我有一组由2D数组(点数,坐标数)定义的曲线。我正在使用豪斯多夫距离为它们计算距离矩阵。我的当前代码如下。不幸的是,当每个曲线都有50-100个3D点时,500-600个曲线的速度太慢了。有没有更快的方法?
def distanceBetweenCurves(C1, C2):
D = scipy.spatial.distance.cdist(C1, C2, 'euclidean')
#none symmetric Hausdorff distances
H1 = np.max(np.min(D, axis=1))
H2 = np.max(np.min(D, axis=0))
return (H1 + H2) / 2.
def distanceMatrixOfCurves(Curves):
numC = len(Curves)
D = np.zeros((numC, numC))
for i in range(0, numC-1):
for j in range(i+1, numC):
D[i, j] = D[j, i] = distanceBetweenCurves(Curves[i], Curves[j])
return D
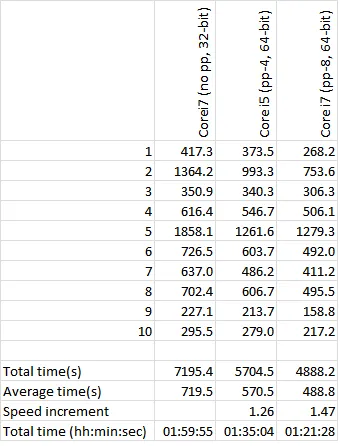
scipy.spatial.distance.cdist是慢的部分还是distanceMatrixOfCurves里面的双重循环?如果这些曲线是凸的,那么可能可以优化第一个潜在的缓慢部分。这些曲线是否相交或包含在其他曲线中?我觉得你可以重用早先发现的距离来加速新的计算。当然,这只是胡言乱语,我自己也遇到了类似于 min(min(..)) 测量的问题,并且难以将这些考虑到一般情况中。你有尝试过或思考过代码之外的内容吗? - mmgp- 你真的需要完整的矩阵
- 你尝试过使用列表推导式或
- ev-brD吗?还是只需要上三角或下三角矩阵就可以了?这种形式的D[i,j] = D[j,i] =...对于数据局部性来说绝对不好。map代替双重循环吗?