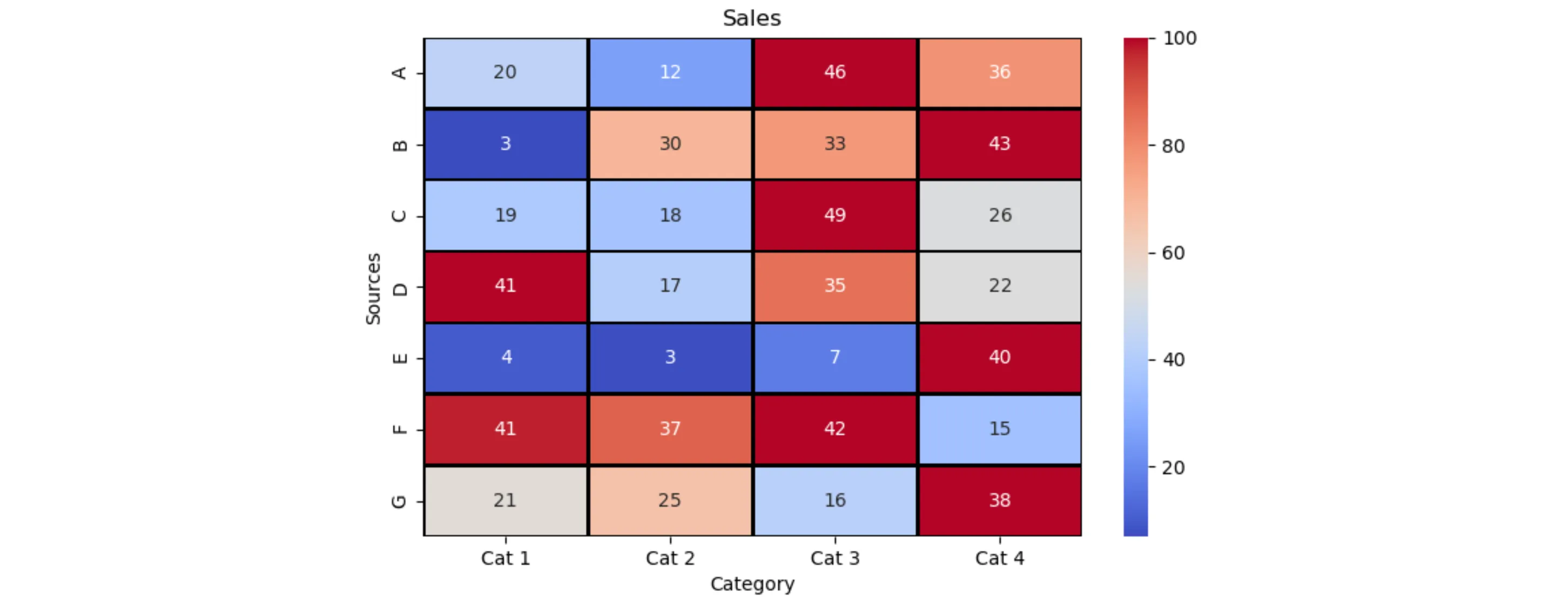
使用pandas将每行除以其最大值,我们可以得到一种颜色编码,其中最大值为深红色,其他列取决于它们与最大值的关系。因此,接近最大值的列将是较浅的红色。销售额仅有一半的列将被涂成白色。几乎没有销售额的列将会是蓝色。
颜色条指示了每行相对于最大值的百分比。
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
import random
sources = ['A', 'B', 'C', 'D', 'E', 'F', 'G']
categories = [f'Cat {i}' for i in range(1, 5)]
data = [[s, c, random.randint(2, 50)] for s in sources for c in categories]
sales = pd.DataFrame(data, columns=['Sources', 'Category', 'Value'])
per_source_cat = sales.groupby(['Sources', 'Category']).agg({'Value': 'sum'})
max_per_source = sales.groupby(['Sources']).agg({'Value': 'max'})
per_source_cat = per_source_cat.div(max_per_source, level='Sources') * 100
per_source_cat = per_source_cat.pivot_table(index='Sources', columns='Category', values='Value')
sales = sales.pivot_table(index='Sources', columns='Category', values='Value')
sns.heatmap(per_source_cat, cmap='coolwarm', annot=sales, fmt='g', linewidths=1, linecolor='black', ).set_title('Sales')
plt.show()
另外,假设您想将最高的颜色设置为红色,最低的颜色设置为蓝色,无论它们是否靠近。然后,通过减去最小值并除以最大值和最小值之间的差异,可以定义着色。完全相等的行会导致除以零,可以使用
fillna进行处理。
per_source_cat = sales.groupby(['Sources', 'Category']).agg({'Value': 'sum'})
max_per_source = sales.groupby(['Sources']).agg({'Value': 'max'})
min_per_source = sales.groupby(['Sources']).agg({'Value': 'min'})
per_source_cat = (per_source_cat - min_per_source) / (max_per_source - min_per_source) * 100
per_source_cat = per_source_cat.fillna(100.0)
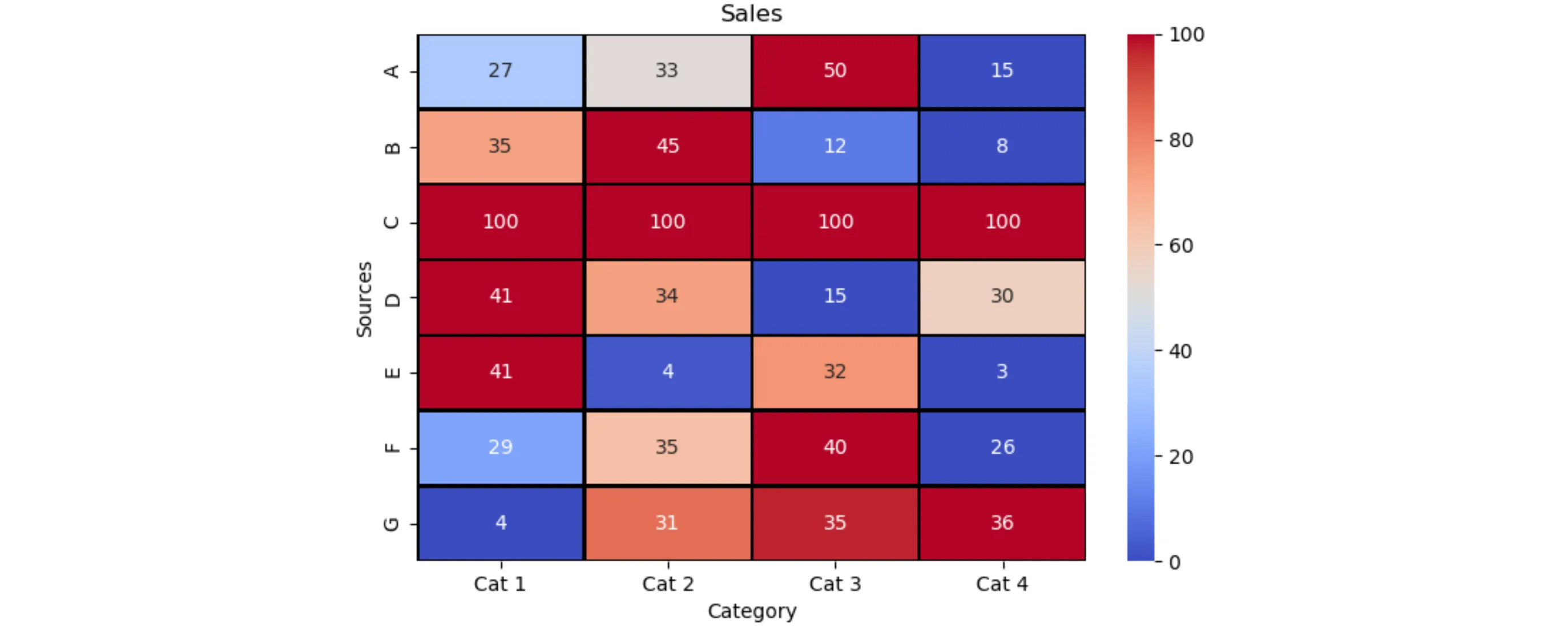
现在,色条指示最高为100%,最低为0%,其余按比例着色。