我有一个包含一百万行数据和30列数据的df。现在我想要在df中添加另一列名为category的数据。这个category是df2中的一列,其中包含大约700个rows和另外两个columns,这两个columns与df中的两个columns匹配。
我开始先在df2和df中设置一个匹配的index,但是df2中的一些index并不存在于df中。
df2中的其余列称为AUTHOR_NAME和CATEGORY。
df中相关的一列被称为AUTHOR_NAME。
在df中的某些AUTHOR_NAME在df2中不存在,反之亦然。
我需要的指令是:当df中的index与df2中的index匹配,并且title在df中与title在df2中匹配时,将category添加到df中;否则,在category中添加NaN。
示例数据:
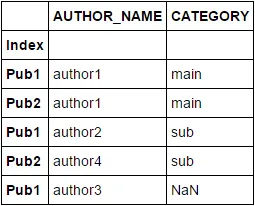
df2
AUTHOR_NAME CATEGORY
Index
Pub1 author1 main
Pub2 author1 main
Pub3 author1 main
Pub1 author2 sub
Pub3 author2 sub
Pub2 author4 sub
df
AUTHOR_NAME ...n amount of other columns
Index
Pub1 author1
Pub2 author1
Pub1 author2
Pub1 author3
Pub2 author4
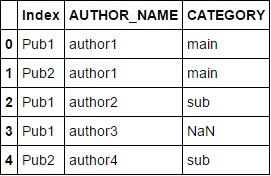
expected_result
AUTHOR_NAME CATEGORY ...n amount of other columns
Index
Pub1 author1 main
Pub2 author1 main
Pub1 author2 sub
Pub1 author3 NaN
Pub2 author4 sub
df2.merge(df,left_index=True,right_index=True,how='left', on=['AUTHOR_NAME']),那么我的df会比它应该的大小大三倍。所以我想也许合并不是解决这个问题的正确方法。我真正想做的是使用
df2作为查找表,然后根据是否满足某些条件来返回type值到df。def calculate_category(df2, d):
category_row = df2[(df2["Index"] == d["Index"]) & (df2["AUTHOR_NAME"] == d["AUTHOR_NAME"])]
return str(category_row['CATEGORY'].iat[0])
df.apply(lambda d: calculate_category(df2, d), axis=1)
然而,这给了我一个错误:
IndexError: ('index out of bounds', u'occurred at index 7614')
on和left_index/right_index是否可以一起使用。也许你需要使用on=['Index', 'AUTHOR_NAME'](或类似的内容)。而且我不确定在df2.merge(df,...)中哪个数据框是左侧的。也许你需要使用how="right"或者pd.merge(left=df, right=df2, ...)。 - furas