它不是一个立方回归样条,但它确实清晰地分离了您问题的两个组成部分。在这里,我展示如何使用薄板样条来实现这一点,它是mgcv::gam()中的默认基础。
使用您的设置加上我的用于处理广义加性模型(GAM)的软件包
library("mgcv")
library("gratia")
library("ggplot2")
set.seed(1)
df <- data.frame(x = seq(0,1, length = 100),
y = 0.5*x + x^2 + rnorm(100))
我们首先看一下带有第三阶导数惩罚的薄板样条的基础:
basis(s(x, m = 3), data = df) |>
draw() +
facet_wrap(~ bf)
这导致
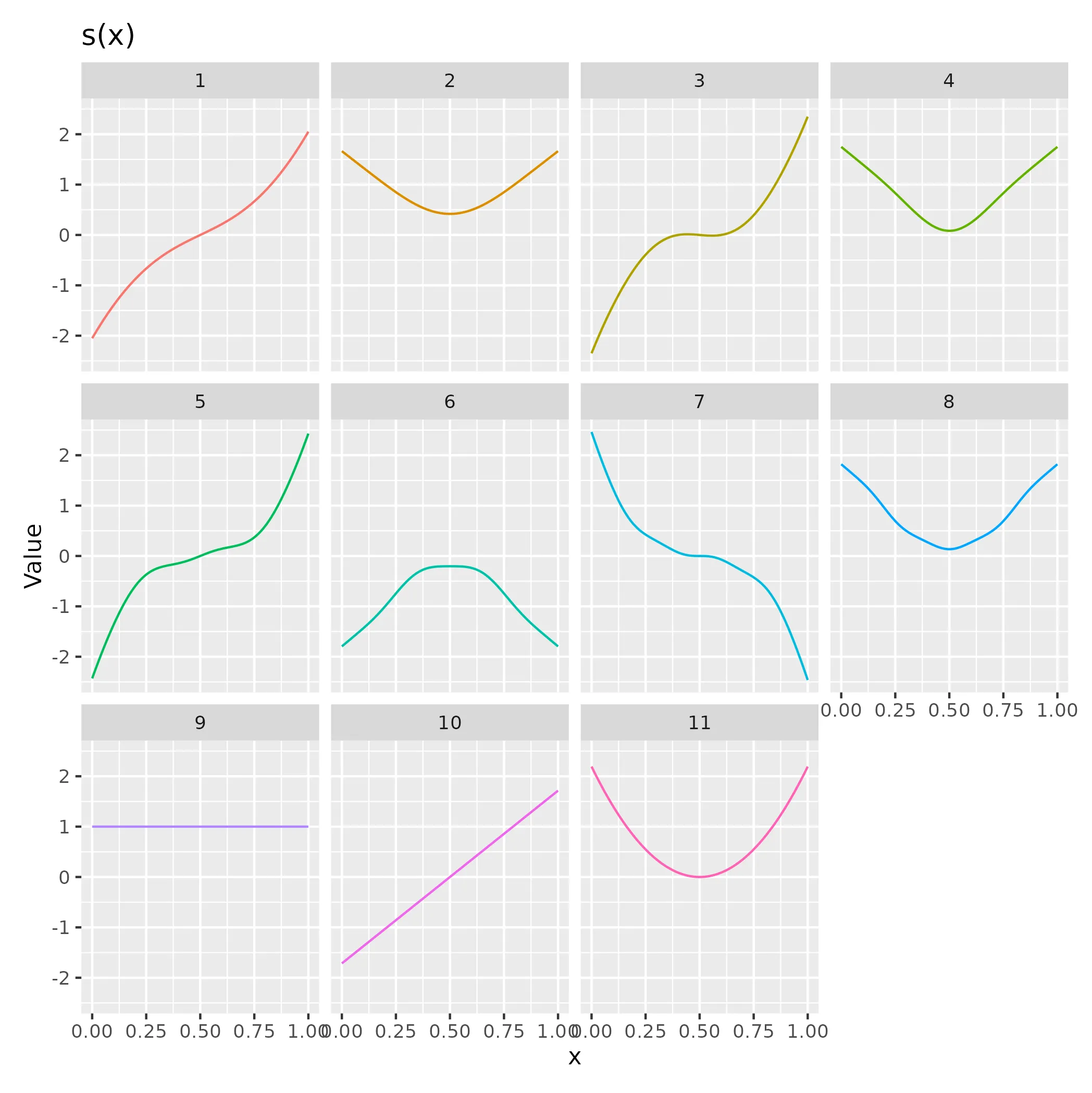
最后三个基函数(9、10和11)位于惩罚的零空间中;它们不受惩罚的影响,因为它们在任何地方都具有0的三阶导数。函数11是一个二次项。函数9与模型截距混淆,并将通过对基础设置总和为零的约束来从基础中删除;这是默认约束条件,当拟合GAM时,gam()默认执行此操作。
假设薄板样条可以使用,则您要拟合的GAM如下:
m <- gam(y ~ s(x, m = 3), data = df, method = "REML")
summary(m)
根据数据模拟的方式,该模型使用了2个EDF,这是我们所期望的。
> summary(m)
Family: gaussian
Link function: identity
Formula:
y ~ s(x, m = 3)
Parametric coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.6939 0.0907 7.651 1.47e-11 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Approximate significance of smooth terms:
edf Ref.df F p-value
s(x) 2 2 11.1 4.56e-05 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
R-sq.(adj) = 0.17 Deviance explained = 18.6%
-REML = 134.45 Scale est. = 0.82259 n = 100
如果您想对样条比二次多项式进行正式测试,那么我们可以重新拟合上述模型,但是通过
poly(x, 2)将所需的项作为参数项包含在内,但修改薄板样条的基础以消除惩罚空间中的所有函数。我们通过设置
m = c(3,0)来移除零空间:
basis(s(x, m = c(3, 0)), data = df) |>
draw() +
facet_wrap(~ bf)
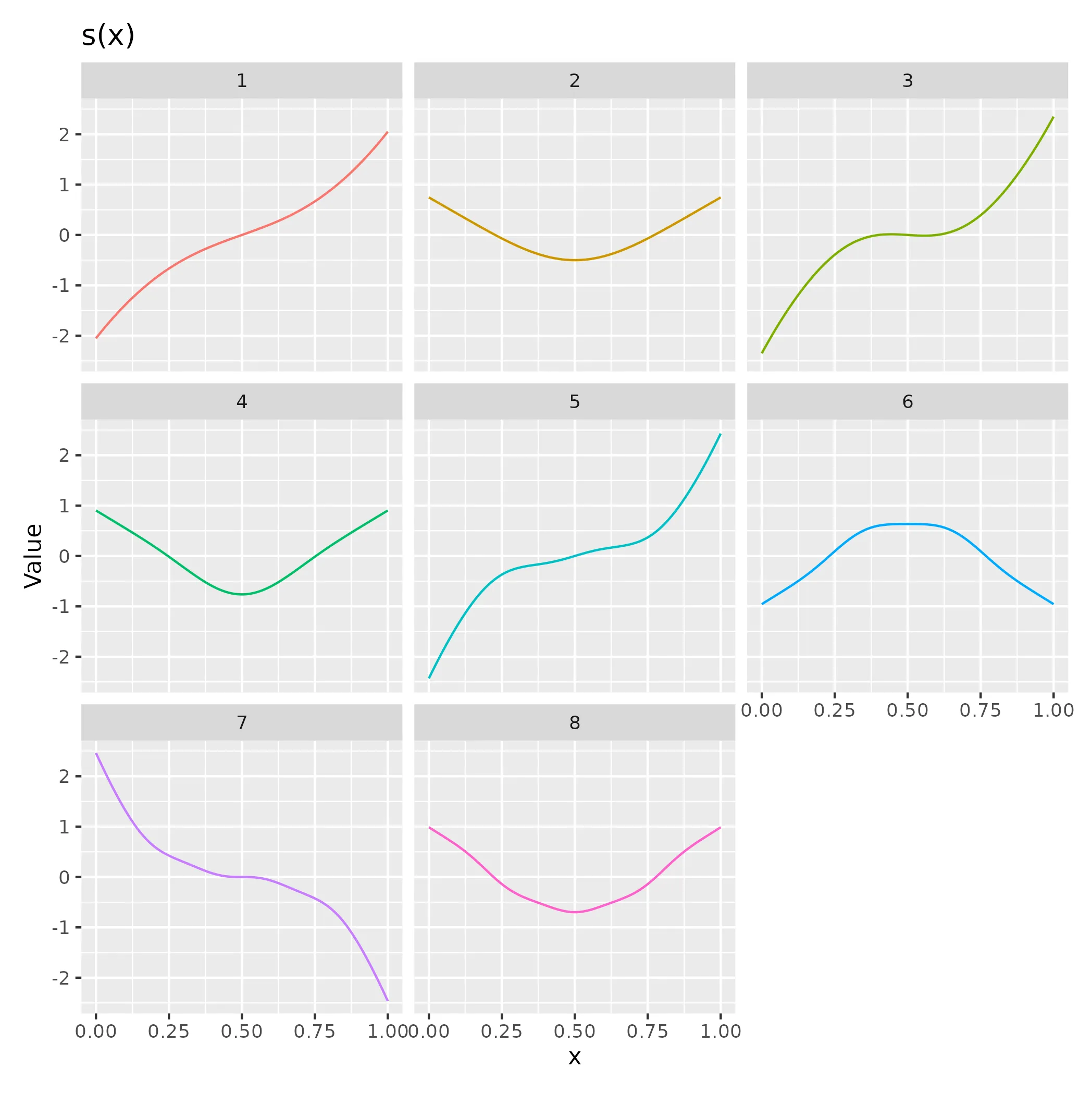
注意函数9、10和11不再在基础中找到。这将使我们能够隔离样条中超过二次的波动性组件,将二阶多项式波动性留给模型中的参数项。
m0 <- gam(y ~ poly(x, 2) + s(x, m = c(3, 0)), data = df, method = "REML")
summary(m0)
最后一行产生了
> summary(m0)
Family: gaussian
Link function: identity
Formula:
y ~ poly(x, 2) + s(x, m = c(3, 0))
Parametric coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.6939 0.0907 7.651 1.47e-11 ***
poly(x, 2)1 4.2437 0.9113 4.657 1.02e-05 ***
poly(x, 2)2 0.5129 0.9074 0.565 0.573
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Approximate significance of smooth terms:
edf Ref.df F p-value
s(x) 0.0001194 8 0 0.72
R-sq.(adj) = 0.17 Deviance explained = 18.6%
-REML = 130.47 Scale est. = 0.82259 n = 100
正如我们之前所看到的,超二次波动性非常小,我们未能拒绝零假设,即 f(x) === 0。
我认为您可以使用B样条基函数来实现此操作,这样可以控制多项式的阶数和惩罚项的阶数(不像立方回归样条基函数,它固定为由分段三次多项式组成,并带有二阶导数惩罚):
set.seed(1)
df2 <- data.frame(x = seq(0,1, length = 100),
y = 0.5*x + x^2 + (0.1 * (x^3)) + rnorm(100))
m1 <- gam(y ~ s(x, bs = "bs", m = c(3,3)),
data = df2, method = "REML")
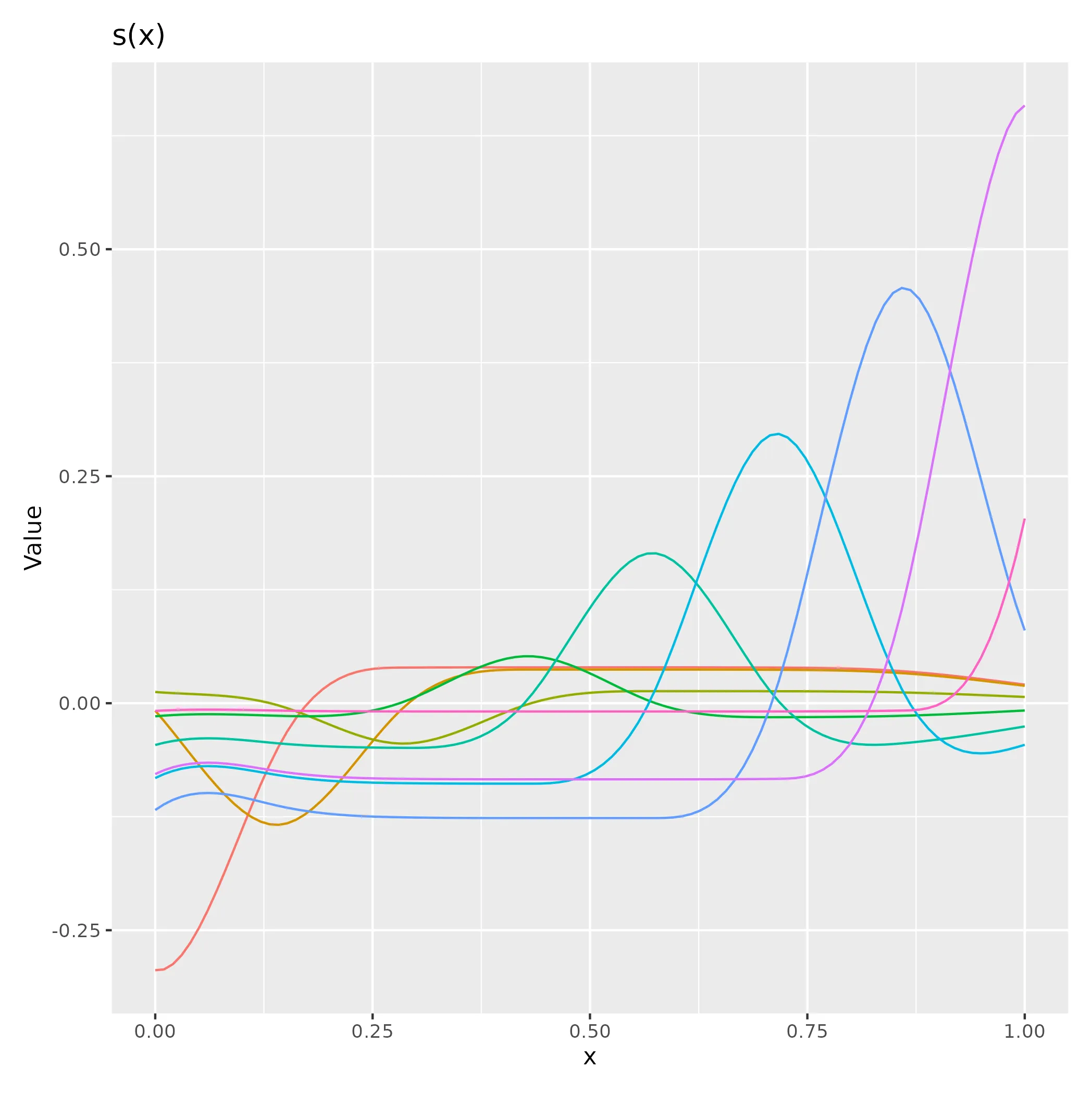
这将惩罚具有非零三阶导数的函数,因此不应该惩罚基础的线性和二次函数。只是它如何做到这一点就不那么清楚了,而且你肯定不能像对CRS那样解释系数(对于bs =“cr”基础也不能这样解释-绘制s(x,bs =“cr”)的基础函数以了解原因)。这是使用B样条基础的m1拟合基础函数的样子。
basis(m1) |>
draw()
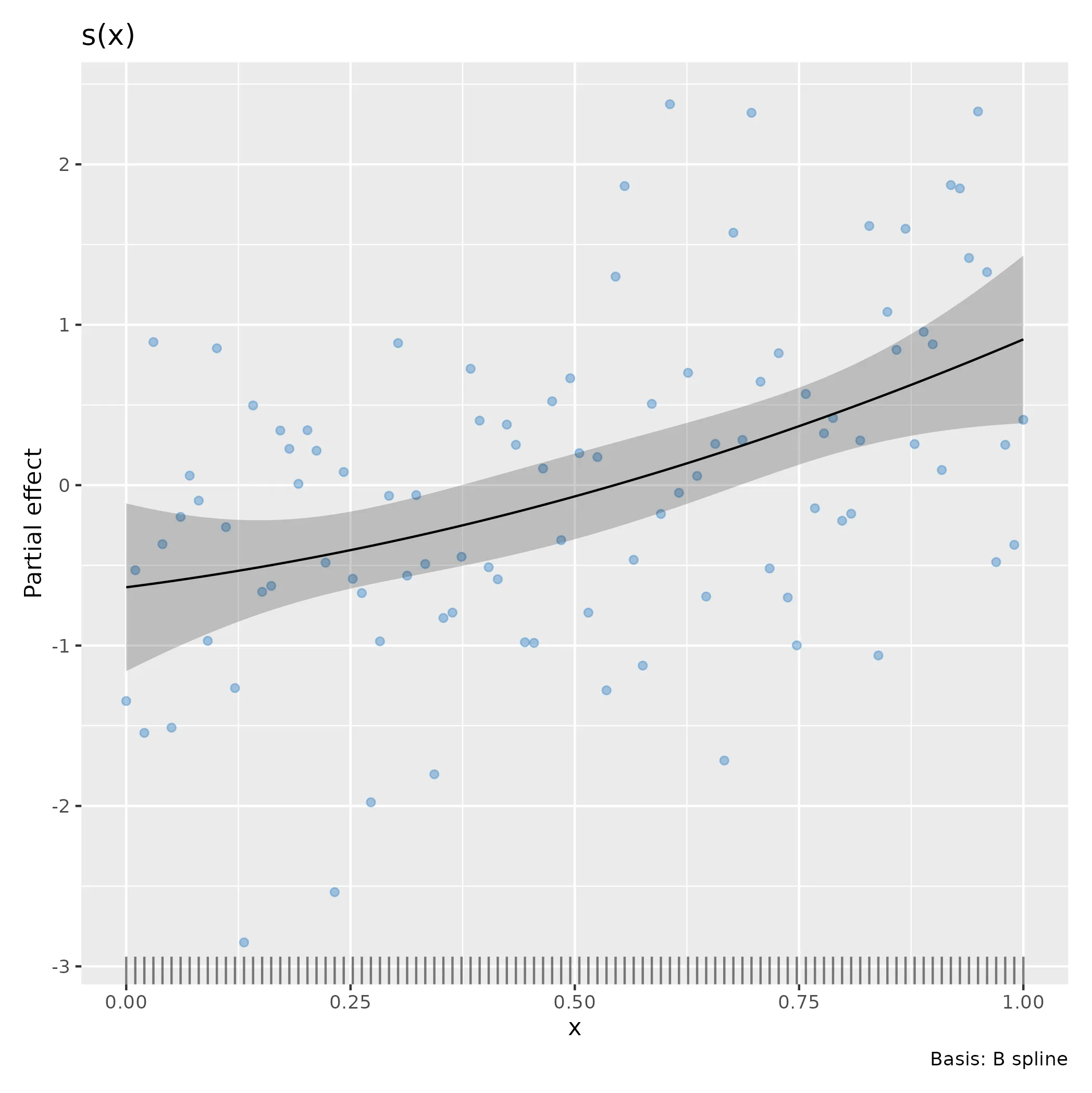
拟合的函数必须看起来像,因为估计的样条是:
draw(m1)
lm中正确的方法可能是使用poly(x,2),然后与poly(x,3)进行比较,但这可能不适用于mgcv方法。您可以使用I(x^2)和I(x^3)将二次和三次项强制输入公式,但这样会失去poly的正交特性。在您所在领域的“标准方法”是否了解当二次和三次项输入回归公式时出现的统计问题?(注意:在R中,您不能使用x^2和x^3来实现此目的。) - IRTFM