我想绘制热力图。
我有一个100k*100k的方阵(50Gb(csv),右上角填有数字,其余填0)。
我想问一下,“如何使用R在这个巨大的数据集上绘制热力图?”
我正在尝试在大内存机器上运行此代码。
d = read.table("data.csv", sep=",")
d = as.matrix(d + t(d))
heatmap(d)
我尝试了一些像heatmap.2(在gplots中)之类的库。
但它们需要太多时间和内存。
我想绘制热力图。
我有一个100k*100k的方阵(50Gb(csv),右上角填有数字,其余填0)。
我想问一下,“如何使用R在这个巨大的数据集上绘制热力图?”
我正在尝试在大内存机器上运行此代码。
d = read.table("data.csv", sep=",")
d = as.matrix(d + t(d))
heatmap(d)
我尝试了一些像heatmap.2(在gplots中)之类的库。
但它们需要太多时间和内存。
# example of big mx 10k x 10 k
bigMx <- matrix(rnorm(10000*10000,mean=0,sd=100),10000,10000)
# here we downsample the big matrix 10k x 10k to 100x100
# by averaging each submatrix
downSampledMx <- matrix(NA,100,100)
subMxSide <- nrow(bigMx)/nrow(downSampledMx)
for(i in 1:nrow(downSampledMx)){
rowIdxs <- ((subMxSide*(i-1)):(subMxSide*i-1))+1
for(j in 1:ncol(downSampledMx)){
colIdxs <- ((subMxSide*(j-1)):(subMxSide*j-1))+1
downSampledMx[i,j] <- mean(bigMx[rowIdxs,colIdxs])
}
}
# NA to disable the dendrograms
heatmap(downSampledMx,Rowv=NA,Colv=NA)

当然,由于您的矩阵很大,计算downSampledMx可能需要一些时间,但这是可行的。
编辑:
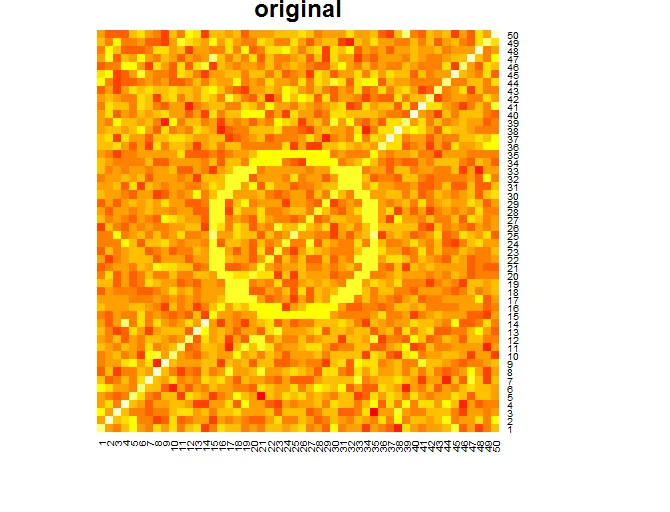
我认为下采样应该保留可识别的“宏观模式”,例如,看以下示例:
# create a matrix with some recognizable pattern
set.seed(123)
bigMx <- matrix(rnorm(50*50,mean=0,sd=100),50,50)
diag(bigMx) <- max(bigMx) # set maximum value on the diagonal
# set maximum value on a circle centered on the middle
for(i in 1:nrow(bigMx)){
for(j in 1:ncol(bigMx)){
if(abs((i - 25)^2 + (j - 25)^2 - 10^2) <= 16)
bigMx[i,j] <- max(bigMx)
}
}
# plot the original heatmap
heatmap(bigMx,Rowv=NA,Colv=NA, main="original")
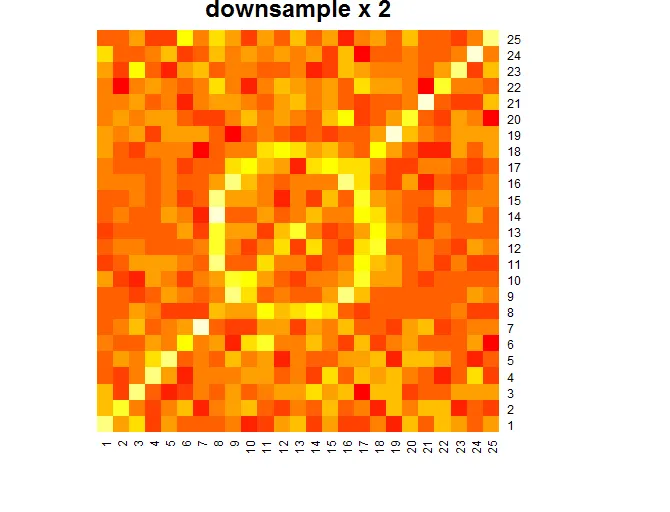
# function used to down sample
downSample <- function(m,newSize){
downSampledMx <- matrix(NA,newSize,newSize)
subMxSide <- nrow(m)/nrow(downSampledMx)
for(i in 1:nrow(downSampledMx)){
rowIdxs <- ((subMxSide*(i-1)):(subMxSide*i-1))+1
for(j in 1:ncol(downSampledMx)){
colIdxs <- ((subMxSide*(j-1)):(subMxSide*j-1))+1
downSampledMx[i,j] <- mean(m[rowIdxs,colIdxs])
}
}
return(downSampledMx)
}
# downsample x 2 and plot heatmap
downSampledMx <- downSample(bigMx,25)
heatmap(downSampledMx,Rowv=NA,Colv=NA, main="downsample x 2")
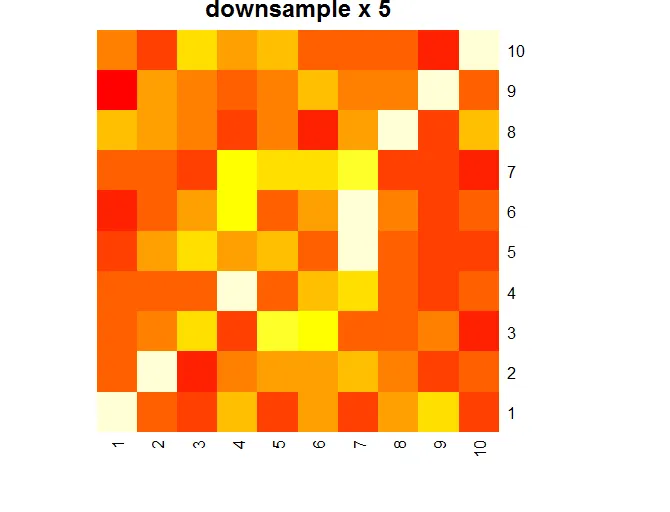
# downsample x 5 and plot heatmap
downSampledMx <- downSample(bigMx,10)
heatmap(downSampledMx,Rowv=NA,Colv=NA, main="downsample x 5")
这是三个热力图: