这是一种在两个密度图之间着色并计算该区域大小的方法。
set.seed(10)
dat = data.frame(x=c(rnorm(1000, 0, 5), rnorm(2000, 0, 1)),
group=c(rep("Bad", 1000), rep("Good", 2000)))
p1 = ggplot(dat) +
geom_density(aes(x=x, y=..count.., colour=group), lwd=1)
一些额外的计算用于阴影两个密度图之间的区域(改编自此SO问题):
pp1 = ggplot_build(p1)
dat2 = data.frame(x = pp1$data[[1]]$x[pp1$data[[1]]$group==1],
ymin=pp1$data[[1]]$y[pp1$data[[1]]$group==1],
ymax=pp1$data[[1]]$y[pp1$data[[1]]$group==2])
dat2$ymax[dat2$ymax < dat2$ymin] = dat2$ymin[dat2$ymax < dat2$ymin]
p1a = p1 +
geom_ribbon(data=dat2, aes(x=x, ymin=ymin, ymax=ymax), fill='yellow', alpha=0.5)
以下是两个图表:
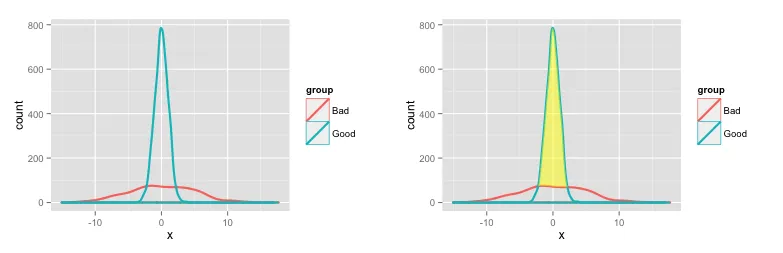
要获取特定范围内Good和Bad值的面积(数量),请对每个组使用density函数(或者您可以继续使用上面从ggplot中提取的数据,但这种方式可以更直接地控制密度分布生成的方式):
bad = density(dat$x[dat$group=="Bad"],
n=1024, from=min(dat$x), to=max(dat$x))
good = density(dat$x[dat$group=="Good"],
n=1024, from=min(dat$x), to=max(dat$x))
counts = tapply(dat$x, dat$group, length)
bad$y = counts[1]/sum(bad$y) * bad$y
good$y = counts[2]/sum(good$y) * good$y
sum(good$y[good$y > bad$y])
[1] 1931.495
sum(bad$y[good$y > bad$y])
[1] 317.7315