我之前询问过 如何仅对pandas数据框的最后一行进行样式设置?,并得到了完美答案来解决我提出的玩具问题。
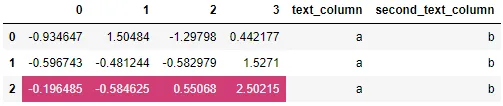
结果发现我应该将玩具问题更接近真实问题。考虑一个包含多列文本数据(我可以对其应用样式)的数据框:
import pandas as pd
import numpy as np
import seaborn as sns
cm = sns.diverging_palette(-5, 5, as_cmap=True)
df = pd.DataFrame(np.random.randn(3, 4))
df['text_column'] = 'a'
df['second_text_column'] = 'b'
df.style.background_gradient(cmap=cm)

然而,与之前的问题一样,我只想将此样式应用于最后一行。之前问题的答案是:
df.style.background_gradient(cmap=cm, subset=df.index[-1])
在这种情况下,会出现错误:
。
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
/usr/local/miniconda/lib/python3.7/site-packages/IPython/core/formatters.py in __call__(self, obj)
343 method = get_real_method(obj, self.print_method)
344 if method is not None:
--> 345 return method()
346 return None
347 else:
/usr/local/miniconda/lib/python3.7/site-packages/pandas/io/formats/style.py in _repr_html_(self)
161 Hooks into Jupyter notebook rich display system.
162 """
--> 163 return self.render()
164
165 @Appender(_shared_docs['to_excel'] % dict(
/usr/local/miniconda/lib/python3.7/site-packages/pandas/io/formats/style.py in render(self, **kwargs)
457 * table_attributes
458 """
--> 459 self._compute()
460 # TODO: namespace all the pandas keys
461 d = self._translate()
/usr/local/miniconda/lib/python3.7/site-packages/pandas/io/formats/style.py in _compute(self)
527 r = self
528 for func, args, kwargs in self._todo:
--> 529 r = func(self)(*args, **kwargs)
530 return r
531
/usr/local/miniconda/lib/python3.7/site-packages/pandas/io/formats/style.py in _apply(self, func, axis, subset, **kwargs)
536 if axis is not None:
537 result = data.apply(func, axis=axis,
--> 538 result_type='expand', **kwargs)
539 result.columns = data.columns
540 else:
/usr/local/miniconda/lib/python3.7/site-packages/pandas/core/frame.py in apply(self, func, axis, broadcast, raw, reduce, result_type, args, **kwds)
6485 args=args,
6486 kwds=kwds)
-> 6487 return op.get_result()
6488
6489 def applymap(self, func):
/usr/local/miniconda/lib/python3.7/site-packages/pandas/core/apply.py in get_result(self)
149 return self.apply_raw()
150
--> 151 return self.apply_standard()
152
153 def apply_empty_result(self):
/usr/local/miniconda/lib/python3.7/site-packages/pandas/core/apply.py in apply_standard(self)
255
256 # compute the result using the series generator
--> 257 self.apply_series_generator()
258
259 # wrap results
/usr/local/miniconda/lib/python3.7/site-packages/pandas/core/apply.py in apply_series_generator(self)
284 try:
285 for i, v in enumerate(series_gen):
--> 286 results[i] = self.f(v)
287 keys.append(v.name)
288 except Exception as e:
/usr/local/miniconda/lib/python3.7/site-packages/pandas/core/apply.py in f(x)
76
77 def f(x):
---> 78 return func(x, *args, **kwds)
79 else:
80 f = func
/usr/local/miniconda/lib/python3.7/site-packages/pandas/io/formats/style.py in _background_gradient(s, cmap, low, high, text_color_threshold)
941 smin = s.values.min()
942 smax = s.values.max()
--> 943 rng = smax - smin
944 # extend lower / upper bounds, compresses color range
945 norm = colors.Normalize(smin - (rng * low), smax + (rng * high))
TypeError: ("unsupported operand type(s) for -: 'str' and 'str'", 'occurred at index text_column')
<pandas.io.formats.style.Styler at 0x7f948dde7278>
这似乎是因为它正在尝试对text_column中的字符串执行操作。很好,那我怎样才能告诉它只适用于所有非文本列的最后一行?我可以明确给出要使用或避免的列名,但我不知道如何将其传递到这个晦涩的subset方法中。
我的运行版本是:
python version 3.7.3
pandas version 0.24.2