我可以帮您将JSON转换为Pandas数据框。以下是需要翻译的内容:
我使用以下代码从GCP读取文件:
我想要将一个JSON转换为Pandas数据框。
我的JSON长这样:
{
"country1":{
"AdUnit1":{
"floor_price1":{
"feature1":1111,
"feature2":1112
},
"floor_price2":{
"feature1":1121
}
},
"AdUnit2":{
"floor_price1":{
"feature1":1211
},
"floor_price2":{
"feature1":1221
}
}
},
"country2":{
"AdUnit1":{
"floor_price1":{
"feature1":2111,
"feature2":2112
}
}
}
}
我使用以下代码从GCP读取文件:
我使用以下代码从GCP读取文件:
project = Context.default().project_id
sample_bucket_name = 'my_bucket'
sample_bucket_path = 'gs://' + sample_bucket_name
print('Object: ' + sample_bucket_path + '/json_output.json')
sample_bucket = storage.Bucket(sample_bucket_name)
sample_bucket.create()
sample_bucket.exists()
sample_object = sample_bucket.object('json_output.json')
list(sample_bucket.objects())
json = sample_object.read_stream()
我的目标是获取类似于以下样式的Pandas dataframe:
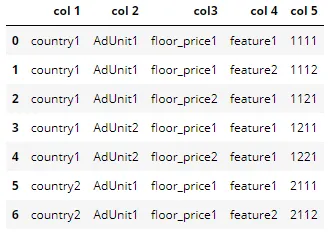
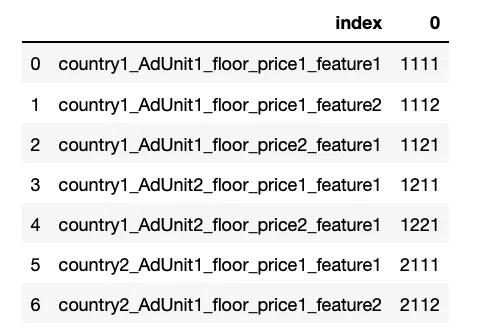
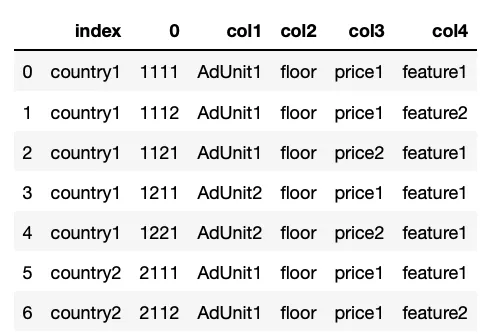
我尝试使用json_normalize,但没有成功。
{kind=link}
{kind=link}
pd.read_json怎么样? - Nicolas Gervaispd.read_json(json.dumps(json_dictionary))。 - Zionsof