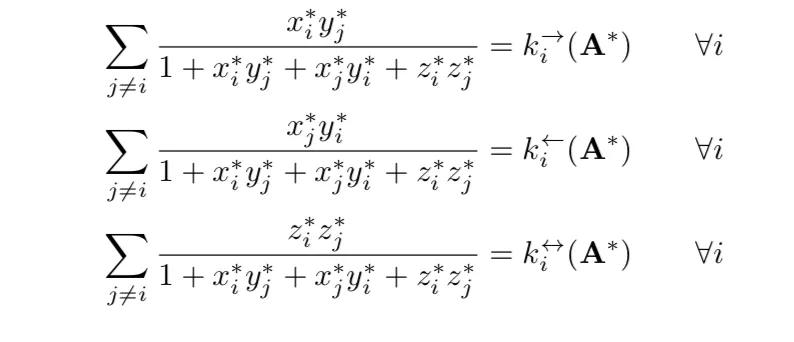正如@Bob所建议的那样,第一步必须是将您的内部函数向量化。之后,回到您的主要问题:这不是正确的问题,因为
fsolve只是hybr算法的包装器,而该算法已作为root的一个选项提供;以及- 在性能之前担心正确性。
几乎可以肯定的是,优化器放弃了您的问题,结果是无效的。我唯一能够说服它收敛的情况是n=4和Levenberg-Marquardt算法。如果(四年后)您仍然需要解决此问题,我建议将问题带到像Mathematics StackExchange这样的不同社区。但与此同时,这里有一个具有一个收敛解的向量化示例:
import numpy as np
from numpy.random import default_rng
from scipy.optimize import root
def lhs(xyz: np.ndarray) -> np.ndarray:
x, y, z = xyz[..., np.newaxis]
n = len(x)
coeff = (1 - np.eye(n)) / (1 + x*y.T + x.T*y + z*z.T)
numerator = np.stack((
x * y.T,
x.T * y,
z.T * z,
))
result = (numerator * coeff).sum(axis=2)
return result
def to_root(w: np.ndarray, recs: np.ndarray) -> np.ndarray:
xyz = w.reshape((3, -1))
rhs = lhs(xyz) - recs
return rhs.ravel()
def test_data(n: int = 4) -> tuple[np.ndarray, np.ndarray]:
rand = default_rng(seed=0)
secret_solution = rand.uniform(-1, 1, (3, n))
recs = lhs(secret_solution)
return secret_solution, recs
def method_search() -> None:
secret_solution, recs = test_data()
for method in ('hybr', 'lm', 'broyden1', 'broyden2', 'anderson',
'linearmixing', 'diagbroyden', 'excitingmixing',
'krylov', 'df-sane'):
try:
result = root(
to_root, x0=np.ones_like(recs),
args=(recs,), method=method,
options={
'maxiter': 5_000,
'maxfev': 5_000,
},
)
except Exception:
continue
print(method, result.message,
f'nfev={getattr(result, "nfev", None)} nit={getattr(result, "nit", None)}')
print('Estimated RHS:')
print(lhs(result.x.reshape((3, -1))))
print('Estimated error:')
print(to_root(result.x, recs))
print()
def successful_example() -> None:
n = 4
print('n=', n)
secret_solution, recs = test_data(n=n)
result = root(
to_root, x0=np.ones_like(recs),
args=(recs,), method='lm',
)
print(result.message)
print('function evaluations:', result.nfev)
error = to_root(result.x, recs)
print('Error:', error.dot(error))
print()
if __name__ == '__main__':
successful_example()
n= 4
The relative error between two consecutive iterates is at most 0.000000
function evaluations: 1221
Error: 8.721381160163159e-30