这里的答案准确合理,但并没有完全回答你的问题:
“什么是sigma剪辑?它是否只适用于某些数据?”
如果我们想使用均值(mu)和标准差(sigma)来确定阈值,以便在我们有理由怀疑那些极端值是错误时将其排除在外(而不仅仅是非常高/低的值),我们不希望使用包括这些错误的数据集来计算mu/sigma。
样本问题:您需要计算温度传感器的阈值,以指示温度何时“高”-但有时传感器会给出不可能的读数,如“太阳表面”高。
想象一下一个看起来像这样的系列:
thisSeries = np.array([1,2,3,4,1,2,3,4,5,3,4,5,3, 500, 1000])
最后两个值看起来像明显的错误-但如果我们使用典型的统计函数(如正态PPF),它将默认假定这些异常值属于分布,并相应地执行其计算:st.norm.ppf(.975,thisSeries.mean(),thisSeries.std())。
631.5029013468446
使用双侧5%的异常值阈值(意味着我们将拒绝下限和上限的2.5%),它告诉我500不是异常值。即使我使用单侧阈值为0.95(拒绝上限5%),它也会给出546作为异常值限制,因此500被认为是非异常值。
Sigma-clipping通过专注于四分位距并使用中位数而不是平均值来工作,因此阈值不会在极端值的影响下计算。
thisDF = pd.DataFrame(thisSeries, columns=["value"])
intermed="value"
factor=5
quartiles = np.percentile(thisSeries, [25, 50, 75])
mu, sig = quartiles[1], 0.74 * (quartiles[2] - quartiles[0])
queryString = '({} < @mu - {} * @sig) | ({} > @mu + {} * @sig)'.format(intermed, factor, intermed, factor)
print(mu + 5 * sig)
10.4
print(thisDF.query(queryString))
500
1000
在因子为5的情况下,两个离群值都被正确地隔离出来,并且阈值在合理的10.4处 - 合理之处在于系列的“干净”部分是[1,2,3,4,1,2,3,4,5,3,4,5,3]。(此处的“factor”是应用于阈值的标量)
因此,sigma截断是一种识别离群值的方法,它不受离群值本身变形影响,并且虽然它可以在许多情况下使用,但它在你怀疑极端值不仅仅是应该被视为数据集一部分的高/低值,而是错误时表现得非常出色。
以下是极端值是分布的一部分和可能是错误或者是如此极端以至于会影响其余数据分析的差异的说明。
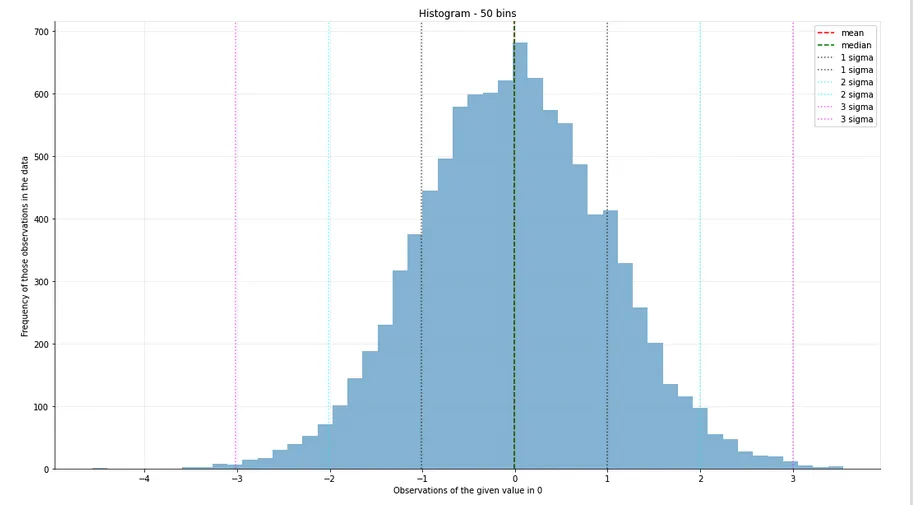
以上数据是合成的,但您可以看到在此数据集中最高的值并没有扭曲统计数据。
现在这里有一个以相同方式生成的数据集,但是这次注入了一些人为的异常值(大于40):
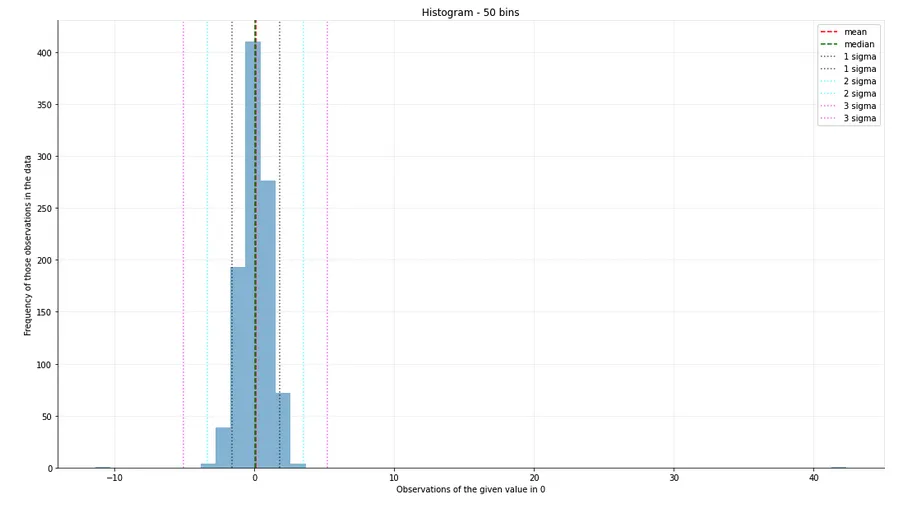
如果我使用sigma-clip,我可以回到原始的直方图和统计数据,并将它们有用地应用于数据集。但是,sigma-clipping真正发挥作用的地方是在现实世界的场景中,其中错误数据很常见。这里有一个使用真实数据的例子——我的心率监测器的历史观测记录。让我们先看一下没有进行sigma-clipping的直方图:
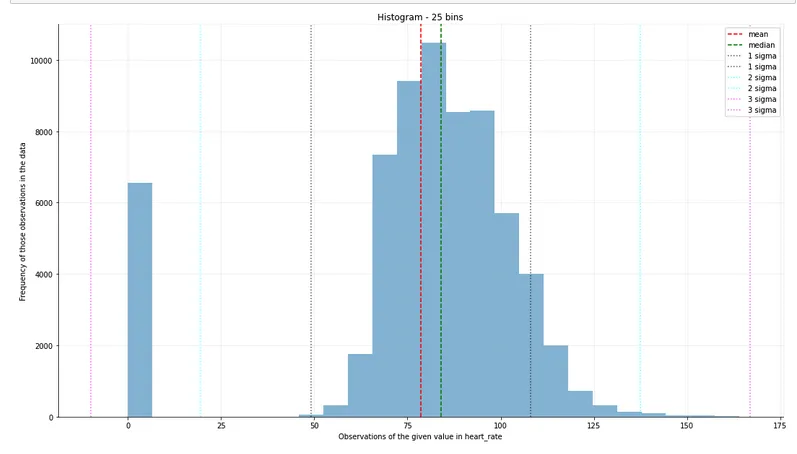
我是一个相当冷静的人,但我知道我的心率从来不会降到零。Sigma-clipping轻松处理这个问题,现在我们可以查看心率观察的真实分布:
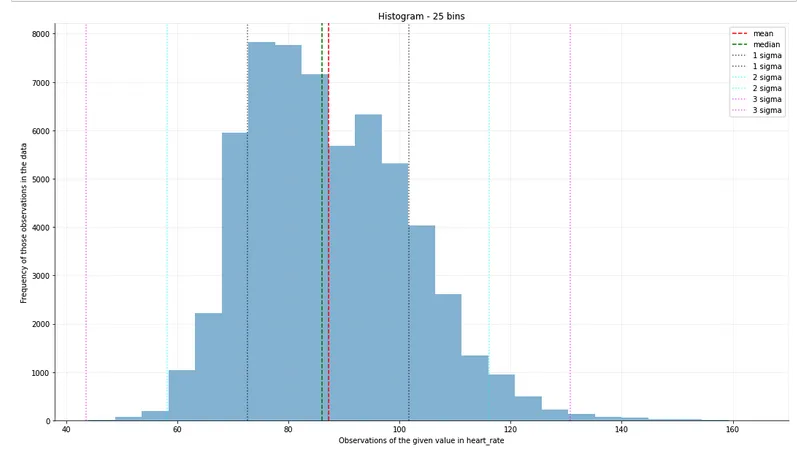
现在,您可能具备某些领域知识,使您能够手动确定异常值阈值或过滤器。这就是我们为什么可能使用sigma-clipping的最后一个微妙之处 - 在完全由自动化处理数据的情况下,或者我们没有与测量或采取方式相关的领域知识时,我们就没有任何有根据的基础来进行过滤器或阈值语句。
很容易说心率为0不是有效的测量结果 - 但是10呢?200呢?如果心率是我们正在进行的数千种不同测量中的一种,那该怎么办?在这种情况下,维护一组手动定义的阈值和过滤器将会过于繁琐。