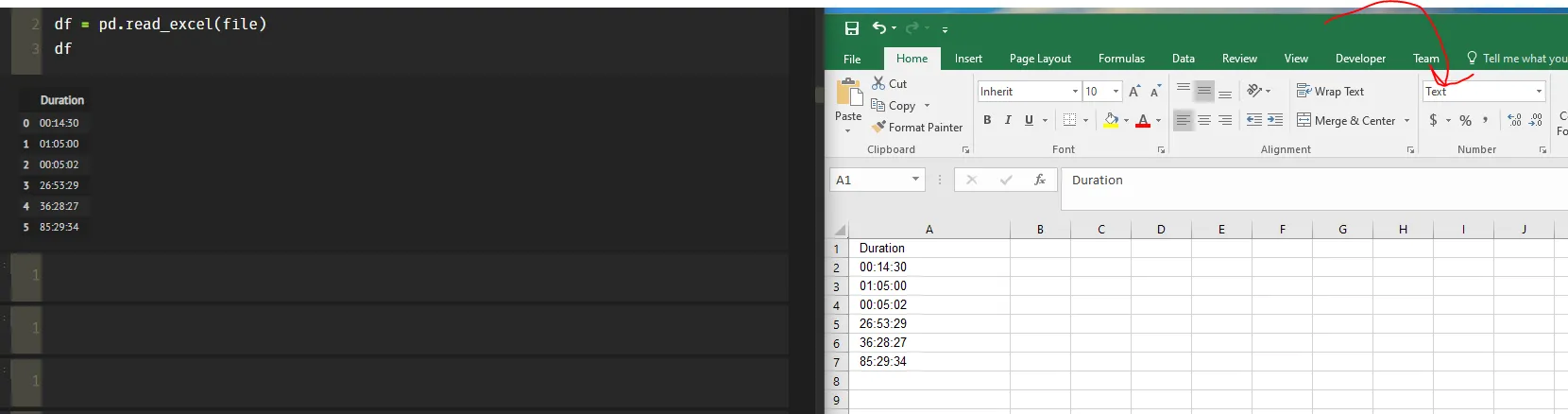
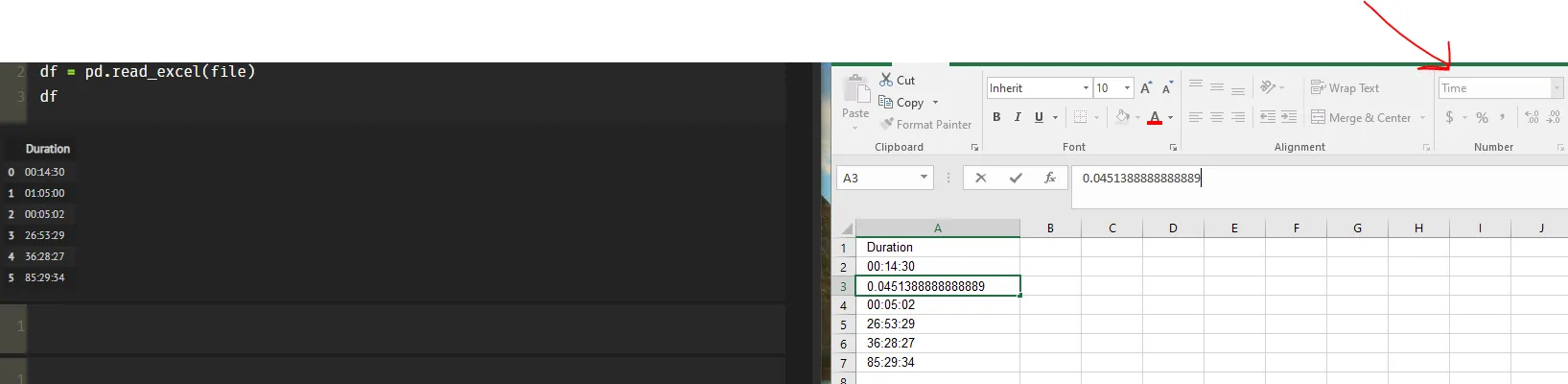
我有一个包含时间长度列的xlsx文件,格式为HH:MM:SS。我认为最好将这一列作为timedelta数据类型处理,但我无法让read_excel函数完成此操作。
要复制以下内容到xlsx文件以重现此问题:
Duration
0 00:14:30
1 01:05:00
2 00:05:02
3 26:53:29
4 36:28:27
5 85:29:34
然后使用类似以下方式读取xlsx文件:
df = pd.read_excel('../data/test.xlsx', engine='openpyxl', index_col=0)
你应该得到一个数据框,其中包含混合了时间和日期时间对象的数据:
Duration
0 00:14:30
1 01:05:00
2 00:05:02
3 1900-01-01 02:53:29
4 1900-01-01 12:28:27
5 1900-01-03 13:29:34
我尝试过使用read_excel的选项,例如dtype和converters,但似乎没有任何效果。
我发现将所有内容转换为datetime格式的唯一方法是通过以下方式将时间值添加到1900-01-01 00:00:00来实现。
def clean_durations(s):
ss = s.copy()
for i,value in s.items():
try:
ss[i] = datetime.combine(date(1900, 1, 1), value)
except TypeError as e:
ss[i] = value + timedelta(days=1) # add an extra day for durations interpreted as datetime
ss = pd.to_datetime(ss) - pd.to_datetime('1900-01-01 00:00:00')
return ss
df = pd.read_excel('../data/test.xlsx', engine='openpyxl', index_col=0, parse_dates=True)
df['Duration'] = clean_durations(df['Duration'])
导致所期望的结果:
Duration
0 0 days 00:14:30
1 0 days 01:05:00
2 0 days 00:05:02
3 1 days 02:53:29
4 1 days 12:28:27
5 3 days 13:29:34
这感觉像是我在构建本应该已经成为pandas一部分的东西。
有人能否提供一种直接使用pandas read_excel或类似方法实现相同功能的方法?