族血统。
然后,
data.reset_index(inplace=True)
会为每个数据帧创建一个新的索引。如果更倾向于仅为没有索引的数据帧创建新索引,则可以对没有索引的数据帧执行先前的reset_index命令,然后对其余的数据帧执行data.set_index('indexname1')、data.set_index('indexname2')等命令。
然而,为了使数据读取更可持续且不那么繁琐,同时保持血统(例如旧索引),我强烈建议再次将所有数据帧写入文件。在完成上述步骤并确实第一列是(新/旧)索引之后,可以采用以下方法:
data.to_csv(filepath, index=True)
从下次开始,我们将确保数据可以被读取。
data = pd.read_csv(index_col=0)
因此,所有的数据框都将把它们的第一列设置为索引,这样可以使项目中的其余代码变得更简单。
- KLaz
-1
Python 3.8.5
pandas==1.2.4
pd.read_csv('file.csv', header=None)
我在文档中找到了解决方案: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html
- Isabely
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接