如何确定shap_values[i]的索引对应于输出的哪个类别?
shap_values[i]是第i个类别的SHAP值。第i个类别是根据您使用的编码模式(例如LabelEncoder、pd.factorize等)而定的。
您可以尝试以下提示:
from sklearn.preprocessing import LabelEncoder
labels = [
"Gusto",
"Kestrel 200 SCI Older Road Bike",
"Vilano Aluminum Road Bike 21 Speed Shimano",
"Fixie",
]
le = LabelEncoder()
y = le.fit_transform(labels)
encoding_scheme = dict(zip(y, labels))
pprint(encoding_scheme)
{0: 'Fixie',
1: 'Gusto',
2: 'Kestrel 200 SCI Older Road Bike',
3: 'Vilano Aluminum Road Bike 21 Speed Shimano'}
所以,例如对于这个特定案例,
shap_values[3] 是针对
'Vilano Aluminum Road Bike 21 Speed Shimano' 的。
为了进一步理解如何解释SHAP值,让我们准备一个包含100个特征和10个类别的多类分类的合成数据集。
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from shap import TreeExplainer
from shap import summary_plot
X, y = make_classification(1000, 100, n_informative=8, n_classes=10)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
print(X_train.shape)
(750, 100)
目前我们有一个包含750行、100个特征和10个类别的训练数据集。
让我们训练RandomForestClassifier并将其输入给TreeExplainer:
clf = RandomForestClassifier(n_estimators=100, max_depth=3)
clf.fit(X_train, y_train)
explainer = TreeExplainer(clf)
shap_values = np.array(explainer.shap_values(X_train))
print(shap_values.shape)
(10, 750, 100)
10:班级数量。所有SHAP值被组织成10个数组,每个班级一个数组。
750:数据点数量。我们有每个数据点的本地SHAP值。
100:特征数量。我们有每个特征的SHAP值。
例如,对于“第3班级”,您将会有:
print(shap_values[3].shape)
(750, 100)
750:每个数据点的SHAP值
100:每个特征的SHAP值贡献
最后,您可以运行一次健全性检查,确保模型的真实预测与
shap预测相同。
为此,我们将(1)交换
shap_values的前两个维度,(2)对所有特征按类别求和SHAP值,(3)将SHAP值添加到基准值中。
shap_values_ = shap_values.transpose((1,0,2))
np.allclose(
clf.predict_proba(X_train),
shap_values_.sum(2) + explainer.expected_value
)
True
然后您可以继续查看
summary_plot,它将根据每个类别的SHAP值显示特征排名。对于类别3,它将显示如下内容:
summary_plot(shap_values[3],X_train)
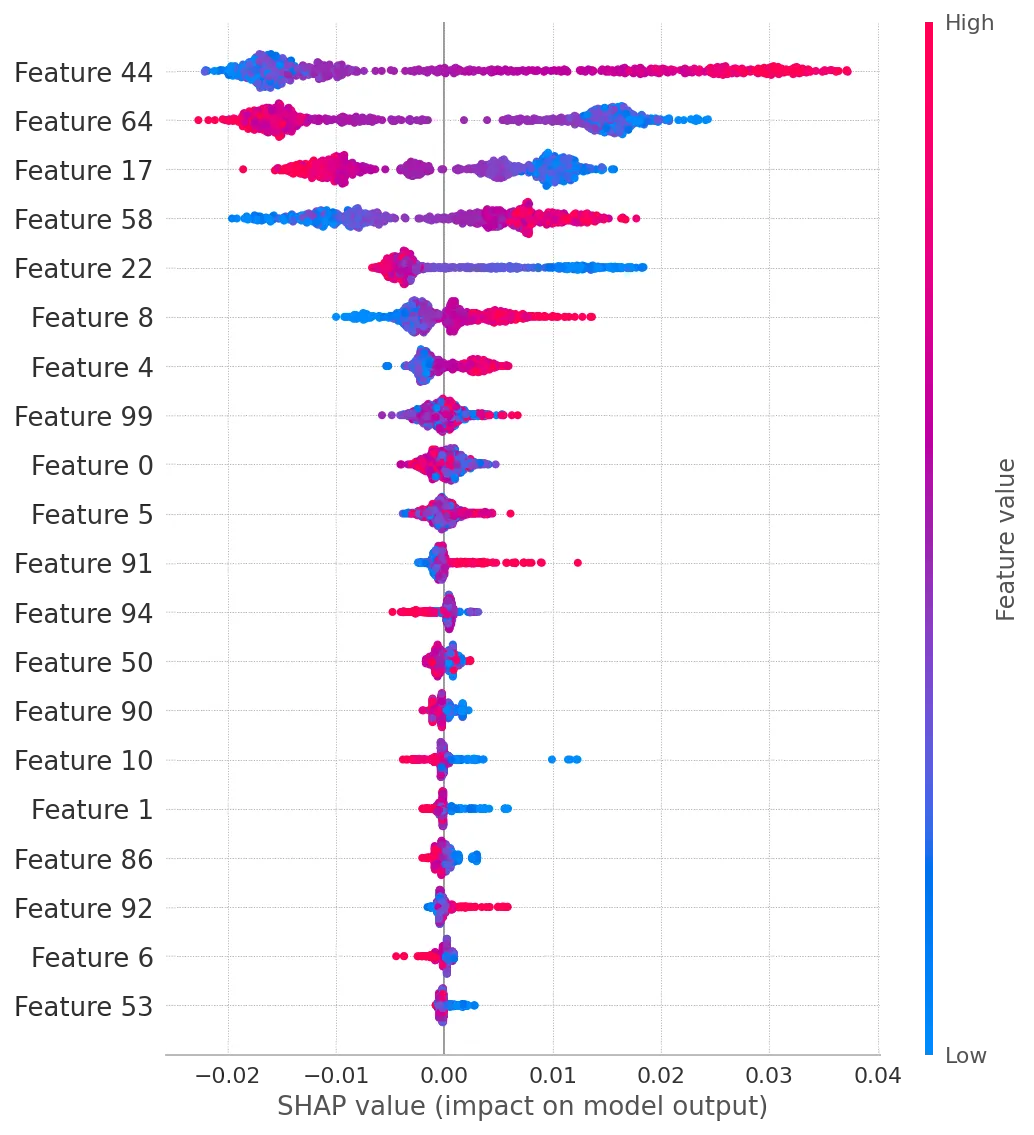
以下是解释:
- 基于SHAP贡献,对于第3类最具影响力的特征是44、64和17。
- 对于特征64和17,较低的值往往会导致较高的SHAP值(因此更高的类标签概率)。
- 在显示的20个特征中,特征92、6和53的影响最小。